


Do You Trust Profilers? I Once Did Too.
- March 01, 2023
- 5 min read
Profilers are great tools in your toolbox, like debuggers, when solving problems with your Java application (I've been on a podcast on this topic recently).
I'll tell you some of their problems and a technique to cope with them in this article.
There are many open-source profilers, most notably JFR/JMC, and async-profiler, that help you to find and fix performance problems.
But they are just software themselves, interwoven with a reasonably large project, the OpenJDK (or OpenJ9, for that matter), and thus suffer from the same problems as the typical problems of the applications they are used to profile:
- Tests could be better
- Performance and accuracy could be better
- Tests could be more plentiful, especially for the underlying API, which could be tested well
- Changes in seemingly unrelated parts of the enclosing project can adversely affect them
Therefore you take the profiles generated by profilers with a grain of salt.
There are several blog posts and talks covering the accuracy problems of profilers:
- Profilers are lying hobbitses
- How Inlined Code Makes For Confusing Profiles
- Why JVM modern profilers are still safepoint biased?
I would highly recommend you to read my Writing a profiler from scratch series.
If you want to know more about how the foundational AsyncGetCallTrace is used in profilers. Just to list a few.
A sample AsyncGetCallTraceTrace bug
A problem that has been less discussed is the lacking test coverage of the underlying APIs.
The AsyncGetCallTrace API, used by async-profiler and others, has just one test case in the OpenJDK (as I discussed before).
This test case can be boiled down to the following:
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Main {
static { /** load native library */ }
public static void main(String[] args) throws Exception {
Class<?> klass = Main.class;
Method mainMethod = klass.getMethod("main");
mainMethod.invoke(null);
}
public static void test() {
if (!checkAsyncGetCallTraceCall()) {
throw ...;
}
}
public static native boolean checkAsyncGetCallTraceCall();
}
This is the simplest test case that can be written in the OpenJDK JTREG test framework for OpenJDK. The problem with this test case? The implementation of checkAsyncGetCallTraceCall only checks for the topmost frame.
To test AsyncGetCallTrace correctly here, one should compare the trace returned by this call with the trace of an oracle. We can use GetStackTrace (the safepoint-biased predecessor of ASGCT) here as it seems to return the correct trace.
GetStackTrace returns something like the following:
Frame 0: Main.checkAsyncGetStackTraceCall
Frame 1: Main.test
Frame 2: java.lang.invoke.LambdaForm$DMH.[...].invokeStatic
Frame 3: java.lang.invoke.LambdaForm$MH.[...].invoke
Frame 4: java.lang.invoke.Invokers$Holder.invokeExact_MT
Frame 5: jdk.internal.reflect.DirectMethodHandleAccessor
.invokeImpl
Frame 6: jdk.internal.reflect.DirectMethodHandleAccessor.invoke
Frame 7: java.lang.reflect.Method.invoke
Frame 8: Main.main
AsyncGetCallTrace, on the other hand, had problems walking over some of the reflection internals and returned:
Frame 0: Main.checkAsyncGetStackTraceCall Frame 1: Main.test Frame 2: java.lang.invoke.LambdaForm$DMH.[...].invokeStatic
This problem can be observed with a modified test case with JFR and async-profiler too:
public class Main {
public static void main(String[] args) throws Exception {
Class<?> klass = Main.class;
Method mainMethod = klass.getMethod("test");
mainMethod.invoke(null);
}
public static void test() {
javaLoop();
}
public static void javaLoop() {
long start = System.currentTimeMillis();
while (start + 3000 > System.currentTimeMillis());
}
}

