

JVector 1.0
- October 02, 2023
- 2 min read
JVector is a pure Java embedded vector search engine that powers DataStax Astra and is being added to Apache Cassandra.
Vector search is a critical part of today’s generative AI applications, allowing developers to quickly retrieve the most relevant context to give the large language model enough information to answer accurately and without hallucinating, but innovation in this space has mostly happened outside the Java ecosystem. JVector gives enterprises an easy way to capitalize on their investment in the powerful Java platform, and gives Java developers a state-of-the-art solution that is easy to embed in their applications.
JVector’s closest relative is Apache Lucene’s vector search. Lucene implements the HNSW vector search algorithm, which is known to be fast but memory-hungry. Because it is based on the more sophisticated DiskANN algorithm, JVector is over 10x faster than Lucene for large datasets, holding other things equal. For example, here is a comparison of searching the Deep100M dataset (about 35GB of vectors and 20GB of index data) with Lucene and with JVector:
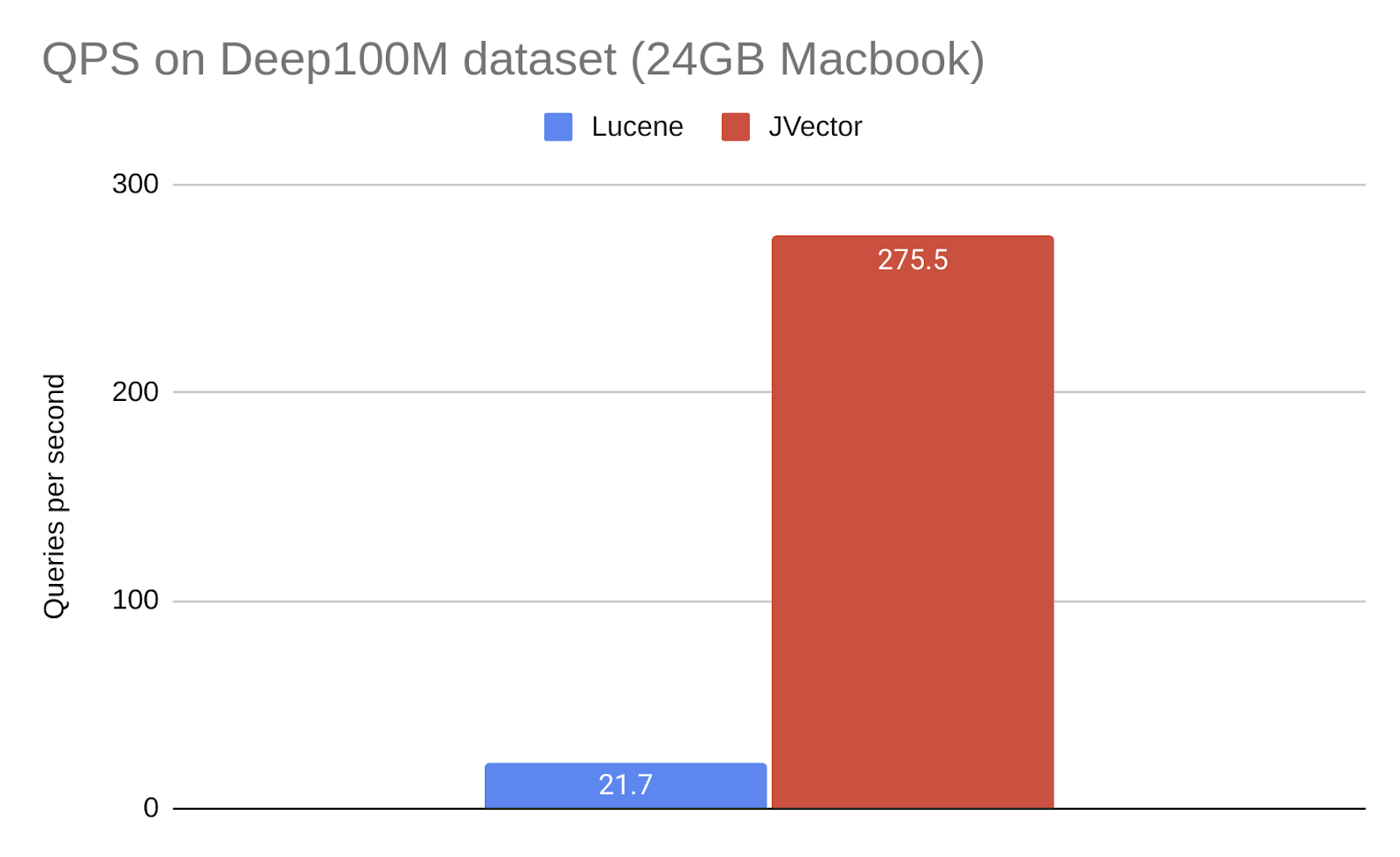
JVector is fast, memory-efficient, disk-aware, concurrent, easy to embed, and incremental.
Incremental means that you can start searching your JVector index immediately. There are no batches or microbatches or “commit” stages to wait for.
