

MicroStream – Part 1: What is it?
- June 06, 2022
- 6 min read
Within every application, data plays a very important role.
In every industry, you have data, such as customer or product information, analysis results, patient data, or account data is a vital part of the business and the applications that support your business processes.
Data must be in memory to be processed by your application, but must be stored outside of it because the application's memory is temporary.
Information is lost when the process ends unless we have stored it somewhere else in a sustainable way.
But what if we would only need to deal with the object graph in memory, and wouldn't need to care about how the data is persisted, nor spend time to define the mapping and lose processing time to perform this mapping to the external system.
That is the main idea of the MicroStream framework, the realization of ultra-fast in-memory data processing with pure Java. The Java object graph is stored in a storage location using a fundamentally new serialization concept designed from scratch.
Object-Relational Impedance Mismatch
In the most simple cases, the structure of the data within memory matches the data structure in the database relatively well. We have Entities that map to tables and properties that match fields in the database. But sometimes the ideal structure in both systems does not match. And in all cases, the data needs to be retrieved from the relational system using a specific protocol.
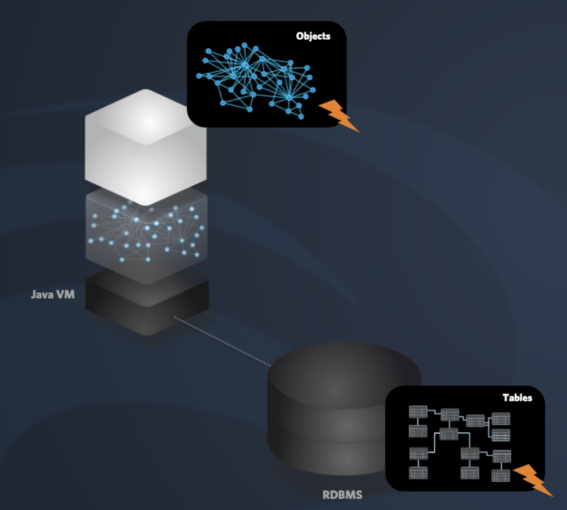
Retrieving a single record is relatively straightforward. But all the required data is seldom included in a single record in the external system. So we need to execute a complex multi-table query with many relations and restrictions. The alternative is executing many simple queries but these roundtrips to the other system are also very time-consuming. The ORM (Object Relational Mapping) frameworks relieved the developer from writing database queries, but these generic frameworks are not super fast, and often many tweaks need to be applied to retrieve the data with an acceptable speed.
Stepping away from the traditional databases and SQL queries do not solve this problem. The so-called NoSQL solutions also need to be accessed with a system-specific protocol, are also external to the JVM, and mapping of the data is also required.
So that is why at MicroStream we believe the Java memory itself must be the data storage. An Object graph containing your data that you can quickly access using getters, Stream API, or whatever method there is available on the Object instances. No more mapping is needed, data is available within the memory.
A newly designed serialisation framework, build from the ground up, will make sure that those Java instances in the Object Graph that you have indicated as your primary data are stored by the Storage Manager. That component is also responsible for reading all the information back into the memory when you start up your process again.
User Scenarios
Since MicroStream is just written in plain Java, it can be used in a variety of scenarios as there are no limitations. The objects that are serialised don't have any restrictions, any plain POJO can be used. There is no requirement related to an interface that must be implemented, annotations that are present, or restrictions on the Java class itself.
Let us describe three user scenarios in a bit more detail where we think that MicroStream can really shine.
1. Microservices Local Data Storage
Microservices are centered around a certain domain of your business. A service can be responsible for all actions related to products, or stock. But these services don't run on their own as they need data from other services to validate or complete the user request.
We already described in the Object-relational impedance mismatch section that data needs to be retrieved from an external system. When you use microservices, this is even worse as you potentially need to call multiple other services over the network, which need to retrieve the data from the external system.