So the only test case on AsyncGetCallTrace in the OpenJDK did not properly test the whole trace. This was not a problem when the test case was written. One can expect that its author checked the entire stack trace manually once and then created a small check test case to test the first frame, which is not implementation specific. But this is a problem for regression testing:
The Implementation of JEP 416: Reimplement Core Reflection with Method Handle in JDK 18+23 in mid-2021 modified the inner workings of reflection and triggered this bug. The lack of proper regression tests meant the bug had only been discovered a week ago. The actual cause of the bug is more complicated and related to a broken invariant regarding stack pointers in the stack walking. You can read more on this in the comments by Jorn Vernee and Richard Reingruber to my PR.
My PR improves the test by checking the result of AsyncGetCallTrace against GetStackTrace, as explained before, and fixing the bug by slightly loosening the invariant.
My main problem with finding this bug is that it shows how the lack of test coverage for the underlying profiling APIs might cause problems even for profiling simple Java code. I only found the bug because I'm writing many tests for my new AsyncGetStackTrace API. It's hard work, but I'm convinced this is the only way to create a reliable foundation for profilers.
Profilers in a loop
Profilers have many problems but are still helpful if you know what they can and cannot do. They should be used with care, without trusting everything they tell you. Profilers are only as good as the person interpreting the profiler results and the person's technique.
I have a background in computer science, and every semester I give students in a paper writing lab an hour-long lecture on doing experiments. I started this a few years back and continue to do it pro-bono because it is an important skill to teach. One of the most important things that I teach the students is that doing experiments is essentially a loop:
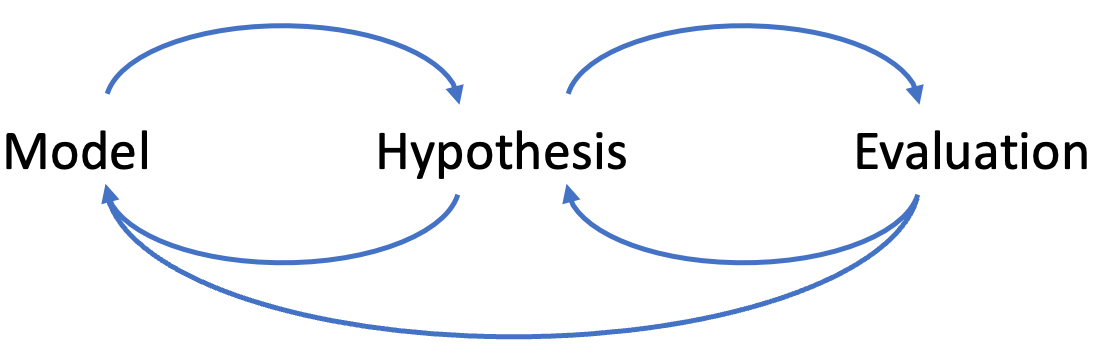
You start with an abstract model of the experiment and its environment (like the tool or algorithm you're testing). Then you formulate a hypothesis in this model (e.g., "Algorithm X is faster as Y because of Z"). You might find problems in your model during this step and go back to the modeling step, or you don't and start evaluating, checking whether the hypothesis holds.
During this evaluation, you might find problems with your hypothesis (e.g., it isn't valid) or even your model and go back to the respective step. Besides problems, you usually find new information that lets you refine your model and hypothesis. Evaluating without a mental model or a hypothesis makes it impossible to interpret the evaluation results correctly. But remember that a mismatch between hypothesis and evaluation might also be due to a broken evaluation.
The same loop can be applied to profiling: Before investigating any issue with a program, you should acquire at least a rough mental model of the code. This means understanding the basic architecture, performance-critical components, and the issues of the underlying libraries.
Then you formulate a hypothesis based on the problem you're investigating embedded in your mental model (e.g., "Task X is slow because Y is probably slow ..."). You can then evaluate the hypothesis using actual tests and a profiler. But as before, remember that your evaluation might also contain bugs. You can only discover these with a mental model and a reasonably refined hypothesis.
This technique lets you use profilers without fearing that spurious errors will lead you to wrong conclusions.
Conclusion
I hope you found this article helpful and educational.
It is an ongoing effort to add proper tests and educate users of profilers.
See you in the next article, where I cover the next step in writing a profiler from scratch.
This blog post is part of my work in the SapMachine team at SAP, making profiling easier for everyone.
- March 01, 2023
- 5 min read
A JVM developer working on profilers and their underlying technology, e.g. JEP Candidate 435, in the SapMachine team at SAP.













Comments (0)
No comments yet. Be the first.