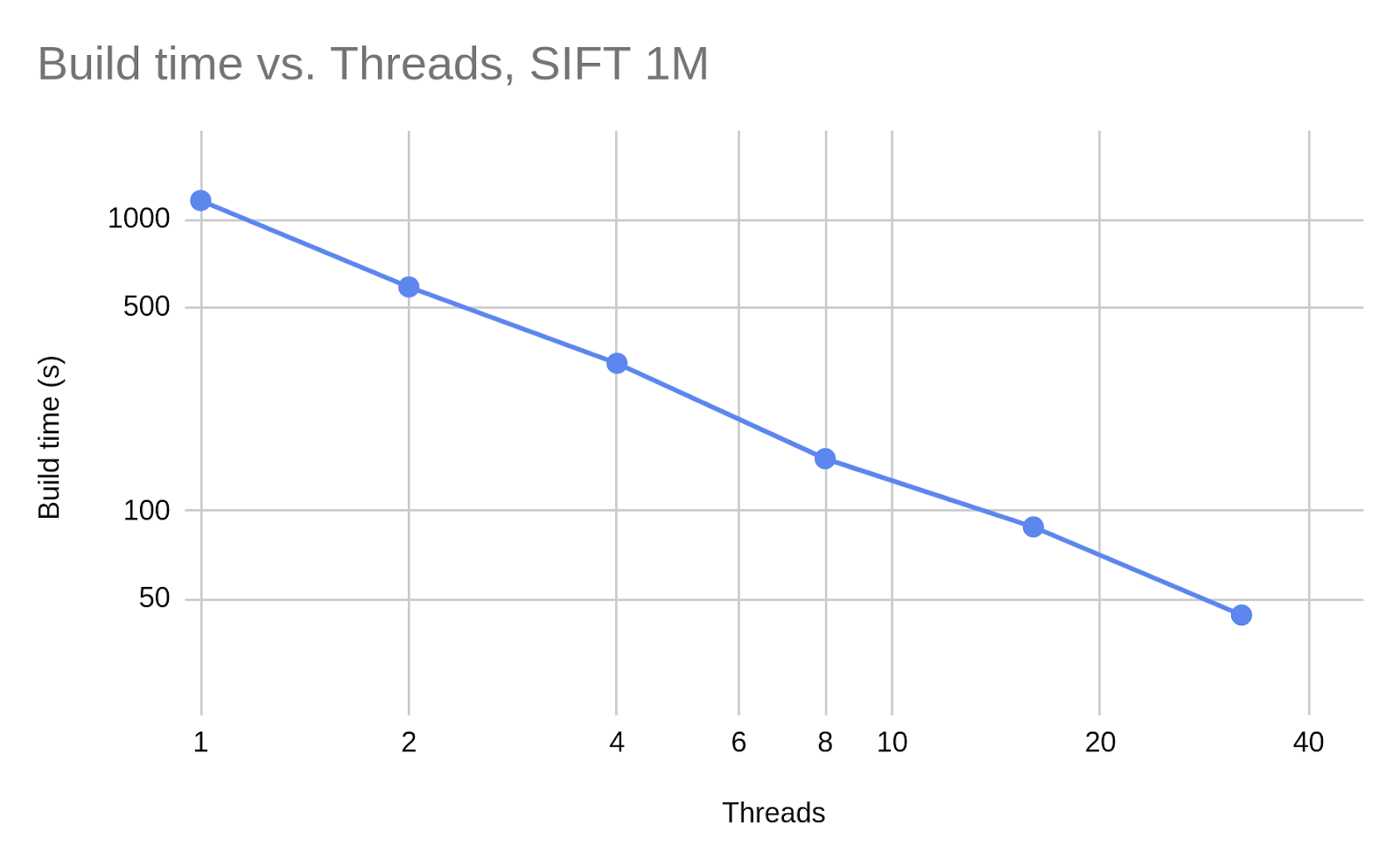
Concurrent means that you can build and search a JVector index with multiple threads simultaneously. Here you can see that doubling the number of threads adding vectors cuts build time in half, out to 32 threads. (X and Y axes are both logarithmic.)
JVector is designed to be straightforward to embed while preserving high performance. Here is the code to compute the index for the SIFT dataset shown above. In under 100 lines it
- Computes product quantization for the vectors (a kind of compression)
- Loads the vectors into the index, in parallel
- Saves the index to disk
- Conducts searches in parallel, against both in-memory and on-disk indexes
- Computes recall vs ground truth and reports performance numbers
JVector runs on JDK11+, and takes advantage of Panama SIMD acceleration on JDK 20+. JVector is available under the Apache License 2.0.
Try it out today and let us know what you think!
- October 02, 2023
- 2 min read
Jonathan is the founder of Brokk (https://brokk.ai). Brokk keeps LLMs on-task in million-line codebases by adding compiler-grade understanding of your code's structure and semantics. Jonathan is also the author of JVector, co-founder of DataStax, and the founding project chair of Apache Cassandra.










Comments (0)
No comments yet. Be the first.