


Hazelcast, from Embedded to Client-Server
- April 23, 2021
- 6 min read
Java developers are particularly spoiled when using Hazelcast. Because Hazelcast is developed in Java, it's available as a JAR, and we can integrate it as a library in our application. Just add it to the application's classpath, start a node, and we're good to go. However, I believe that once you start relying on Hazelcast as a critical infrastructure component, embedding limits your options. In this post, I'd like to dive a bit deeper into the subject.
Starting with embedded
As mentioned above, the easiest way for Java developers to start their journey using Hazelcast is to embed it in their application like any other library. During the application startup lifecycle, we just have to call Hazelcast.newHazelcastInstance(): this will start a new Hazelcast node in the currently running JVM. Because of Hazelcast auto-discovery capabilities, without further configuration, nodes will discover each other and form a cluster. In a couple of minutes of development time, we can create a distributed In-Memory Data Grid. Hard to do better in terms of Developer Experience!
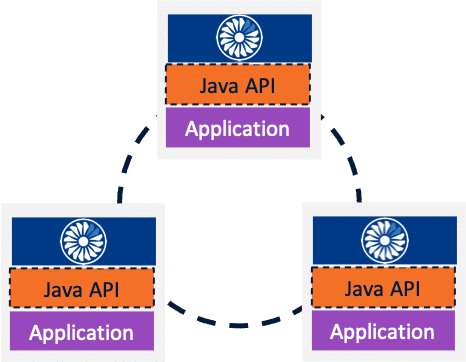
Spring Boot makes our life even easier. Just add a hazelcast.xml file at the root of the classpath (or a Config bean to the application context), and the framework will start Hazelcast for you with the given configuration.
It's a great starting point, but I hope that at some point, your application is going to receive more attention, which will increase the load. To handle it, a couple of solutions are available:
- Keep the same number of nodes but try to configure the JVM for better performance
- Scale horizontally, i.e., add more nodes to the cluster.
- Scale vertically, i.e., give each node more resources.
In all of those cases, the coupling of the application and Hazelcast limits the benefits. For example, you'll need to choose to configure the JVM for the application workload or Hazelcast's. You'll need to scale horizontally according to the most limiting factor, the app or Hazelcast. And by scaling vertically, there's no way to assign the additional resources to one or the other facet.
To avoid those problems, the next logical step is to migrate to a client-server deployment model.
Client-Server Deployment
The principle underlying Client-Server deployment is the separation of concerns: decoupling the application from the Hazelcast node.
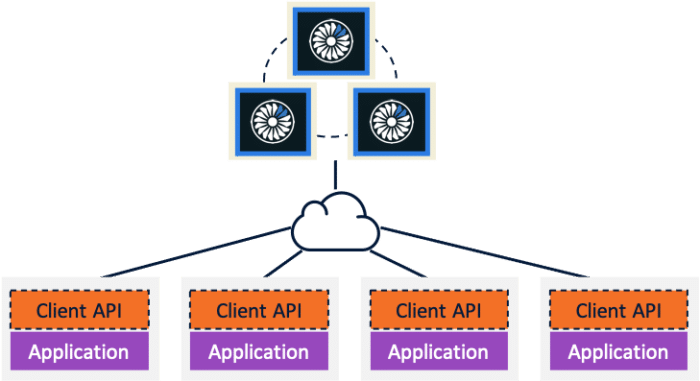
The benefits are readily available:
- We can configure the Hazelcast JVM in relation to its workload profile only
- We can scale the Hazelcast cluster horizontally independently from the application's
- We can allocate resources to either Hazelcast nodes or the application's, and they won't compete for them
As an additional benefit, we can now use any (or all!) other languages that Hazelcast provides: C++, Python, Node.js, Go, C#, and of course, Java.
Unfortunately, there's no such thing as a free lunch. While moving from embedded to client-server makes it possible to scale quickly, new pitfalls have cropped up.
Pitfall #0: Launching
The first pitfall is not a true one but a simple question. How do we launch Hazelcast now that it's not embedded anymore?
The easiest way to launch Hazelcast is to use the command line. Install it. Run it. It's the fastest path to get you started, but this is not recommended for production. Alternatively, you can also download the Hazelcast distribution and run the start script. The command line is intended for development purposes: it's not fit for production usage unless you build a custom operations layer on top - and we don't recommend it.
If you're using containerization technologies, we offer Docker images. If you run your workload on Kubernetes, check our Helm chart.
This section is only a summary. Please be sure to check the documentation for all available options and their respective details.
Pitfall #1: Classpath
In embedded mode, the JVM runs both the application and Hazelcast. If you want to add any of the provided extension points, you just need to register it, and it will work out of the box as the application and Hazelcast share the same classpath: this is not true anymore for client-server.
