

Different Approaches to Building Stateful Microservices in the Cloud Native World
- January 04, 2022
- 10 min read
 Cloud Native computing is all about working with stateless data and serverless systems. But we all live in a stateful world, in which data flows through systems interconnected with one another through complex networks.
Cloud Native computing is all about working with stateless data and serverless systems. But we all live in a stateful world, in which data flows through systems interconnected with one another through complex networks.
So how can systems be able to manage and track the flow of data in a coherent fashion and in a stateless world?
Navigating the maze of cloud related terminologies
We will first iron out a few terminologies that some folks appear to be using almost interchangeably in the current cloud computing era:
Cloud Native Computing
First of all, let's take a look at the definition as published by the Cloud Native Computing Foundation:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
I'd like to think of cloud native as an "extension" to the fundamental building blocks of the cloud infrastructure. It is what gives "life" to an otherwise rather purely mechanical set of structures.
Serverless versus Serverful
Serverless are being referred to as stateless computing at times. What serverless computing refers to, is in essence the cloud computing execution model, in which the designated cloud infrastructural provider takes care of the dynamic allocation and management of the logistical resources for launching and running of the workload.
Concerns such as capacity planning, container management, maintenance, fault tolerance, scaling, and so on, which once used to occupy so much of the developer's time, can no longer hold developers hostage. Despite the misnomer, we need to be mindful of the fact that serverless computing still use servers, and serverless is still evolving and by no means has it completely offloaded the busy developers.
On the other hand, even though there is not an official term called serverful computing, we should be well aware that the opposite of serverless would be serverful, in which the control and management of the infrastructural systems resources are all in the hands of the developers
Stateless versus Stateful
Stateless and stateful computing refer to the two opposing communication protocols in terms of whether or not data is being captured or retained as it flows through a system, or an ecosystem consists of one or more sub-systems.
If I have to describe these two opposing concepts to someone new to this aspect of computing, I would use a crude analogy of the animated film story of Finding Nemo. As the story goes, Nemo, the little orange clownfish, and his dad, Marlin, are separated. Marlin becomes distressed and goes searching for his son. Marlin then bumps into a blue tang fish named Dory who is experiencing an acute short-term memory loss.
It is the interaction between Marlin and Dory that we can borrow to contrast and understand stateful and stateless computing. Dory does not remember anything and cannot make the connection between any events that have happened. She represents stateless computing as she retains nothing in her memory. But, we can see too, her happy-go-lucky behavior also implies the lack of burden, and that is exactly what stateless computing is like: lightweight, efficient, and performant.
Whereas, with stateful computing, everything is heavier, because we will need to record essentially everything as the data flows through the system, including its change in state, and in the case of a highly distributed ecosystem - which is pretty much what most systems are these days - we will also need to ensure the integrity of the data itself as it relates to the data in other parts of the system.
As a result of all of these concerns, stateful systems are less performant, heavier, and can become very complex.
Stateful Computing in the Client-Server era
Two-Phase Commit Protocol (2PC)
Let us travel a bit back in time to understand how stateful computing has evolved. Back in the client-server days in the 90's, databases as well as certain file systems came with transaction processing support. Transaction processing essentially ensures that interdependent operations on the system either all complete successfully (commit) or get cancelled (rollback) successfully.
A typical 'monolith' type of system would not have to worry about managing its transactions, since all of the components and sub-systems are being hosted in the same host machine, with a single database managing all of its data. However, as processing has become more complicated, especially in cases when multiple databases are being used, we will also need a distributed algorithm to help coordinate all of the inter-dependent processes, and to ensure integrity in all distribution atomic transactions. Two-phase commit, or 2PC, is the answer for it.
As the name implies, 2PC essentially consists of 2 phases:
-
The commit-request phase:
- The coordinator collects the "votes" from all of the participating processes that would each indicate either a commit (for successful execution) or an abort (for failed execution) outcome;
-
The commit phase:
- The coordinator, after collecting all of the "votes", determines if a commit or an abort should be performed, and notifies each of the participating processes of the decision. The participating processes then perform the needed action (either a commit or a abort/rollback) on its local resource accordingly.
The biggest drawback of the 2PC protocol is that it is a blocking protocol. All participating processes depend on the coordinator for instructions on what to do next, and the coordinator can only handle one process at a time. If a failure occurs during any of the 2 phases, all participating processes would be held up waiting for the coordinator to resume processing.
