

MicroStream – Part 2: Configure the Storage Manager
- June 15, 2022
- 5 min read
In this second article in the series, we cover how to get started configuring the StorageManager of MicroStream!
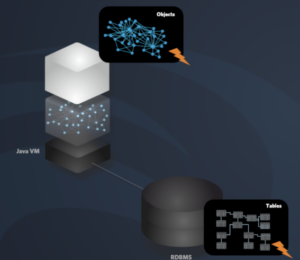
As we have discussed in the introduction article of this series, MicroStream provides you with a solution to use Java instances in memory as your database.
You can access the data through getters, the Stream API, or any other method provided on the Java Objects.
This means ultrafast, no mapping required, and no external system for your data.
And the Java instances are serialised to a persistent medium so that they can be restored when you restart the process.
In this article, we have a look at how you define what is considered as the database for MicroStream and how you can configure the storage manager.
The Storage Manager
You as a developer will interact with the class StorageManager to persist your data. When supplying the configuration, a StorageManager is ready to write the Java Instances in a binary format to the persistent medium. But more on the format later on, let us jump directly into some pieces of code to show you the gist of the StorageManager.
try (StorageManager storageManager = EmbeddedStorage.start(root, Paths.get("target/data"))) {
root.setContent("Hello World! @ " + new Date());
// Store the modified root and its content.
storageManager.storeRoot();
}
We start an embedded storage, an alternate name for referring to the Java instances in memory as database, by providing it a root object of the Object Graph that denotes our database and a path on the file system where data is persisted to survive a process restart.
Once we have the manager that is returned by the start() method, we can use it to store the root which makes sure the changed objects in the graph are saved to disk. When we do not need the Storage Manager anymore, we can close it as we do here implicitly with the try-with-resource statement.
But after each store operation on the manager, like the storeRoot() method in the above example, the system is crash resistant. Data is safely guarded on disk and will be read the next time it is accessed by a StorageManager.
What is that root object? In this example, it is just an Object holding a String reference.
public class DataRoot {
private String content;
// getter and setter
}
As indicated earlier, no need for a mapping, annotation, or interface, just plain Java POJOs.
Configuration
What dependencies do you need to add to your project? You just need a single dependency to have access to the StorageManager class that writes to the file system.
<dependency>
<groupId>one.microstream</groupId>
<artifactId>microstream-storage-embedded</artifactId>
<version>${microstream.version}</version>
</dependency>
It brings in a few other MicroStream artifacts, the persistence to binary format and the Abstract File System, more on that later, but there are no other external dependencies included through the artifact. With the latest release v7.0, we have added the SLF4J API dependency to be able to give some feedback on the internal actions through logging statements.
As mentioned, the StorageManager is the Object you interact with, but behind the scenes, there are about 15 concepts that work together to bring you the database functionality through Java POJOs. They all can be configured and you can even create specialised implementation of them to customise the entire functionality of MicroStream. But in general, as a developer, you need to provide 4 configuration aspects
- The root object of the Object Graph
- The location where MicroStream needs to store the data in a binary format
- Optionally a backup directory where the data is duplicated
- Optionally the number of threads, called channels, that are used to write and read the data to and from the disk.
The first 2 are already used in the first section of this article. The Backup directory can be specified if you want to have a continuous backup of the data. The number of channels, by default 1, should be increased for systems that write a lot of data or need to perform many operations to achieve optimal performance. More on some storing strategies in the third article.
The easiest way to define all these 4 configuration aspects can be done using the StorageConfiguration object.
NioFileSystem fileSystem = NioFileSystem.New();
Path backup = Paths.get("backup");
StorageConfiguration storageConfiguration = StorageConfiguration.Builder()
.setStorageFileProvider(
Storage.FileProviderBuilder(fileSystem)
.setDirectory(fileSystem.ensureDirectoryPath("data"))
.createFileProvider()
).setBackupSetup(StorageBackupSetup.New(fileSystem.ensureDirectory(backup)))
.setChannelCountProvider(StorageChannelCountProvider.New(2))
.createConfiguration();
StorageManager storageManager = EmbeddedStorage.start(root, storageConfiguration);
Abstract File System (AFS)
To allow for different kinds of persistence storages, MicroStream uses internally an Abstract File System. The systems that read and write the data use implementations of this AFS so that not only a directory on the disk can be used, but also data can be stored inside a database. You can create even your custom implementation of this AFS and use any system you like.
Why do you want to store it in a database as the point of MicroStream was to avoid those systems? We are not saying all database usage is bad and it turned out that many MicroStream users want to store it in the database instead of the filesystem because it was easier to backup or it is already part of the entire backup system of the company.