Let's detail a concrete example. Imagine that our application uses Hazelcast to cache data from a database. We want to decouple our architecture and, to do so, implement a Read-Through/Write-Through cache. This way, the application only interacts with the cache, while the cache interacts with the database. Hazelcast makes it possible with the MapLoader interface for Read-Through and MapStore for Write-Through.
We could implement those interfaces in our project and the implementation classes via the configuration in embedded mode. But now, we need to create a dedicated Java project with the Hazelcast dependency, implement the interfaces in this project, package the project as a JAR, and add it to the classpath of each of the running Hazelcast nodes.
While it's neither complex nor complicated, it's additional work.
Another related classpath management issue comes from domain classes. On the JVM, with the notable exception of Clojure, developers tend to model domain entities with classes, e.g., Person, Customer, User, etc. If the above extensions use those classes, e.g., the MapLoader reads from the database, creates a new Person instance, and stores it in the IMap, they also need to be on the members' classpath.
Because they're bound to the business, domain classes probably change more often than classes that customize Hazelcast. Whenever a domain class changes, we need to update the JAR and restart each node with the updated JAR version. Worse, different nodes will run different versions. If the change is not forward-compatible (a very likely occurrence), exceptions will pop here and there. Hence, we need to shut down the whole cluster before upgrading.
To cope with that, we have two solutions:
- The legacy path is user code deployment. It allows to "send" code from a client member to the cluster. This way, no restart is needed. On the flip side, the cluster needs to accept that an external component can change the code it runs. It extends the attack surface of your system. With user code deployment, you're trading less security for more agility. Therefore, you need to weigh the pros and cons before walking this path.
- With Hazelcast 4.1, we provide an alternative in the form of generic records. As its name implies, such a record is generic, meaning you can access the data without the class on the member's classpath. Generic records come with some limitations as well. For example, while you can read data, you cannot write it. Note that generic records are considered BETA at the time of this writing.
Pitfall #2: Serialization
While running embedded, domain objects are straightforward: implement Serializable without a second thought and "it just works." If you migrate to a client-server deployment, provided that you curate the members' classpath as mentioned above, it will work as well. Note that even in that case, Java serialization is not very performant, wastes space, and is a security concern.
However, the client-server deployment model opens new doors: the cluster data is suddenly more visible. Other developers, teams, or departments in your organization might be interested in using this newly-found source of data. But maybe you don't want to couple your teams by providing them a JAR of your domain classes so they can deserialize the domain objects? Or perhaps their technology stack might not be based on the JVM, so they cannot deserialize the data at all? In all cases, it opens an interesting debate regarding which format you should use to store data.
Hazelcast offers a couple of out-of-the-box formats and can integrate with virtually anything. But in embedded mode, we limit ourselves unnecessarily. Imagine a Hazelcast cluster that needs to serve both Java clients and Python clients. Each stack manages items with its class representation.
The Portable serialization mechanism allows us to store data in one stack and to access it from the other - and the other way around. Its main benefit is that it doesn't require reflection. Even if you don't use multiple languages, you can not only store the representation of your data on the server-side without having the classes on the members' classpath, but you can also query it. Did you have a look at our new SQL API by the way? Given that business classes' lifecycle is bound to be short, it's one less concern during deployment.
Pitfall #3: Embed During Development, Client in Production
The final problem is how to manage Hazelcast during the development process.
In Java, it's unnecessary to embed a node during development and run it as a client during production. It can be achieved in different ways:
- Hazelcast itself allows you to override properties individually and to point to a specific configuration file. It's even possible to compose different configuration snippets.
- Alternatively, if you're using Spring Boot, it's possible to provide different configurations depending on a profile. Spring Profiles are a runtime feature. Please check the relevant documentation for more information on how to create profiles.
- The Maven build tool also offers a profile feature, but at build-time. While it's an option, my experience is that build-time configuration can increase the number of artifacts.
- Finally, you can combine the options above.
Those are great options if you're developing in Java, but all is not lost if you aren't. Containerization can help us a lot! For example, the TestContainers project is available in all stack that Hazelcast support: Python developers can easily leverage the Python project to set up a local Hazelcast cluster quickly, Go developers the Go project, C# developers the .Net project, etc.
Conclusion
While it's easier to start Hazelcast if you're a Java developer, the embedded deployment model is limited compared to the Client-Server one. Migrating to the later deployment model allows you to "free" your data and make it available across the organization.
You'll encounter the pitfalls mentioned above along the way. It's perfectly normal. I hope that this post will allow you to overcome them easily.
- April 23, 2021
- 6 min read
Technologist focusing on cloud-native technologies, DevOps, CI/CD pipelines, and system observability. His focus revolves around creating technical content, delivering talks, and engaging with developer communities to promote the adoption of modern software practices. With a strong background in software, he has worked extensively with the JVM, applying his expertise across various industries. In addition to his technical work, he is the author of several books and regularly shares insights through his blog and open-source contributions.









Comments (0)
No comments yet. Be the first.