

A Tentative Comparison of Fault Tolerance Libraries on the JVM
- January 11, 2022
- 4 min read
If you're implementing microservices or not, chances are that you're calling HTTP endpoints. With HTTP calls, a lot of things can go wrong.
Experienced developers plan for this and design beyond just the happy path. In general, fault tolerance encompasses the following features:
- Retry
- Timeout
- Circuit Breaker
- Fallback
- Rate Limiter to avoid server-side 429 responses
- Bulkhead: Rate Limiter limits the number of calls in a determined timeframe, while Bulkhead limits the number of concurrent calls
A couple of libraries implement these features on the JVM. In this post, we will look at Microprofile Fault Tolerance, Failsafe and Resilience4J.
Microprofile Fault Tolerance
Microprofile Fault Tolerance comes from the Microprofile umbrella project. It differs from the two others because it's a specification, which relies on a runtime to provide its capabilities. For example, Open Liberty is one such runtime. SmallRye Fault Tolerance is another one. In turn, other components such as Quarkus and WildFly embed SmallRye.
Microprofile defines annotations for each feature: @Timeout, @Retry Policy, @Fallback, @Circuit Breaker, and @Bulkhead. It also defines @Asynchronous.
Because the runtime reads annotations, one should carefully read the documentation to understand how they interact if more than one is set.
A
@Fallbackcan be specified and it will be invoked if theTimeoutExceptionis thrown. If@Timeoutis used together with@Retry, theTimoutExceptionwill trigger the retry. When@Timeoutis used with@CircuitBreakerand if aTimeoutExceptionoccurs, the failure will contribute towards the circuit open.
Resilience4J
I came upon Resilience4J when I was running my talk on the Circuit Breaker pattern. The talk included a demo, and it relied on Hystrix. One day, I wanted to update the demo to the latest Hystrix version and noticed that maintainers had deprecated it in favor of Resilience4J.
Resilience4J is based on several core concepts:
- One JAR per fault tolerance feature, with additional JARs for specific integrations, e.g., Kotlin
- Static factories
- Function composition via the Decorator pattern applied to functions
- Integration with Java's functional interfaces, e.g.,
Runnable,Callable,Function, etc. - Exception propagation: one can use a functional interface that throws, and the library will propagate it across the call pipeline
Here's a simplified class diagram for Retry.
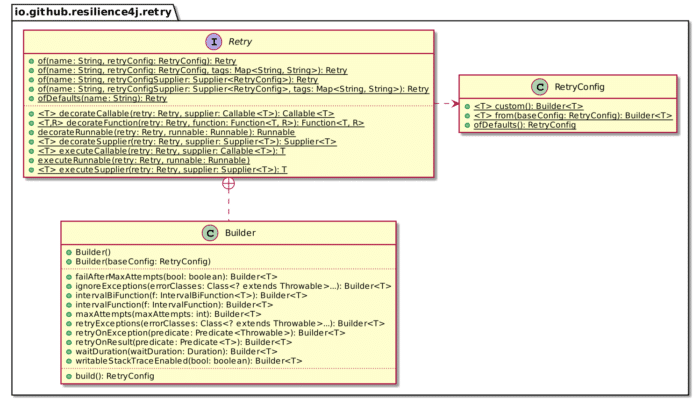
Each fault tolerance feature is built around the same template seen above. One can create a pipeline of several features by leveraging function composition, each one calling another one.
Let's analyze a sample:
var retrySupplier = Retry.decorateSupplier( // 1
Retry.ofDefaults("retry"), // 2
() -> server.call() // 1
);
var config = new CircuitBreakerConfig.Builder() // 3
.slowCallDurationThreshold(Duration.ofMillis(200)) // 4
.slidingWindowSize(2) // 5
.minimumNumberOfCalls(2) // 6
.build();
var breakerSupplier = CircuitBreaker.of("circuit-breaker", config) // 7
.decorateSupplier(retrySupplier); // 7
supplier = SupplierUtils.recover( // 8
breakerSupplier,
List.of(IllegalStateException.class, CallNotPermittedException.class), // 9
e -> "fallback" // 10
);
- Decorate the base
server.call()function withRetry: this function is the one to be protected - Use the default configuration
- Create a new Circuit Breaker config
- Set the threshold above which a call is considered to be slow
- Count over a sliding window of 2 calls
- Minimum number of calls to decide whether to open the Circuit Breaker
- Decorate the retry function with a Circuit Breaker with the above config
- Create a fallback value to return when the Circuit Breaker is open
- List of exceptions to handle: they won't be propagated. Resilience4J throws a
CallNotPermittedExceptionwhen the circuit is open. - In case any of the configured exceptions are thrown, call this function instead
The order in which functions are composed can be hard to decipher. Hence, the project offers the Decorators class to combine functions using a fluent API. You can find it in the resilience4j-all module. One can rewrite the above code as:
var pipeline = Decorators.ofSupplier(() -> server.call())
.withRetry(Retry.ofDefaults("retry"))
.withCircuitBreaker(CircuitBreaker.of("circuit-breaker", config))
.withFallback(
List.of(IllegalStateException.class, CallNotPermittedException.class),
e -> "fallback"
);
It makes the intent much clearer.
