

Why Kubernetes Is The Best Technology For Running A Cloud-Native Database
- June 30, 2021
- 5 min read
We’ve been talking about migrating workloads to the cloud for a long time, but a look at the application portfolios of many IT organizations demonstrates that there’s still a lot of work to be done. In many cases, challenges with persisting and moving data in clouds continue to be the key limiting factor slowing cloud adoption, despite the fact that databases in the cloud have been available for years.
For this reason, there has been a surge of recent interest in data infrastructure that is designed to take maximum advantage of the benefits that cloud computing provides. A cloud-native database is one that achieves the goals of scalability, elasticity, resiliency, observability, and automation; the K8ssandra project is a great example. It packages Apache Cassandra and supporting tools into a production-ready Kubernetes deployment.
This raises an interesting question: must a database run on Kubernetes to be considered cloud-native? While Kubernetes was originally designed for stateless workloads, recent improvements in Kubernetes such as StatefulSets and persistent volumes have made it possible to run stateful workloads as well. Even longtime DevOps practitioners skeptical of running databases on Kubernetes are beginning to come around, and best practices are starting to emerge.
But of course, grudging acceptance of running databases on Kubernetes is not our goal. If we’re not pushing for greater maturity in cloud-native databases, we’re missing a big opportunity. To make databases the most “cloud-native” they can be, we need to embrace everything that Kubernetes has to offer. A truly cloud-native approach means adopting key elements of the Kubernetes design paradigm. A cloud-native database must be one that can run effectively on Kubernetes.
Let’s explore a few Kubernetes design principles that point the way.
Principle 1: Leverage compute, network, and storage as commodity APIs
One of keys to the success of cloud computing is the commoditization of compute, networking, and storage as resources we can provision via simple APIs. Consider this sampling of AWS services:
- Compute: we allocate virtual machines through EC2 and Autoscaling Groups (ASGs)
- Network: we manage traffic using Elastic Load Balancers (ELB), Route 53, and VPC peering
- Storage: we persist data using options such as the Simple Storage Service (S3) for long-term object storage, or Elastic Block Storage (EBS) volumes for our compute instances.
Kubernetes offers its own APIs to provide similar services for a world of containerized applications:
- Compute: pods, deployments, and replica sets manage the scheduling and life cycle of containers on computing hardware
- Network: services and ingress expose a container’s networked interfaces
- Storage: persistent volumes and stateful sets enable flexible association of containers to storage
Kubernetes resources promote portability of applications across Kubernetes distributions and service providers. What does this mean for databases? They are simply applications that leverage compute, networking, and storage resources to provide the services of data persistence and retrieval:
- Compute: a database needs sufficient processing power to process incoming data and queries. Each database node is deployed as a pod and grouped in StatefulSets, enabling Kubernetes to manage scaling out and scaling in.
- Network: a database needs to expose interfaces for data and control. We can use Kubernetes Services and Ingress Controllers to expose these interfaces.
- Storage: a database uses persistent volumes of a specified storage class to store and retrieve data.
Thinking of databases in terms of their compute, network, and storage needs removes much of the complexity involved in deployment on Kubernetes.
Principle 2: Separate the control and data planes
Kubernetes promotes the separation of control and data planes. The Kubernetes API server is the key data plane interface used to request computing resources, while the control plane manages the details of mapping those requests onto an underlying IaaS platform.
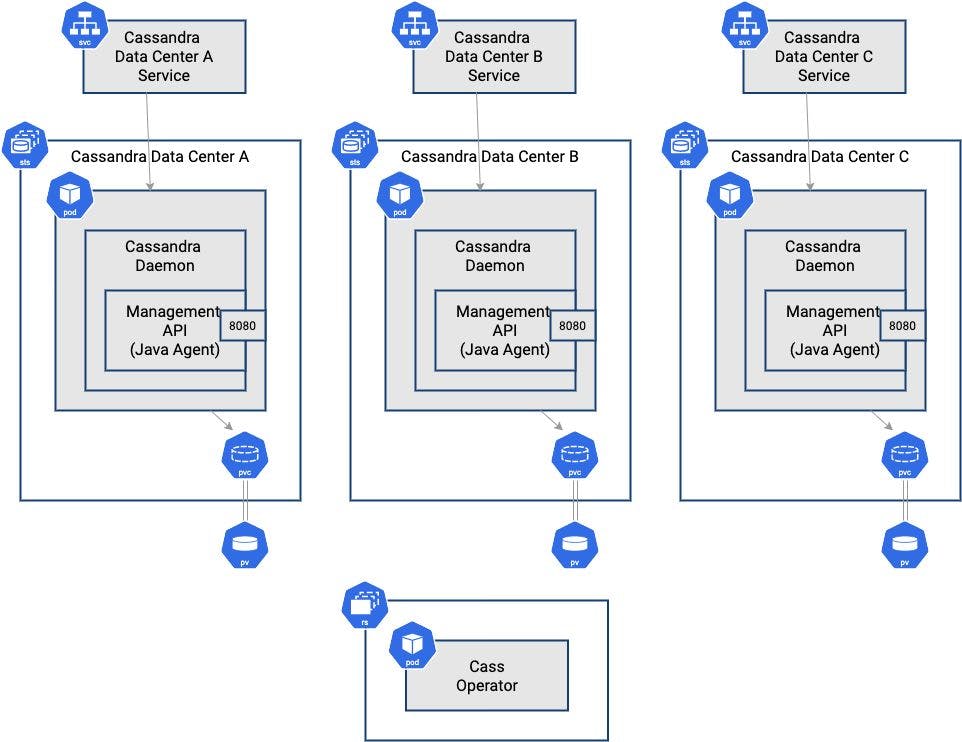
We can apply this same pattern to databases. For example, Cassandra’s data plane consists of the port exposed by each node for clients to access Cassandra Query Language (CQL) and the port used for internode communication. The control plane includes the Java Management Extensions (JMX) interface provided by each Cassandra node. Although JMX is a standard that’s showing its age and has had some security vulnerabilities, it's a relatively simple task to take a more cloud-native approach. In K8ssandra, Cassandra is deployed in a custom container image that adds a RESTful Management API, bypassing the JMX interface.
