


How to Create a Failover Client using the Hazelcast Viridian Serverless
- March 24, 2023
- 3 min read
Failover is an important feature of systems that rely on near-constant availability.
In Hazelcast, a failover client automatically redirects its traffic to a secondary cluster when the client cannot connect to the primary cluster.
Consider using a failover client with WAN replication as part of your disaster recovery strategy.
In this tutorial, you’ll update the code in a Java client to automatically connect to a secondary, failover cluster if it cannot connect to its original, primary cluster.
You’ll also run a simple test to make sure that your configuration is correct and then adjust it to include exception handling.
You'll learn how to collect all the resources that you need to create a failover client for a primary and secondary cluster, create a failover client based on the sample Java client, test failover and add exception handling for operations.
Step 1. Set Up Clusters and Clients
Create two Viridian Serverless clusters that you’ll use as your primary and secondary clusters and then download and connect sample Java clients to them.
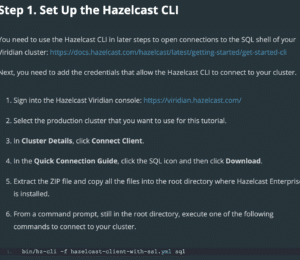
- Create the Viridian Serverless cluster (https://viridian.hazelcast.com/) that you’ll use as your primary cluster. When the cluster is ready to use, the Quick Connection Guide is displayed.
- Select the Java icon and follow the on-screen instructions to download, extract, and connect the preconfigured Java client to your primary cluster.
- Create the Viridian Serverless cluster that you’ll use as your secondary cluster.
- Follow the instructions in the Quick Connection Guide to download, extract, and connect the preconfigured Java client to your secondary cluster.
You now have two running clusters, and you’ve checked that both Java clients can connect.
Step 2. Configure a Failover Client
To create a failover client, update the configuration and code of the Java client for your primary cluster.
Start by adding the keystore files from the Java client of your secondary cluster.
- Go to the directory where you extracted the Java client for your secondary cluster and then navigate to
src/main/resources. - Rename the
client.keystorefile toclient2.keystoreand rename theclient.truststorefile toclient2.truststoreto avoid overwriting the files in your primary cluster keystore. - Copy both files over to the
src/main/resourcesdirectory of your primary cluster.
Update the code in the Java client (ClientwithSsl.java) of your primary cluster to include a failover class and the connection details for your secondary cluster.
You can find these connection details in the Java client of your secondary cluster.
- Go to the directory where you extracted the Java client for your primary cluster and then navigate to
src/main/java/com/hazelcast/cloud/. - Open the Java client (
ClientwithSsl.java) and make the following updates. An example failover client is also available for download.
Step 3. Verify Failover
Check that your failover client automatically connects to the secondary cluster when your primary cluster is stopped.
- Make sure that both Viridian Serverless clusters are running.
- Connect your failover client to the primary cluster in the same way as you did in Step 1.
- Stop your primary cluster. From the dashboard of your primary cluster, in Cluster Details, select Pause. In the console, you’ll see the following messages in order as the client disconnects from your primary cluster and reconnects to the secondary cluster:
CLIENT_DISCONNECTEDCLIENT_CONNECTEDCLIENT_CHANGED_CLUSTER
If you’re using the nonStopMapExample in the sample Java client, your client stops.
This is expected because write operations are not retryable when a cluster is disconnected.
The client has sent a put request to the cluster but has not received a response, and so the result of the request is unknown.
To prevent the client from overwriting more recent write operations, this write operation is stopped and an exception is thrown.
Step 4. Exception Handling
Update the nonStopMapExample() function in your failover client to trap the exception that is thrown when the primary cluster disconnects.
- Add the following try-catch block to the
whileloop in thenonStopMapExample()function. This code replaces the originalmap.put()function.try { map.put("key-" + randomKey, "value-" + randomKey); } catch (Exception e) { // Captures exception from disconnected client e.printStackTrace(); } - Verify your code again (repeat Step 3.). This time the client continues to write map entries after it connects to the secondary cluster.
Failover is an important feature of systems that rely on near-constant availability.
In Hazelcast, a failover client automatically redirects its traffic to a secondary cluster when the client cannot connect to the primary cluster.
Consider using a failover client with WAN replication as part of your disaster recovery strategy.
In this tutorial, you've updated the code in a Java client to automatically connect to a secondary, failover cluster if it cannot connect to its original, primary cluster.
You've also run a simple test to make sure that your configuration is correct and then adjust it to include exception handling.
You've learn how to collect all the resources that you need to create a failover client for a primary and secondary cluster, create a failover client based on the sample Java client, test failover and add exception handling for operations.
- March 24, 2023
- 3 min read
Fawaz Ghali is Principal Data Science Architect and Head of Developer Relations at Hazelcast with 20+ years of experience in software development, machine learning and real-time intelligent applications. He holds a PhD in Computer Science and has worked in the private sector as well as Academia as a Researcher and Senior Lecturer. He has published over 46 scientific papers in the fields of machine learning and data science. His strengths and skills lie within the fields of low latency applications, IoT & Edge, distributed systems and cloud technologies.











Comments (0)
No comments yet. Be the first.