

MicroStream – Part 3: Storing Data
- June 22, 2022
- 6 min read
In the third article of the MicroStream series, we go into the details what you need to do so that data is stored externally to survive the process restart.
In the previous articles in this series, we introduced the main features of the framework and how you can configure the StorageManager.
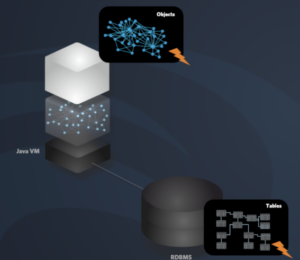
Java instances in memory are your database but the StorageManager makes sure that the data are persisted so that they are read the next time the runtime is started again.
In this article, we look more in detail at how you can structure the data and what you need to do so that data is stored binary safely.
The Root object
Java objects have references to other objects which may in turn have references to more objects including the starting object. All references and the objects that are part of it are called object graph. A Java program can contain several objects graph but your data typically is included in one graph. If we think about products, stock, orders, customer, address, etc.. they are all linked together.
In many cases, there is no real start and end to the graph. In the above example, we can access the data starting from the customers, or the products. Through the links between them, we can reach all the instances.
But the MicroStream storage mechanism needs to start from somewhere. So we need to provide it a single starting point, the root object. In many cases, it contains one or more collections where the object graph of this root object represents your entire dataset.
public class StorageRoot {
private List products;
private List users;
}
In this example, the root object has 2 lists to access the data in a certain fashion. This creates some circular references but MicroStream can handle this without any problem as it also uses references in the binary representation.
Storing the Root Object
When you start your application for the first time, the StorageManager points to an empty directory or storage system so it can't load anything in memory. So you have to provide an initial instance of the root object. And this can be done when you start the StorageManager or explicitly through the setRoot() method.
When you provide an instance of the root object when you start the EmbeddedStorage, it will be saved to disk when the directory was empty. But if there was already content from a previous run of the application, the stored data will be used to reconstruct the root object as it was the last time that you ran the application.
try (StorageManager storageManager = EmbeddedStorage.start(root, Paths.get("target/data"))) {
}
This might be confusing and is dependent on the state of the external storage (empty or already containing data). An alternative is to explicitly define the root and store it when no data is present yet.
try (StorageManager storageManager = EmbeddedStorage.start(Paths.get("target/data"))) {
DataStorage root = (DataStorage) storageManager.root();
if (storageManager.root() == null) {
root = initRoot();
storageManager.setRoot(root);
storageManager.storeRoot();
}
// Use root and storageManager
}
Store what is Changed
After the initial storage of the root object with the storeRoot() method, we no longer use this method to store some changes later on. And this has several reasons.
By default, MicroStream only stores changes to the Object graph and not the entire object graph each time. If we refer to StorageRoot definition we have above, using the storeRoot() method will not write any new information. The pointers for products and users are still the same and thus the Lazy evaluator stop looking further in the object graph. A new User we might have added is thus not stored and thus not available when we restart the application again.
Storing the entire object graph will also not be very efficient. If we have several megabytes of data in the object graph of the root, storing that amount for just a change of the email address of a user is not good.
You should always use the store() method when you have some changes that need to be persisted.
User user = findUser(someCriteria); user.setEmail(newEmailAddress); storageManage.store(user);
Since the User object was already persisted previously, as part of the ArrayList variable of DataStorage for example, storing it will make sure that we have the updated information for that user when the StorageManager reads the data again.
If we have a new user that is added to the ArrayList, make sure that you store the List variable.
users.add(newUser); storageManage.store(users);
The rule is rather simple, store what is changed, the User instance where we have to change the email address or the List where we have added an entry. If we do not store the correct object, or forget to store the changes, we will no longer have the data available when we restart the application.
