

The High Availability Features of Microservices using Chronicle Services
- April 25, 2024
- 3 min read
In low-latency microservices, ensuring system resilience without compromising performance is vital.
This article explores how Chronicle Services, a Java-based framework optimised for low-latency microservices, meets these critical requirements by integrating HA, performance, and data persistence.
Stateful and Stateless Services
A Chronicle Service application consists of a number of processing units known as Services, which interact with each other using events posted on Chronicle Queues. The Chronicle Queue is an extremely fast shared memory inter-process communication; it also has an enterprise version that facilitates replication of queues over the network.
Services can be stateless or stateful; however, the framework’s real strength lies in facilitating stateful service integration without resorting to database dependencies, which are often unsuitable for low-latency requirements.
Below is an example of a ‘stateful’ service, which requires internal state in order to be able to handle a request. In this example of a Transaction Service, the ‘balance’ in the account would be the state, which needs to be maintained in order to process the incoming requests, and then update the balance.
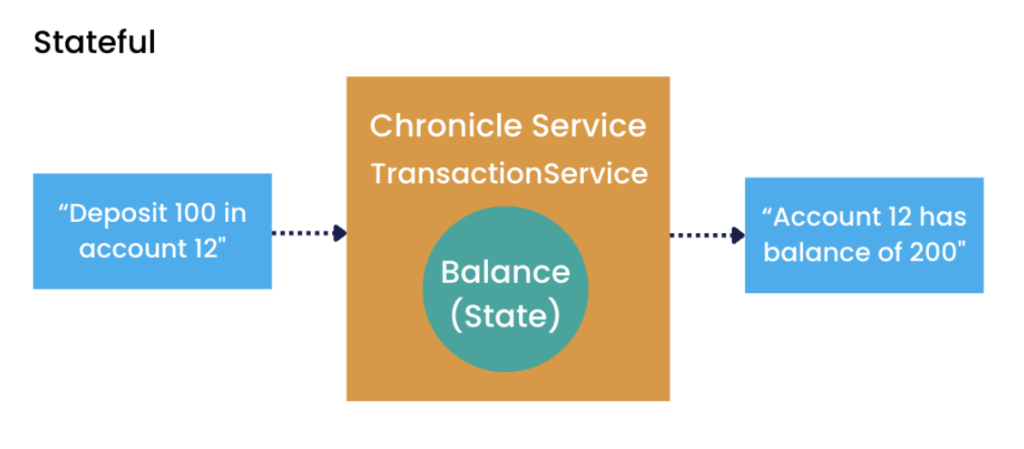
Diagram 1: Example of a stateful service
In the case of a ‘stateless’ service, state is not required for the service to handle a request. A simple example would be a service that sums up two numbers and outputs the result, as seen below.
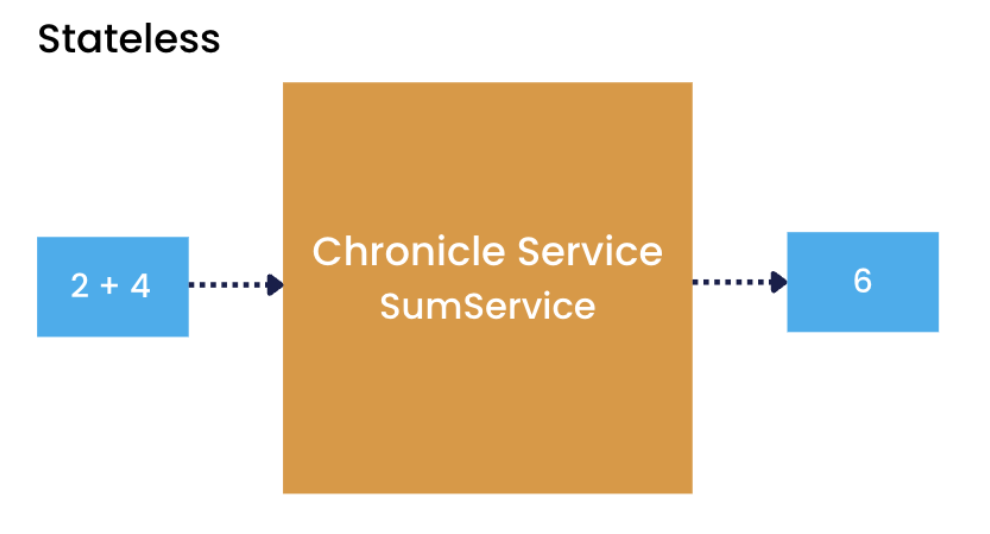
Diagram 2: Example of a stateless service
Persistence in Chronicle Services Applications
Service-to-service interactions in Chronicle Services applications is facilitated by Chronicle Queue, a persistent shared memory-based model for inter-process communication. Chronicle Services utilises Chronicle Queue to provide a “store everything” model, optionally interleaved with periodic checkpointing, ensuring comprehensive logging of all system activities and state modifications.