So many authors describe the need for a cache of the most important data within the microservice. This avoids that expensive calls need to be made over the network and data is already available when the user request is processed. This cache can be updated based on events that are received from the other services that data needs to be updated because the master source is changed.
Storing the data in an in-memory cache persisted using the features of the MicroStream library is an ideal solution here. Data is accessible very fast as it resides in memory, is persisted so that it can survive a restart of the process, and can be updated based on the information in the events.
2. Serverless Functions
Serverless functions are the smaller variant of the microservices as they in general only implement a single functionality and not all the functionality related to a domain.
The idea is that they are started by the management system when a user request comes in and quickly prepares the response. When the function also needs to wait until the database connection is created and potentially a slow query is executed, there is no fast initialisation possible of the Serverless Function and the architecture is no longer useable.
But instead of residing to solutions to keep the functions warm to avoid the cold startup problems, which turns them basically into small microservices as they are not started anymore for each call, MicroStream can improve the startup time.
MicroStream has the possibility of Lazy loading the data into memory. Instead of retrieving all the Java instances from storage at the startup of the Storage Manager, instances are only restored when accessed. This makes the startup of the process very fast as it doesn't need to initiate the connection to the external system and data can be accessed quickly as it is only read in the portion that is needed to handle the user request.
3. Alternative for SqlLite on Android
The SqlLite database is used in many cases to store data offline within Android applications. No Wifi or 4G connection is needed to reach the server and keep the data entered by users, it can be done on the device storage.
But a lot of work is required to set up this connection, perform the mapping and execute the queries. Since The android apps are also JVM-based, MicroStream can be used on these devices, even in the combination with Kotlin which is very popular today for the Mobile applications running on the Android system.
From now on, you only have to deal with the Java objects and instances as data is stored in regular POJOs and MicroStream makes sure the objects are persisted in the storage of the device and available the next time the user accessed the application or the device gets online.
MicroStream Highlights
With MicroStream, data is stored within the Java Heap as plain POJOs. You don't have any annoying restrictions as any class is supported, without the need to have annotations or interface or markers or parent class that needs to be applied.
Since your data is in memory, within Java objects, you can access it extremely fast by using the provided getter methods, Stream API, or any other way that is available within the JVM or the classes that you implement.
The Storage Manager is responsible for writing the Object Graph to a persistent medium, like disk or even as BLOBs in a database, in a binary format that is built upfront the ground to avoid the security vulnerabilities the standard Java Persistence has.
It runs wherever Java runs and so can be used in a monolith, microservice, Java Serverless function, Android device, in combination with any JVM language like Kotlin and Scala.
Conclusion
Data are a required resource in any application of a company, regardless of the industry.
But this information is not stored within the application but it needs to be retrieved from an external system into the memory of the process.
This retrieval is many times rather slow, requires a lot of development effort for creating the mappings and the queries to retrieve it, and so on.
MicroStream reverts the idea of data usage and storage within the applications.
The Java memory itself is the data storage.
Data is stored in Java instances, plain POJOs that form an Object graph.
Retrieval is super fast and easy as it requires only the execution of some methods on those instances.
Although the primary source is the memory, we need to persist the data in a durable medium.
This is the task of the Storage Manager to persist the Java instances in a binary format, in a security vulnerability-free way.
Resources
- June 06, 2022
- 6 min read
Rudy loves to create (web) applications with the Jakarta EE platform and MicroProfile implementations. Currently, he is a Developer Advocate for MicroStream. He has implemented various projects in a team for customers, helped various Open Source projects (Payara, MicroProfile, PrimeFaces, DeltaSpike, Apache Myfaces, ...), and supported Developers and teams. He is also working around Web Application Security using OAuth2, OpenId Connect, and JWT.









Comments (1)
Minimize costs utilizing the cloud with Spring-Data-Eclipse-Store
2 years ago[…] folks of EclipseStore (formerly known as MicroStream) wanted to use a different approach: Starting and managing the database through your native Java […]