Enterprise and Web Java Applications
In the pre-Jakarta EE days, Java EE has stateful session as well as entity Enterprise Java Beans (EJBs), as well as the Java Transaction API (JTA) for implementing stateful services for a typical enterprise application.
For web applications, JSPs and servlets rely on HTTPSession for keeping the state of data within each session.
Client-side Caching of Server Responses
HTTP cookies generated from the web server are being cached on the client-side web browser, and can be used for authenticating and/or tracking the returning client.
JSON Web Token (JWT) offers a compact and self-contained way to securely transmit messages as JSON object between the client and the server.
Cloud Native and the Twelve-Factor App
The 12-Factor App methodology from Heroku provides a set of guidelines for designing cloud native systems.

As we can see, #6 and #9 epitomize the need for highly efficient and very lightweight, stateless processes.
Hence, the question now becomes...
How can stateless microservices handle stateful workload?
While microservices themselves are implemented as stateless containers, they can still utilize the operations and services outside of the containers to perform any stateful tasks.
Techniques and Mechanisms
The following are the techniques and mechanisms which we have already discussed in the earlier part of this article, namely:
- Cookies
- Tokens
- Sessions
- Caches
- Database Transactions
Cloud Native Infrastructure
Kubernetes is the de facto container orchestrator in the current cloud computing era. In a short span of roughly 7 years since its debut, it has taken the world by storm. In its early days, it supported only stateless workloads with containers that had no persistent storage or volume. From an operational point of view, re-starting a pod was simpler then, as there was no need to initialize it to the same state as other pods running within the same node inside the same cluster. However, not all workloads are meant to be stateless.
Leader Election
Some of the workloads do not run effectively without state, such as a database cluster that's managed by several Zookeeper instances. Each database instance needs to be aware of the Zookeeper instances that are controlling it. Likewise, the Zookeeper instances themselves establish connections between each other to elect a primary/master node. Such a database cluster is an example of a stateful workload. If we deploy Zookeeper on Kubernetes, we'll need to ensure that pods can reach other through a unique identity that does not change (e.g hostnames, IPs, etc). Other examples of stateful applications are Kafka, Redis, MongoDB, MySQL clusters, and so on.
Since Kubernetes is backed by etcd, and etcd implements a consistent consensus protocol (raft), we can leverage Kubernetes primitives to perform leader election if we aren't using an external election tool such as Zookeeper. Having a good election algorithm is crucial especially for use cases in which we only allow one service instance to perform any updates on our customer information or submit a credit card payment.
StatefulSets
StatefulSet is the workload API object used to manage stateful applications in Kubernetes.
It manages the deployment and scaling of a set of Pods, and provides guarantees about the ordering and uniqueness of these Pods.
StatefulSets are used for building stateful distributed workloads by providing a few key features:
- a unique index for each pod
- ordered pod creation
- stable network identities
Together, these three features guarantee the ordering and uniqueness of the pods that make up our service. These guarantees are preserved across pod restarts and any rescheduling within the cluster, allowing us to run applications that require shared knowledge of cluster membership.
Session Affinity
Session affinity, sometimes referred to as sticky cookies/sessions, associates all requests coming from an end-user with a single pod. This means that all traffic from a client to a pod will be — to the greatest extent possible — directed to the same pod.
PersistentVolume / PersistentVolumeClaim
The PersistentVolume subsystem provides an API for developers and infrastructure administrators that abstracts details of how storage is provided apart from how it is consumed.
From the Kubernetes Conceptual guide on Persistent Volumes:
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes. It is a resource in the cluster just like a node is a cluster resource. PVs are volume plugins like Volumes, but have a lifecycle independent of any individual Pod that uses the PV. This API object captures the details of the implementation of the storage, be that NFS, iSCSI, or a cloud-provider-specific storage system.
A PersistentVolumeClaim (PVC) is a request for storage by a user. It is similar to a Pod. Pods consume node resources and PVCs consume PV resources. Pods can request specific levels of resources (CPU and Memory). Claims can request specific size and access modes (e.g., they can be mounted ReadWriteOnce, ReadOnlyMany or ReadWriteMany, see AccessModes).
Cloud Native Application Programming Design Pattern(s)
As developers, we get excited when it comes to programming design patterns. For designing stateful microservices, the Saga pattern is the replacement for the two-phase commit protocol.