The remainder of the control plane consists of logic that leverages the Management API to manage Cassandra nodes. This is implemented via the Kubernetes operator pattern. Operators define custom resources and provide control loops that observe the state of those resources and take actions to move them toward a desired state, helping extend Kubernetes with domain-specific logic.
The K8ssandra project uses cass-operator to automate Cassandra operations. Cass-operator defines a “CassandraDatatcenter” custom resource (CRD) to represent each top-level failure domain of a Cassandra cluster. This builds a higher-level abstraction based on Stateful Sets and Persistent Volumes.
A sample K8ssandra deployment including Apache Cassandra and cass-operator:
Principle 3: Make observability easy
The three pillars of observable systems are logging, metrics, and tracing. Kubernetes provides a great starting point by exposing the logs of each container to third-party log aggregation solutions. Metrics and tracing require a bit more effort to implement, but there are multiple solutions available.
The K8ssandra project supports metrics collection using the kube-prometheus-stack. The Metrics Collector for Apache Cassandra (MCAC) is deployed as an agent on each Cassandra node, providing a dedicated metrics endpoint. A ServiceMonitor from the kube-prometheus-stack pulls metrics from each agent and stores them in Prometheus for use by Grafana or other visualization and analysis tools.
Principle 4: Make the default configuration secure
Kubernetes networking is secure by default: ports must be explicitly exposed in order to be accessed externally to a pod. This sets a useful precedent for database deployment, forcing us to think carefully about how each control plane and data plane interface will be exposed, and which interfaces should be exposed via a Kubernetes Service.
In Kassandra, CQL access is exposed as a service for each CassandraDatacenter resource, while APIs for management and metrics are accessed for individual Cassandra nodes by cass-operator and the Prometheus Service Monitor, respectively.
Kubernetes also provides facilities for secret management, including sharing encryption keys and configuring administrative accounts. K8ssandra deployments replace Cassandra’s default administrator account with a new administrator username and password.
Principle 5: Prefer declarative configuration
In the Kubernetes declarative approach, you specify the desired state of resources and controllers manipulate the underlying infrastructure in order to achieve that state. Cass-operator allows you to specify the desired number of nodes in a cluster, and manages the details of placing new nodes to scale up, and selecting which nodes to remove to scale down.
The next generation of operators should enable us to specify rules for stored data size, number of transactions per second, or both. Perhaps we’ll be able to specify maximum and minimum cluster sizes, and when to move less frequently used data to object storage.
The best designs draw on the wisdom of the community
Hopefully I’ve convinced you that Kubernetes is a great source of best practices for cloud-native database implementations, and the innovation continues. Solutions for federating Kubernetes clusters are still maturing, but will soon make it much simpler to manage multi-data center Cassandra clusters in Kubernetes. In the Cassandra community, we can work to make extensions for management and metrics a part of the core Apache project so that Cassandra is more naturally cloud-native for everyone, right out of the box.
If you’re excited at the prospect of cloud-native databases on Kubernetes, you’re not alone. A group of like-minded individuals and organizations has assembled as the Data on Kubernetes Community, which has hosted over 50 meetups in multiple languages since its inception last year. We’re grateful to MayaData for helping to start this community, and are excited to announce that DataStax has joined as a co-sponsor of the DoKC.
In more great news, the DoKC was accepted as an official CNCF community group, and hosted the first ever Data on Kubernetes Day as part of Kubecon/CloudNativeCon Europe on May 3. Rick Vasquez’s talk, “A Call for DBMS to Modernize on Kubernetes,” lays down a challenge to make the architectural changes required to become truly cloud native. Together, we’ll arrive at the best solutions through collaboration in open source communities like Kubernetes, Data on Kubernetes, Apache Cassandra, and K8ssandra. Let’s lead with code and keep talking!
- June 30, 2021
- 5 min read
Developer Relations @ DataStax






Comments (0)
No comments yet. Be the first.