


Why Pulsar Beats Kafka for a Scalable, Distributed Data Architecture
- March 03, 2022
- 5 min read

The leading open source event streaming platforms are Apache Kafka and Apache Pulsar. For enterprise architects and application developers, choosing the right event streaming approach is critical, as these technologies will help their apps scale up around data to support operations in production.
Everyone wants results faster. We want applications that know what we want, even before we know ourselves. We want systems that constantly check for fraud or security issues to protect our data. We want applications that are smart enough to react and change plans when faced with the unexpected. And we want those services to be continuously available.
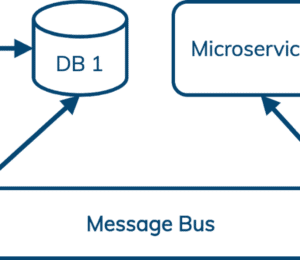
These data-centric applications combine and use data to produce the right results. Event streaming is a key element in building these applications. Event streaming allows applications to take events – a customer action, a sensor log file, a transaction taking place – and checks them against specific criteria. If they match, the event is sent on and triggers an action. For modern applications based on microservices, this integrates different services with each other by acting as a message bus, and can be used to trigger those services to carry out processes or to take an action.
Implementing this in the right way is important. IDC estimates that companies will spend $8.5 billion on event streaming annually by 2024. Open source infrastructure will play an essential role in this. The leading open source event streaming platforms are Apache Kafka and Apache Pulsar. For enterprise architects and application developers, choosing the right event streaming approach is critical, as these technologies will help their apps scale up around data to support operations in production.
Apache Pulsar is the right choice to meet today’s developer criteria across two important trends today: developers want to make more use of cloud and microservice-based architectures to develop their applications, and they don’t want to be locked into proprietary APIs and services.
SEE ALSO: Moving to cloud-native applications and data with Kubernetes and Apache Cassandra
Microservices and Pulsar
When you put together applications based on a microservices model, you decouple all the components that make up the service and have them communicate with each other through messages conforming to well-defined APIs. Each component will then create and manage its own data based on the activities and requirements it supports.
Cloud databases like DataStax Astra or Amazon DynamoDB are a great fit for microservices-based applications because it’s so easy to provision dozens or hundreds of databases that each microservice can use independently of the others. There are no DBAs to become bottlenecks, and no quality of service problems from sharing a single database instance.
Astra is unique in offering built-in support for replication across multiple regions, allowing both a better user experience (data is closer to users) and improved reliability (even in the face of outages that take down an entire cloud region). This was a straightforward extension of the same properties in Apache Cassandra that Astra is based on.
But besides the database, microservices-based applications need a communication layer to route messages between services. Apache Kafka is often used for this purpose today, but Kafka was developed to run in a single region and does not offer built-in, cross-datacenter replication. This is one of the problems that Apache Pulsar was created to solve as an alternative to Kafka.
Geo-replication was just one improvement resulting from the more general architectural advance that Pulsar made by separating compute and storage. This change at the core of Pulsar allows it to scale more elastically than Kafka as well as to lower costs with tiered storage, where older messages are stored in an object store like HDFS or Amazon S3.
Apache Pulsar is also a superior choice for microservice architectures because of its first-class support for multi-tenancy — allowing multiple services to easily share Pulsar infrastructure, even across different lines of business, while consistently enforcing data retention and security policies. Multi-tenancy is very useful for service providers because it allows them to run the same streaming data platform for multiple customers.
Multi-tenancy is also growing in importance for single organizations, where different units or departments need a level of security and privacy for their customers’ data. Consider the example of a bank: each financial product team wants to manage access and services around customer data, but they won’t want to implement their own complete event streaming implementations. Instead, each team can have their data as part of that multi-tenant environment.
Adding multi-tenancy support to infrastructure software after the fact is incredibly hard. Kafka doesn’t supply this capability; it was designed to run as a single user service, rather than to be multi-tenant. Pulsar, on the other hand, was developed to support multi-tenant deployments from the start and as part of the open source version. The alternative is to stand up a separate streaming deployment for each and every use case, which can quickly grow much more expensive as well as more difficult to manage consistently.
How Pulsar fits into the open source mindset
Software developers today prefer to work with open source. Open source makes it easier for developers to look at their components and use the right ones for their projects. Using a modular, flexible, open architecture not only enables the right mix of best-of-breed tools as the business – and the technology – evolves; it also simplifies the ability to scale.
By taking a fully open source approach, developers can support their business goals more easily. In fact, companies using an open source software data stack are two times more likely to attribute more than 20 percent of their revenue to data and analytics, according to a recent research report by DataStax.
When your developers have the option of using open source projects, they will pick the project that they think is best. This can lead to the issue of creating a level of consistency and cohesiveness in your data stack. Without some consistency of approach, managing the implementation will get harder as you scale. Building on the same set of platforms that carry out their work in the same way can lessen the overhead.
As an example, event streaming features often serve users and systems that are geographically dispersed, so it’s critical that streaming capabilities provide performance, replication, and resiliency across disparate geographies and clouds. Other elements of the application will also have to deliver those same capabilities – so as a database, Apache Cassandra is known for excelling at running across multiple geographies, replicating data and being resilient. Pairing the power and scalability of this NoSQL, open source database with a truly distributed, high-scale streaming technology like Pulsar creates a complete open source data stack that can support the full set of stateful infrastructure needs in microservice architectures.
Pulsar also fits into a broader approach to open source infrastructure that developers and architects will support involving Kubernetes. As a container orchestration platform, Kubernetes manages how applications scale based on demand and it can restart components if they fail. It abstracts the work of managing individual components and lets developers concentrate on how their applications will meet specific use cases. Pulsar supports deployment in Kubernetes alongside other applications, so that you can manage all your infrastructure from one tool.
SEE ALSO: Five Data Models for IoT: Managing the Latest IoT Events Based on a State in Apache Cassandra
Pulsar’s role
Companies want to support their customers, and today’s customers expect their applications to deliver results instantly. Companies that put the right infrastructure in place to enable that immediacy will unlock their development teams’ innovation and grow their businesses.
In today’s software development landscape, the ability to use open source components to handle data is a given. However, to meet the next challenge around scaling out applications around data, those open source components have to be part of a coherent, consistent stack. This open data stack should make it easier to support microservice applications in production from a data perspective, scaling to support thousands or millions of customers concurrently. Event streaming will be what connects these microservice applications together, and Pulsar has the best design approach to support how those applications will grow and scale over time.
- March 03, 2022
- 5 min read
Jonathan is the founder of Brokk (https://brokk.ai). Brokk keeps LLMs on-task in million-line codebases by adding compiler-grade understanding of your code's structure and semantics. Jonathan is also the author of JVector, co-founder of DataStax, and the founding project chair of Apache Cassandra.











Comments (0)
No comments yet. Be the first.