

Calling Gemma with Ollama, TestContainers, and LangChain4j
- April 12, 2024
- 3 min read
Lately, for my Generative AI powered Java apps, I've used the Gemini multimodal large language model from Google. But there's also Gemma, its little sister model.
Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models.
Gemma is available in two sizes: 2B and 7B. Its weights are freely available, and its small size means you can run it on your own, even on your laptop. So I was curious to give it a run with LangChain4j.
How to run Gemma
There are many ways to run Gemma: in the cloud, via Vertex AI with a click of a button, or GKE with some GPUs, but you can also run it locally with Jlama or Gemma.cpp.
Another good option is to run Gemma with Ollama, a tool that you install on your machine, and which lets you run small models, like Llama 2, Mistral, and many others. They quickly added support for Gemma as well.
Once installed locally, you can run:
ollama run gemma:2b ollama run gemma:7b
Cherry on the cake, the [LangChain4j]() library provides an Ollama module, so you can plug Ollama supported models in your Java applications easily.
Containerization
After a great discussion with my colleague Dan Dobrin who had worked with Ollama and TestContainers (#1 and #2) in his serverless production readiness workshop, I decided to try the approach below.
Which brings us to the last piece of the puzzle: Instead of having to install and run Ollama on my computer, I decided to use Ollama within a container, handled by TestContainers.
TestContainers is not only useful for testing, but you can also use it for driving containers. There's even a specific OllamaContainer you can take advantage of!
So here's the whole picture:
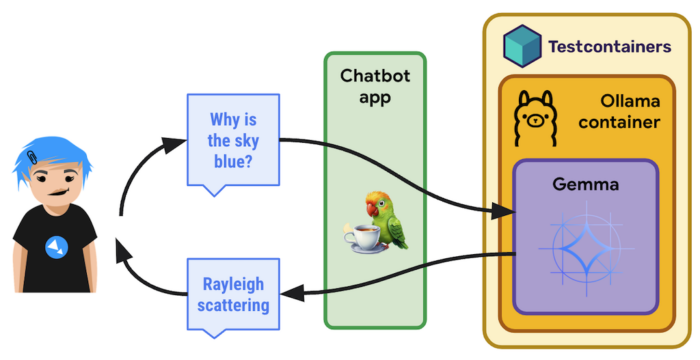
Time to implement this approach!
You'll find the code in the Github repository accompanying my recent Gemini workshop
Let's start with the easy part, interacting with an Ollama supported model with LangChain4j:
OllamaContainer ollama = createGemmaOllamaContainer();
ollama.start();
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl(String.format("http://%s:%d", ollama.getHost(), ollama.getFirstMappedPort()))
.modelName("gemma:2b")
.build();
String response = model.generate("Why is the sky blue?");
System.out.println(response);
- You run an Ollama test container.
- You create an Ollama chat model, by pointing at the address and port of the container.
- You specify the model you want to use.
- Then, you just need to call
model.generate(yourPrompt)as usual.
Easy? Now let's have a look at the trickier part, my local method that creates the Ollama container:
// check if the custom Gemma Ollama image exists already
List<Image> listImagesCmd = DockerClientFactory.lazyClient()
.listImagesCmd()
.withImageNameFilter(TC_OLLAMA_GEMMA_2_B)
.exec();
if (listImagesCmd.isEmpty()) {
System.out.println("Creating a new Ollama container with Gemma 2B image...");
OllamaContainer ollama = new OllamaContainer("ollama/ollama:0.1.26");
ollama.start();
ollama.execInContainer("ollama", "pull", "gemma:2b");
ollama.commitToImage(TC_OLLAMA_GEMMA_2_B);
return ollama;
} else {
System.out.println("Using existing Ollama container with Gemma 2B image...");
// Substitute the default Ollama image with our Gemma variant
return new OllamaContainer(
DockerImageName.parse(TC_OLLAMA_GEMMA_2_B)
.asCompatibleSubstituteFor("ollama/ollama"));
}
You need to create a derived Ollama container that pulls in the Gemma model. Either this image was already created beforehand, or if it doesn't exist yet, you create it.
Use the Docker Java client to check if the custom Gemma image exists. If it doesn't exist, notice how TestContainers let you create an image derived from the base Ollama image, pull the Gemma model, and then commit that image to your local Docker registry.
Otherwise, if the image already exists (ie. you created it in a previous run of the application), you're just going to tell TestContainers that you want to substitute the default Ollama image with your Gemma-powered variant.
And voila!
You can call Gemma locally on your laptop, in your Java apps, using LangChain4j, without having to install and run Ollama locally (but of course, you need to have a Docker daemon running).
Big thanks to Dan Dobrin for the approach, and to Sergei, Eddú and Oleg from TestContainers for the help and useful pointers.
Revenue Intelligence for Dev-Focused Companies
Reo.Dev analyzes developer activity across 20+ sources to identify high-intent accounts and key contacts ready to buy.
See How Reo.Dev Works!
- April 12, 2024
- 3 min read
Guillaume Laforge is a Java Champion, the co-founder of the Apache Groovy programming language, and is also a developer advocate for Google Cloud, focusing on generative AI, serverless technologies, and API orchestration.









Comments (1)
Java Weekly, Issue 538 | Baeldung
2 years ago[…] >> Calling Gemma with Ollama, TestContainers, and LangChain4j [foojay.io] […]