Chronicle Queue can persist approximately 1 million messages per second, combining efficiency with high throughput.
In the event of an outage, services are able to precisely reconstruct their state by replaying operations from either the input or output persistent queues. Services are thus able to resume precisely from the point of disruption. Data loss is mitigated by adding minimal latency—a few microseconds per message to the queue.
Queue Replication for High Availability
Chronicle’s High Availability solution is based on replicating the Chronicle Queue instances used to transport messages between services. Suppose a queue instance has been configured to be replicated. In that case, Chronicle Queue Replication copies messages as they are added to a queue to one or more replica queue instances, which may be on different hosts, using Chronicle’s high speed TCP/IP library.
If there is an issue either with the service or a queue, then it can be restarted, or “failed over”, to an instance on a different host where replicas of its required queues exist. As mentioned above, the service will be able to recreate any required state by replaying events from the replica queues, which will contain all of the events that have been duplicated from the primary queue.
Chronicle Queue Replication operates in the context of a cluster of hosts. Within the cluster, one host is set to host the Primary queue instance, sometimes referred to as the source or leader queue, and the others host Secondary queues, sometimes referred to as sink or follower queues. A service will read and post messages only from/to the source queue.
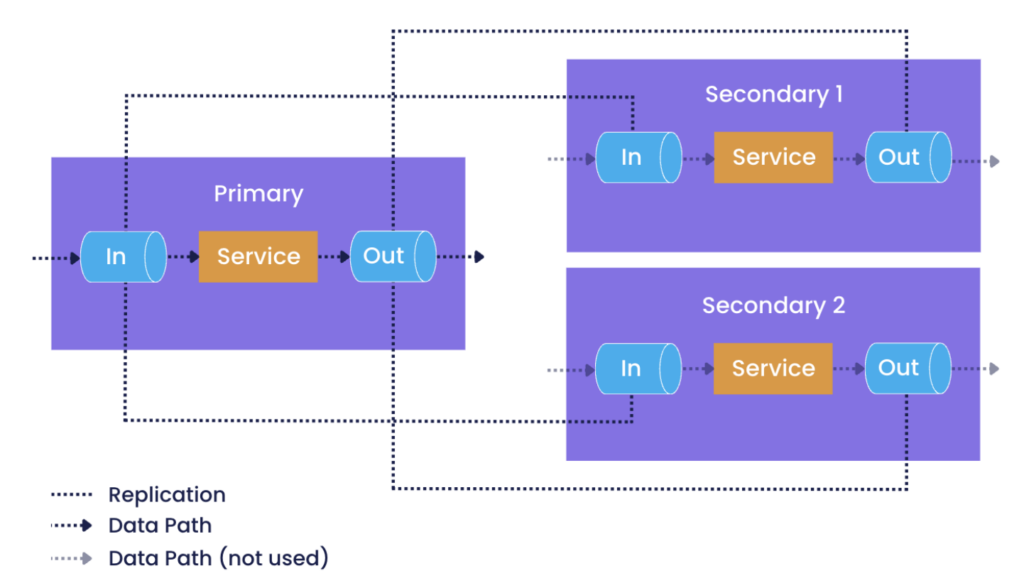
Diagram 3: Queue Replication
An optional acknowledgement mechanism ensures events are received and stored by at least one secondary host before the replication is deemed successful, thus preventing data loss in the event of a host failure.
Optimising Latency and Reliability
While acknowledgement mechanisms over the network are essential for maintaining data integrity, they naturally incur latency. Chronicle Services mitigates this effect by supporting “in-flight” messages—those that have been dispatched but not yet acknowledged.
If enabled, this improves overall latency, balancing performance with looser high availability constraints.
Conclusion
Chronicle Services focuses on resilient, low-latency microservices, efficiently managing stateful and stateless models. It eliminates dependencies on databases for managing service state, using Chronicle Queue for fast data replication and recovery.
Revenue Intelligence for Dev-Focused Companies
Reo.Dev analyzes developer activity across 20+ sources to identify high-intent accounts and key contacts ready to buy.
See How Reo.Dev Works!
- April 25, 2024
- 3 min read
As a Java developer with more than 20 years of experience, primarily on trading systems for investment banks, he has mostly focused on performance-critical pricing systems. As one of the first employees at Chronicle Software, he has been instrumental in building up its suite of software libraries.






Comments (0)
No comments yet. Be the first.