While it is not impossible to use the 2PC protocol for handling distributed transactions in microservices, it is not the right tool for the job due to its blocking nature, which leads to issues such as:
- when one microservice fails in the commit phase, there is no mechanism for the other microservices to perform the rollbacks
- other microservices must wait until the slowest microservice finishes its confirmation, resulting in having all resources being put on hold in a locked state until the transaction completes
- overall, this is a slow protocol with a lack of agility, and the total dependence on a single coordinator, which would not work in a cloud native environment at all
The Saga Pattern
Saga pattern is a more efficient design pattern in managing business transactions which span multiple services. It is the pattern of choice for managing distributed transactions across container, cluster, server, and network boundaries. Its strength lies in its flexibility of having 2 forms of coordination sagas: choreography and orchestration.
Choreography Saga
This form of the pattern uses an event-driven approach, in which the local transaction within a microservice publishes a domain event that will trigger local transaction(s) in another microservices. It is essentially a self-driven mechanism that does not rely on any 'middleperson' at all.
An simplified example design of an order processing system illustrating the concept of the choreography pattern:
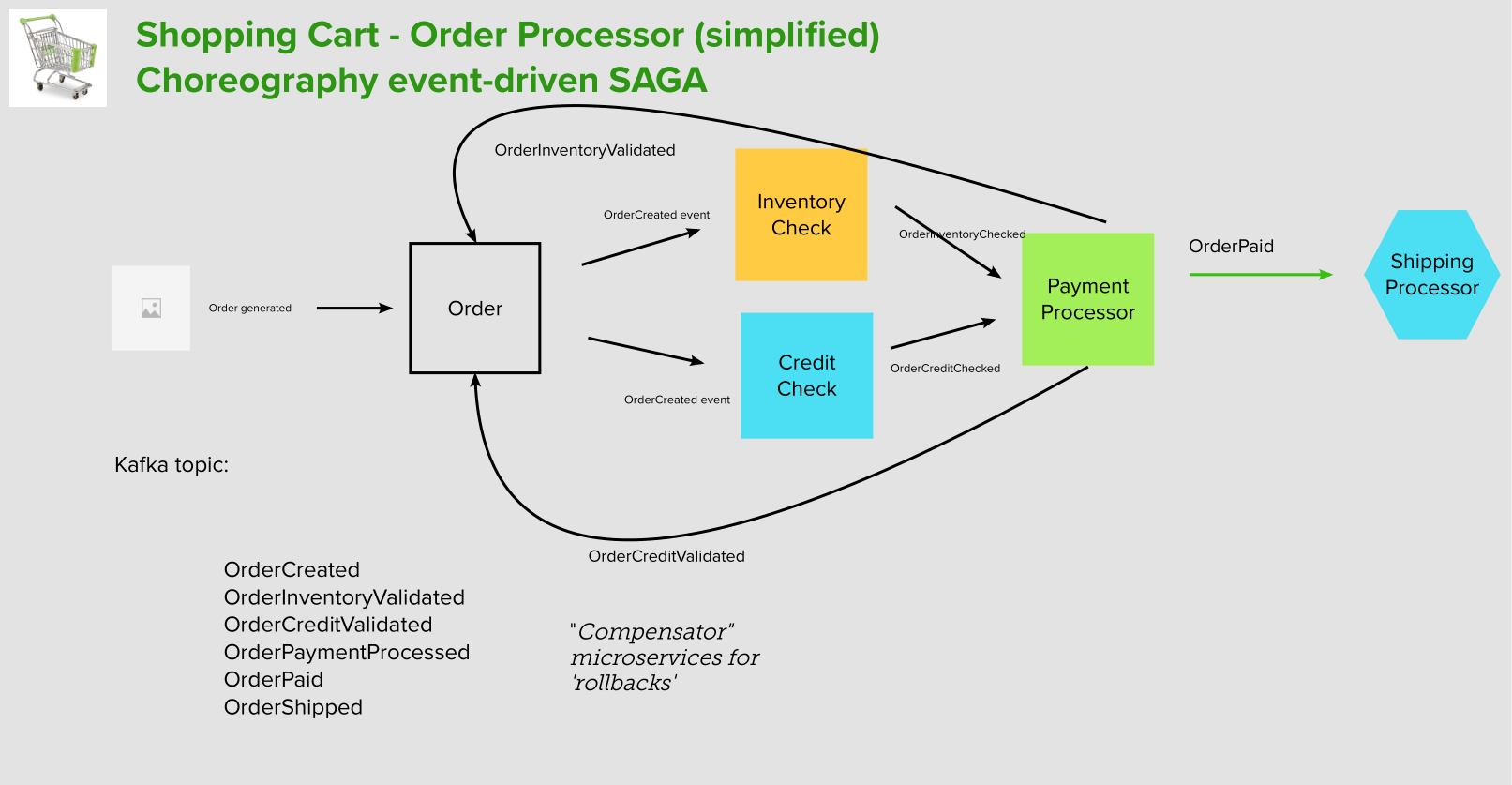
- An order gets generated when Kafka publishes an event to the topic, of which the Order microservice is a listener.