Failsafe
I stumbled upon Failsafe not long ago. Its tenets are similar to Resilience4J: static factories, function composition, and exception propagation.
While Resilience4J fault tolerance feature don't share a class hierarchy, Failsafe provides the concept of Policy:
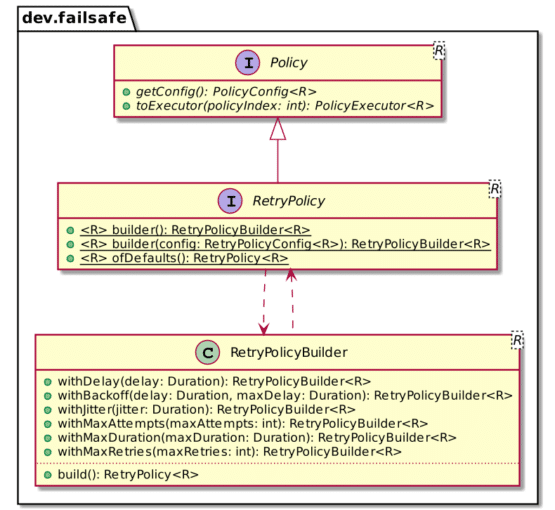
I believe the main difference with Resilience4J lies in its pipelining approach. Resilience4J's API requires you first to provide the "base" function and then embed it inside any wrapper function. You cannot reuse the pipeline on top of different base functions. Failsafe allows it via the FailsafeExecutor class.
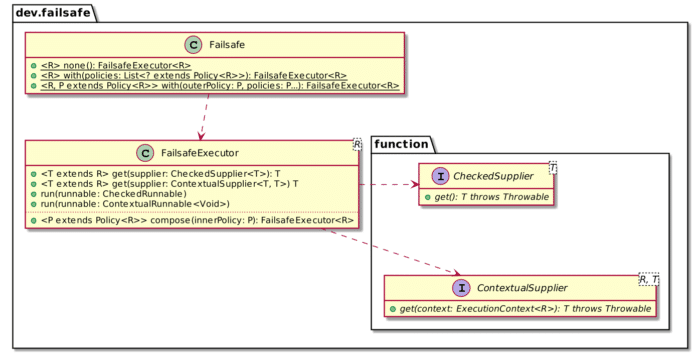
Here's how to create a pipeline, i.e., an instance of FailsafeExecutor.
Notice there's no reference to the base call:
var pipeline = Failsafe.with( // 1
Fallback.of("fallback"), // 2
Timeout.ofDuration(Duration.of(2000, MILLIS)), // 3
RetryPolicy.ofDefault() // 4
);
- Define the list of policies applied from the last to the first in order
- Fallback value
- If the call exceeds 2000ms, throws a
TimeoutExceededException - Default retry policy
At this point, it's possible to wrap the call:
pipeline.get(() -> server.call());
Failsafe also provides a fluent API. One can rewrite the above code as:
var pipeline = Failsafe.with(Fallback.of("fallback"))
.compose(RetryPolicy.ofDefault())
.compose(Timeout.ofDuration(Duration.of(2000, MILLIS)));
Conclusion
All three libraries provide more or less the same features. If you don't use a CDI-compliant runtime such like regular application server or Quarkus, forget about Microprofile Fault Tolerance.
Failsafe and Resilience4J are both based on function composition and are pretty similar. If you need to define your function pipeline independently of the base call, prefer Failsafe. Otherwise, pick any of them.
As I'm more familiar with Resilience4J, I'll probably use Failsafe in my next project to get more experience with it.
To go further:
- Microprofile Fault Tolerance specification
- SmallRye Fault Tolerance Documentation
- Introduction to Resilience4J
- Failsafe overview
Originally published at A Java Geek on January 7th, 2022
- January 11, 2022
- 4 min read
Technologist focusing on cloud-native technologies, DevOps, CI/CD pipelines, and system observability. His focus revolves around creating technical content, delivering talks, and engaging with developer communities to promote the adoption of modern software practices. With a strong background in software, he has worked extensively with the JVM, applying his expertise across various industries. In addition to his technical work, he is the author of several books and regularly shares insights through his blog and open-source contributions.











Comments (0)
No comments yet. Be the first.