Stored Data Format
We already mentioned that data is stored in a binary format. If you compare it with a database with the very strict format of tables and columns, and even with NoSQL solutions that still have some structure, it can be a bit awkward that you don't need to define any structure at all with MicroStream. You store a Java instance and it works all the time, with any kind of instance as there is no requirement on interfaces, annotations that define a mapping, or DSL like SQL queries.
Every time MicroStream writes some data, it just appends it to the existing structure. This ensures the writing is performed as fast as possible. As mentioned already, you can configure multiple channels so that storing the data happens in multiple threads that each performs a part of the work.
Since data is only appended, the disk usage would only increase and a lot of old data is kept that is no longer needed. This would mean that the startup would become very slow as it needs to find out which data is still relevant and what can be ignored. For that reason, a house holding process is running in combination with the Storer that writes the data. It checks which of the old data block became obsolete and can be removed. It makes sure that the data is kept manageable over time. The amount of time this householding process can take the time of the Storer Thread can be configured but has a reasonable default.
Lazy data
You might not need all the data available in memory all the time. Or maybe the data set became too large to keep in memory.
If we consider the use case of customers and the orders they have placed, if we create or update orders for customer A, we are not interested in the orders of customer B.
MicroStream provides for this purpose the class Lazy. The decision was made to require explicit indication from the developer when you need Lazy loaded data and when the data in the Object graph can be cleaned. Just as you need to explicitly define what needs to be stored and don't rely on some proxy handling and dirty checks to determine what needs to be stored again.
When your Object Graph contains the following definition
private Lazy<List> stringData = Lazy.Reference(new ArrayList());
The data, the list of strings in this example, is not loaded when the StorageManager is started. Only when we explicitly access the object within a Lazy reference, the data is retrieved.
stringData.get().size();
It is like the Schrödinger's cat thought experiment, as long as you don't open the box and explicitly ask for the status, like the size of the ArrayList, the status of that list is not known by the JVM.
Once you no longer need the Lazy loaded data, you can remove them from memory again through the clear() method. Also important to know that when your application is under memory stress, the LazyReferenceManager of MicroStream can also decide the free Lazy references so that the Garbage Collection can free some memory for your process.
Coming back to the example of the Customers and the orders, by carefully designing your object graph, you can make sure that you can load only those orders that you need.
private Map<String, Lazy<List>> ordersByCustomer; private Map<YearMonth, Lazy<List>> ordersByMonth;
If you assign an Order once to the Customer identification and once based on the Month the order was placed, you can retrieve it efficiently either by the customer reference or the month to create a summary for example.
Storing Data
In summary, the MicroStream framework can serialize an Object graph to the storage by indicating a certain root object that can be used to traverse the entire graph. The entire root object is normally only stored when it creates the storage for the first time and populates it with the data found in the JVM. Afterward, only changes detected by the Lazy evaluator are stored.
This means that you need to provide the parent object with the changes to the StorageManager instance and that it will detect the changed java instance references and only store these. This ensures that we make efficient use of the space where the data is stored.
When data is serialised, it is appended to the file and a custom file collection algorithm constantly keeps track of the instances in the storage and removes those that are no longer needed since there is a more recent version of the instance stored.
When you have a very large dataset, with the help of the Lazy object of MicroStream, it is possible to load only parts of the object graph. This allows you to make efficient use of the JVM memory and only load the data that you need for a certain request and remove it afterward from the memory.
Resources
- MicroStream Reference manual for Storing data
- MicroStream Reference manual for Lazy loading
- MicroStream Website
- June 22, 2022
- 6 min read
Rudy loves to create (web) applications with the Jakarta EE platform and MicroProfile implementations. Currently, he is a Developer Advocate for MicroStream. He has implemented various projects in a team for customers, helped various Open Source projects (Payara, MicroProfile, PrimeFaces, DeltaSpike, Apache Myfaces, ...), and supported Developers and teams. He is also working around Web Application Security using OAuth2, OpenId Connect, and JWT.







Comments (0)
No comments yet. Be the first.