


Defining patterns of data transfers for Java applications with TornadoVM
- August 15, 2024
- 4 min read
- a) Transferring input data in every execution
- b) Transferring input data only in the first execution
- c) Transferring output data under demand
The TornadoVM API is designed to aid Java programmers in adapting their code bases for hardware acceleration. As explained in a previous article, the TornadoVM API exposes two key Java objects for programmers, the TaskGraph and the TornadoExecutionPlan. The former is used to define which methods should be offloaded on an accelerator as well as how often the data will flow. The latter is used to configure how the execution will take place (e.g., with a warmup, with a specific grid, with a profiler, etc.) and contains a method that actually invokes the execution. More information about how to use those objects are provided here.
This article aims to present various patterns of defining the data transfers based on the diverse requirements of Java applications. For instance, some applications may need to transfer data to the accelerator every time that a computation is performed, while others may need to transfer them on demand. Additionally, some applications may need to process more data than the actual memory capacity of the accelerator.
Pattern 1. Data that fit into the GPU memory
The TornadoVM API exposes two methods to configure which data correspond to the input and the output of a TaskGraph. This is happening via the transferToDevice for the inputs and transferToHost for the outputs. Those methods accept an additional configuration which is the DataTransferMode.
a) Transferring input data in every execution
If you configure your TaskGraph to accept inputs in every execution, it will copy the new values of your variables (e.g., matrixA and matrixB) every time the TaskGraph is executed (i.e., executionPlan.execute()).
TaskGraph tg = new TaskGraph("s0")
.transferToDevice(DataTransferMode.EVERY_EXECUTION, matrixA, matrixB)
.task("t0", MxM::compute, context, matrixA, matrixB, matrixC, size)
.transferToHost(DataTransferMode.EVERY_EXECUTION, matrixC);
b) Transferring input data only in the first execution
If you configure your TaskGraph with the DataTransferMode.FIRST_EXECUTION, it will copy the input data only once during the first execution, indicating that they are read-only; so, your program will not modify the values of your variables (e.g., matrixA and matrixB) after the first execution (i.e., executionPlan.execute()).
TaskGraph tg = new TaskGraph("s0")
.transferToDevice(DataTransferMode.FIRST_EXECUTION, matrixA, matrixB)
.task("t0", MxM::compute, context, matrixA, matrixB, matrixC, size)
.transferToHost(DataTransferMode.EVERY_EXECUTION, matrixC);
c) Transferring output data under demand
Regardless, the configuration of the input data (a, b), you must also define the transferring mode for the outputs of your TaskGraph. Two modes are available: i) the transferring of the outputs after every execution; when the executionPlan.execute() is completed; and ii) the transferring of the outputs under demand.
TaskGraph tg = new TaskGraph("s0")
.transferToDevice(DataTransferMode.FIRST_EXECUTION, matrixA, matrixB)
.task("t0", MxM::compute, context, matrixA, matrixB, matrixC, size)
.transferToHost(DataTransferMode.UNDER_DEMAND, matrixC);
The under demand mode can be used if your program does not require the result of the processing to be transferred from the accelerator's memory after every execution. In this case, the programmer can obtain the result on demand by utilizing the TornadoExecutionResult object. This object is returned after every invocation of the execute() method to hold the result of each execution:
TornadoExecutionResult executionResult = executionPlan.execute(); executionResult.transferToHost(matrixC);
Note: The executionPlan.execute() is a blocking call that performs all the steps (see the screenshot from the Java editor) in the executionPlan as defined by the programmer.
Pattern 2. Data do not fit into the GPU memory
In this case, TornadoVM supports batch processing. This feature enables programmers that handle large data sizes (e.g. 20 GB) to configure the TornadoExecutionPlan in order to operate with the batch size (e.g. 512 MB), based on which all data will be split and streamed in the GPU memory to be processed. Note, the batch size should fit into the GPU memory.
The split and streaming is handled automatically by the TornadoVM runtime. Thus, the 20 GB of data will be split in chunks of 512 MB and will be sent for execution on the GPU.
