All 0 Likes
How the world caught up with Apache Cassandra
Table of Contents Want to learn more about DataStax Astra DB, built on Apache Cassandra? Sign up for a free demo.The O’Reilly book, Cassandra: The Definitive Guide, features a quote from Ray Kurzweil, the noted inventor and futurist: “An invention has to make sense ...
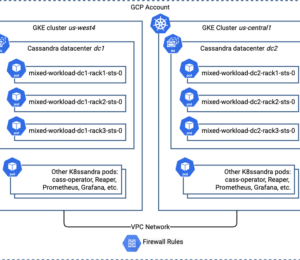
This is the second in a series of posts examining patterns for using K8ssandra to create Cassandra clusters with different deployment topologies.
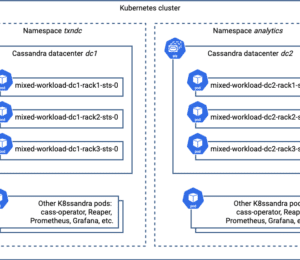
Today let’s examine different Kubernetes deployment patterns and show how to implement them using K8ssandra.

Table of Contents Databases on KubernetesPrinciple One: Leverage Compute, Network and Storage as Commodity APIsPrinciple Two: Separate the Control and Data PlanesPrinciple Three: Make Observability EasyPrinciple Four: Make the Default Configuration SecurePrinciple Five: Prefer Declarative ConfigurationDraw on the Wisdom of …

Table of Contents Implications of operators for project structureHow to test a Kubernetes operatorAutomating operator testingExpanding the K8ssandra communitySummaryIn the first, second, and third posts in this series, we’ve shared conversations with K8ssandra core team members on our journey to build a Kubernetes operator …

A Complimentary Live Webinar, Sponsored by DataStax Kubernetes made it easy to deploy and scale out your cloud-native applications. With K8ssandra, you can now scale application data with the same simplicity and high availability. Join us as we unbox K8ssandra a …
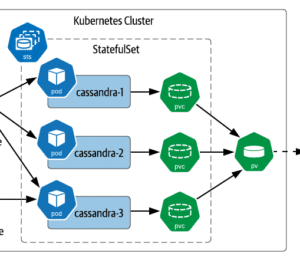
Learn the key steps of deploying databases and stateful workloads in Kubernetes and meet the cloud-native technologies.
Read all about how K8ssandra is an open source project with the mission of capturing SRE knowledge and best practices.
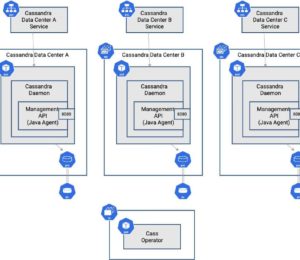
A cloud-native database is one that is designed with cloud-native principles in mind, including scalability, elasticity, resiliency, observability, and automation.
As we’ve seen with Cassandra, automation is often the final milestone to be achieved, but running databases in Kubernetes can actually help us progress toward this goal of automation.
What’s next in the maturation of cloud-native databases? We’d love to hear your input as we continue to invent the future of this technology together.

Must a database run on Kubernetes to be considered cloud-native?
While Kubernetes was originally designed for stateless workloads, recent improvements in Kubernetes such as StatefulSets and persistent volumes have made it possible to run stateful workloads as well. Even longtime DevOps practitioners skeptical of running databases on Kubernetes are beginning to come around, and best practices are starting to emerge.
If you want to know what I spoke about in @jcon_conference in Germany, here's an interview I did at the @foojayio podcast:
#Java #JCON #JakartaEE #AI #A2A
Our team loves to meet and talk with the Java community from around the world. If you want to learn more. You can find all OmniFish presentations at: https://speakerdeck.com/omnifish, including links to the source code of related demos. Or get in touch for a free consultation call.
Another happy customer :)
"Their expertise and flexible hands-on troubleshooting support accelerated resolution of several unexpected hurdles and ultimately got us to a successful upgrade outcome."
If you would like to discuss how we could help your company, get in touch.
All 1 Comments