The database storage stores the binary format into a table of the database, so it does not need to perform any mapping for the data. For the MicroStream subsystems, the database is just a place to store and read the binary data, through the AFS, just as it does with the file system.
How can you make use of it? Add the AFS SQL artifact to your project to have support for PostgreSQL, MariaDB, and SQLLite.
<dependency>
<groupId>one.microstream</groupId>
<artifactId>microstream-afs-sql</artifactId>
<version>${microstream.version}</version>
</dependency>
Other databases are supported for our Enterprise customers through additional artifacts. But also No-SQL solutions, like Redis, Kafka, and Hazelcast and Cloud storage like Amazon S3 and Microsoft Azure Blob Storage.
Instead of the NioFileSystem class, we used earlier to write to disk, we use this time SqlFileSystem as this provides the implementation for the AFS. We need to supply a data source to the database and the following example uses the table data to store the Type Dictionary, more on this in article number 4 about the serialisation of Java instances of MicroStream, and tables _data_channel0 and _data_channel1 to store the binary data for the Java instances.
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setUrl("jdbc:postgresql://localhost:5432/mydb");
dataSource.setUser("postgres");
dataSource.setPassword("mysecretpassword");
SqlFileSystem fileSystem = SqlFileSystem.New(
SqlConnector.Caching(
SqlProviderPostgres.New(dataSource)
)
);
StorageConfiguration storageConfiguration = StorageConfiguration.Builder()
.setStorageFileProvider(
Storage.FileProviderBuilder(fileSystem)
.setDirectory(fileSystem.ensureDirectoryPath("data"))
.createFileProvider())
.setChannelCountProvider(StorageChannelCountProvider.New(2))
.createConfiguration();
Configuration through Configuration Files
Until now, we have always used the programmatic configuration of the StorageManager. Through some Java statements, we defined the file locations and the number of channels that need to be used. MicroStream has the option to read the configuration properties from external sources like properties files, ini files, and XML files.
You can of course read configuration values yourself from an external source, but all code is already available within the Embedded Storage Configuration artifact.
<dependency>
<groupId>one.microstream</groupId>
<artifactId>microstream-storage-embedded-configuration</artifactId>
<version>${microstream.version}</version>
</dependency>
With this dependency in place, we can just refer to the location of the configuration file and the Storage Manager can be configured based on the key-value pairs that are found. The supported formats are properties and ini files and XML files. The format is based on the extension the configuration file has.
The next snippet shows how you can read it from a classpath file.
try (EmbeddedStorageManager storageManager = EmbeddedStorageConfiguration.load(
"META-INF/microstream/storage.properties" )
.createEmbeddedStorageFoundation()
.createEmbeddedStorageManager()
.start()
) {
// Use storageManager
}
The EmbeddedStorageFoundation class is actually the configuration class that gives you the possibility to configure every little detail of MicroStream. The StorageConfiguration we have used in the previous section is a convenient helper method to configure the most important aspects while leaving all the other configuration aspects to their defaults.
The list of all configuration properties and their description can be found on this documentation page https://docs.microstream.one/manual/storage/configuration/properties.html
Conclusion
Setting up the Storage Manager can be as easy as pointing a directory on disk to the root object of the Object Graph that we consider as our in-memory database.
The project needs a single dependency to the MicroStream artifacts and does not pull in any external dependencies except the SLF4J API to perform some logging.
Besides the programmatic configuration, configuration values can also be read from files like properties and XML.
This allows the configuration of your application to be outside of the artifact which is a must to run it properly in different environments like test and production.
The Storage Manager does not write to disk directly but makes use of the MicroStream's Abstract File System.
This AFS makes it possible that the binary data can be written to many types of storage, including databases, No-SQL solutions, and cloud storage.
Resources
- MicroStream reference manual chapter around configuration
- MicroStream storage targets - AFS
- MicroStream Website
- June 15, 2022
- 5 min read
Rudy loves to create (web) applications with the Jakarta EE platform and MicroProfile implementations. Currently, he is a Developer Advocate for MicroStream. He has implemented various projects in a team for customers, helped various Open Source projects (Payara, MicroProfile, PrimeFaces, DeltaSpike, Apache Myfaces, ...), and supported Developers and teams. He is also working around Web Application Security using OAuth2, OpenId Connect, and JWT.








Comments (1)
Bruce Melo
3 years agoI did an example with the help of your article using Spring Boot 3.1 and PostgreSQL. https://github.com/brucemelo/spring-microstream