ImmutableTaskGraph immutableTaskGraph = taskGraph.snapshot();
TornadoExecutionPlan plan = new TornadoExecutionPlan(immutableTaskGraph);
plan.withBatch("512MB") // Run in blocks of 512MB
Pattern 3. Transfer only a short range of the result from the GPU memory
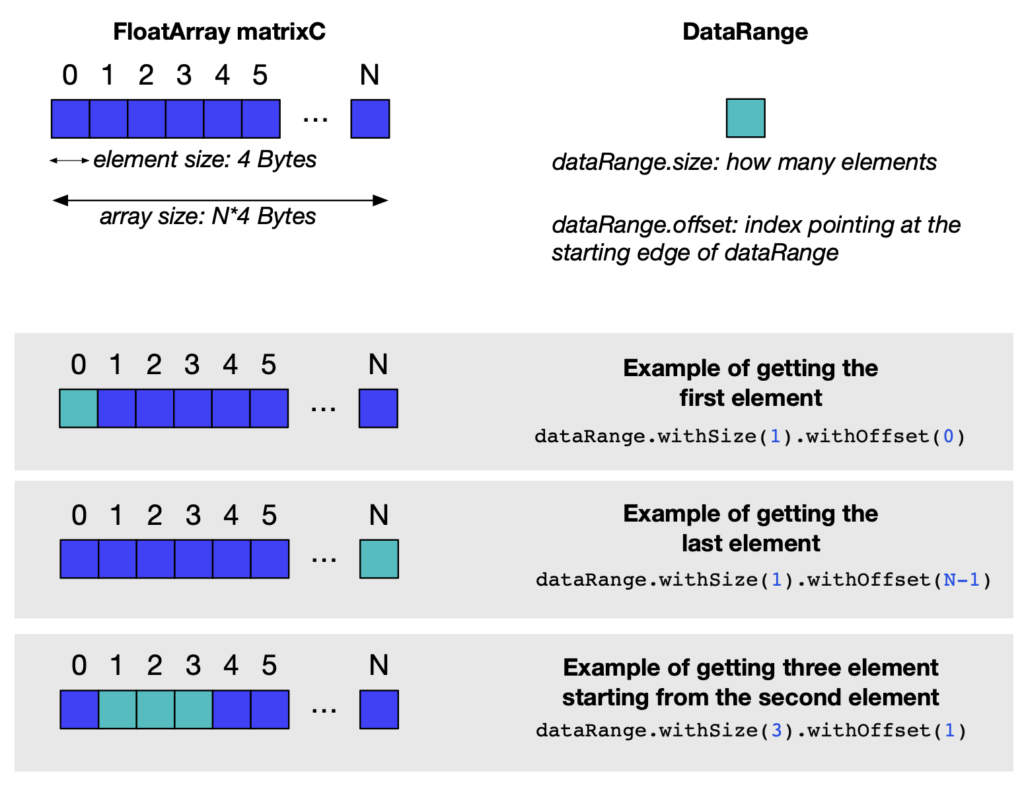
TornadoVM also supports the transferring of a small piece of the output data. This may be useful if your program operates on large arrays, and you are interested only at a partial segment of the output array. In this case, you can access a partial segment (e.g., just the first element of the array), as shown below (assuming that the data are defined to operate under demand, i.e., DataTransferMode.UNDER_DEMAND, as shown in Pattern 1-C).
TornadoExecutionResult executionResult = executionPlan.execute(); DataRange dataRange = new DataRange(matrixC); executionResult.transferToHost(dataRange.withSize(1).withOffset(0));
An example of this API call is shown in one of the TornadoVM unit-tests, here. Several variations of the above code snippet are shown in the following image.
Summary
This article aims to show how TornadoVM programmers can utilize the API functions for transferring data to the accelerator's (e.g., GPU) memory, and backwards, in the frequency of every execution, first execution or under demand.
Note that this blog shows the API functions as exist in the current version TornadoVM v1.0.7 (commit point: f1e670d).
Useful links
- TornadoVM documentation
- DataRange examples
- Batch processing examples
- August 15, 2024
- 4 min read
Research Fellow at The University of Manchester, TornadoVM Technology and Commercialisation












Comments (1)
Java Weekly, Issue 556 | Baeldung
2 years ago[…] >> Defining patterns of data transfers for Java applications with TornadoVM [foojay.io] […]