- Upon creating the order entry into the database, the Order microservice generates an OrderCreated event of which the InventoryCheck and the CreditCheck microservices are the subscribers.
- The InventoryCheck microservice gets busy and parses the order details, and checks with the warehouse to make sure that the order items are in stock
- The CreditCheck microservice also gets busy and obtains the security-protected credential and account info of the customer, and performs a check with the external Payment Verification system to ensure that the customer is in good standing with sufficient funds to make the purchase.
- Assuming that all goes well in the previous 2 sub-steps:
- The InventoryCheck microservice sends back an updated OrderInventoryValidated status to the Order microservice
- The CreditCheck microservice sends back an updated OrderCreditValidated status to the Order microservice
- The InventoryCheck microservice publishes an OrderInventoryChecked event of which the PaymentProcessor microservice is a subscriber
- The CreditCheck microservices publishes an OrderCreditChecked event of which the PaymentProcessor microservice is a subscriber
- Only after the PaymentProcessor microservice receives positive notifications of the OrderInventoryChecked and the OrderCreditChecked events, it will begin processing the payment by communicating and working with the external Payment Processor
- Upon receiving the response back from the external Payment Processor with a successful paid status, the PaymentProcessor microservice publishes an OrderPaid event, which will then be picked up by the ShippingProcessor microservice to start preparing the order items for shipment.
Orchestration Saga
The orchestration saga relies on the orchestrator to tell the relevant microservices to start their local transactions accordingly.
Chris Richardson has a great blog post that explains the choreography vs orchestration patterns with examples.
No rollbacks but undo's
The Saga pattern does not have the same concept as a traditional database transaction when any failure occurs and a rollback needs to happen. If a local transaction fails because it violates a business rule then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.
MicroProfile LRA and Open Liberty
The MicroProfile Long Running Action 1.0 (LRA), an Eclipse Foundation project, was released in April of 2021. The model it uses to support long-running distributed transaction, the Long Running Action model, is based on the Saga Interaction Pattern.
Open Liberty implements MicroProfile LRA by way of a transaction manager that acts as a coordinator. This coordinator handles one or more participant services so that the execution of their business logic is organized in a predictable way.
Closing thoughts
Stateful workload processing is certainly not for the faint of heart, especially in the present cloud computing era. There can be a multitude of moving parts within a distributed ecosystem that are constantly updating the state of the data, and our job is to not only keep track of the state changes, but also ensure the integrity of the data as it flows through the ecosystem in the infrastructural and the application systems layers.
I am looking forward to seeing more references as well as real-world implementations of these stateful applications that will make full use of the Kubernetes features such as StatefulSets and PersistentVolumes in their deployments, while the applications themselves will be implemented using the Saga Pattern.
- January 04, 2022
- 10 min read
Mary is a Java Champion, and the AI Practice Lead at Callibrity, a consulting firm based in Ohio. She started as an engineer in Unix/C, then transitioned to Java around 2000 and has never looked back since then. After 20+ years of being a software engineer and technical architect, she discovered her true passion in developer and customer advocacy. Most recently she has serviced companies of various sizes such as IBM, US Cellular, Bank of America, Chicago Mercantile Exchange, in topic areas that included Java, GenAI, Streaming systems, Open source, Cloud and Distributed messaging systems. She is also a very active tech community leader outside of her day job. She is the President of the Chicago Java Users Group (CJUG), and the Chicago Chapter Co-Lead for AICamp.









Comments (0)
No comments yet. Be the first.