


SummarizingTokenWindowChatMemory: Enhancing LLM’s Conversations with Efficient Summarization
- March 03, 2025
- 6 min read
LLM chat models have become an integral part of many applications today. We are all experimenting and exploring the best ways to utilize them effectively. For Java developers, LangChain4j has been an incredible tool in this journey.
By design, most available APIs, such as ChatGPT and Gemini, operate in a fire-and-forget mode. They don't retain previous interactions, meaning every request is treated as a completely new one.
However, for a smooth and engaging conversation, maintaining context is crucial---otherwise, the interaction becomes disjointed and frustrating. The common solution is to pass previous messages along with each new prompt, allowing the LLM to infer context. This is where the chat memory concept comes in.
That said, every conversation has a context window , which limits the maximum number of tokens that can be processed. We can't pass an unlimited number of tokens in a prompt. As conversations grow longer, they consume more resources, making it necessary to find efficient ways to manage and evict older messages.
LangChain4j already provides two types of memory eviction policies:
- MessageWindowChatMemory -- This approach keeps track of a fixed number of recent messages, discarding the oldest ones when the limit is reached.
- TokenWindowChatMemory -- Instead of counting messages, this method monitors the total number of tokens used and removes older messages when the token count exceeds a predefined threshold.
These memory policies help optimize resource usage while ensuring conversations remain coherent and user-friendly.
While both approaches are effective, I wondered why not add a third approach ---one that summarizes old messages rather than removing them. This idea led me to experiment and eventually implement SummarizingTokenWindowChatMemory .
SummarizingTokenWindowChatMemory
The core idea behind SummarizingTokenWindowChatMemory is straightforward:
- Monitor Chat Tokens: The system tracks the number of tokens used in a conversation.
- Trigger Summarization: The summarization process activates when the token count reaches a predefined threshold.
- Generate a Summary: Instead of storing full conversation logs, a summarizer condenses key information into a succinct, meaningful summary.
- Replace Old Messages: The summarized content replaces older messages, ensuring the conversation remains within token limits while maintaining continuity.
Let's look at the code:
package ca.bazlur.chefbot.ai;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.SystemMessage;
import dev.langchain4j.internal.ValidationUtils;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.model.Tokenizer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import dev.langchain4j.store.memory.chat.InMemoryChatMemoryStore;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
@Slf4j
public class SummarizingTokenWindowChatMemory implements ChatMemory {
private final Object id;
private final int maxTokens;
private final Tokenizer tokenizer;
private final ChatMemoryStore store;
private final Summarizer summarizer;
private SummarizingTokenWindowChatMemory(Builder builder) {
this.id = ValidationUtils.ensureNotNull(builder.id, "id");
this.maxTokens = ValidationUtils.ensureGreaterThanZero(builder.maxTokens, "maxTokens");
this.tokenizer = ValidationUtils.ensureNotNull(builder.tokenizer, "tokenizer");
this.store = ValidationUtils.ensureNotNull(builder.store, "store");
this.summarizer = ValidationUtils.ensureNotNull(builder.summarizer, "summarizer");
}
@Override
public Object id() {
return id;
}
@Override
public void add(ChatMessage message) {
// Pull existing messages from store
List<ChatMessage> messages = new ArrayList<>(store.getMessages(id));
// If it's a system message, handle "replace existing system message" logic
if (message instanceof SystemMessage) {
Optional<SystemMessage> maybeSystem = findSystemMessage(messages);
if (maybeSystem.isPresent()) {
if (maybeSystem.get().equals(message)) {
// Same system message, do nothing
return;
} else {
// Remove old system message so we can replace with new one
messages.remove(maybeSystem.get());
}
}
}
// Add the new message
messages.add(message);
// Enforce capacity by summarizing older messages if needed
ensureSummarizedCapacity(messages);
// Update store
store.updateMessages(id, messages);
}
@Override
public List<ChatMessage> messages() {
// Return a copy of messages from store
List<ChatMessage> messages = new ArrayList<>(store.getMessages(id));
// (Optional) ensure capacity here again, if you want to guarantee it every time
ensureSummarizedCapacity(messages);
return messages;
}
@Override
public void clear() {
store.deleteMessages(id);
}
private void ensureSummarizedCapacity(List<ChatMessage> messages) {
int currentTokenCount = tokenizer.estimateTokenCountInMessages(messages);
if (currentTokenCount <= maxTokens) {
return; // We are within capacity
}
// If we exceed tokens, let's summarize the older messages (except system msg & possibly the newest).
// 1) Separate out the system message if present at index 0.
// 2) Summarize everything from startIndex...up to near the end,
// leaving maybe the last user or assistant message "unsummarized" for context.
// 3) Insert the summary as a single message, then re-check capacity.
// First, handle any system message
Optional<SystemMessage> maybeSystem = findSystemMessage(messages);
maybeSystem.ifPresent(messages::remove);
// Now we can work with the non-system messages
int startIndex = 0;
int endIndex = messages.size() - 1; // Leave the last message for context
// Don't try to summarize if we have 2 or fewer messages
if (endIndex - startIndex <= 1) {
// If we can't summarize, fall back to just removing oldest messages
removeOldestUntilFit(messages);
// Re-add system message if we had one
maybeSystem.ifPresent(messages::addFirst);
return;
}
// Get the messages to summarize (everything except maybe system & last)
List<ChatMessage> toSummarize = new ArrayList<>(messages.subList(startIndex, endIndex));
// Generate the summary
String summary = summarizer.summarize(toSummarize);
// Replace the summarized messages with the summary
messages.subList(startIndex, endIndex).clear();
messages.add(startIndex, SystemMessage.from("Previous conversation summary: " + summary));
// Re-add system message if we had one
maybeSystem.ifPresent(messages::addFirst);
// If we're still over capacity, remove oldest messages (after any system message)
if (tokenizer.estimateTokenCountInMessages(messages) > maxTokens) {
removeOldestUntilFit(messages);
}
}
private void removeOldestUntilFit(List<ChatMessage> messages) {
// Keep system message if present
Optional<SystemMessage> maybeSystem = findSystemMessage(messages);
maybeSystem.ifPresent(messages::remove);
// Remove oldest messages until we're under token limit
while (!messages.isEmpty() && tokenizer.estimateTokenCountInMessages(messages) > maxTokens) {
messages.removeFirst();
}
// Re-add system message if we had one
maybeSystem.ifPresent(messages::addFirst);
}
private Optional<SystemMessage> findSystemMessage(List<ChatMessage> messages) {
if (!messages.isEmpty() && messages.getFirst() instanceof SystemMessage) {
return Optional.of((SystemMessage) messages.getFirst());
}
return Optional.empty();
}
public static Builder builder() {
return new Builder();
}
public static class Builder {
private Object id;
private Integer maxTokens;
private Tokenizer tokenizer;
private ChatMemoryStore store = new InMemoryChatMemoryStore();
private Summarizer summarizer;
public Builder id(Object id) {
this.id = id;
return this;
}
public Builder maxTokens(Integer maxTokens, Tokenizer tokenizer) {
this.maxTokens = maxTokens;
this.tokenizer = tokenizer;
return this;
}
public Builder chatMemoryStore(ChatMemoryStore store) {
this.store = store;
return this;
}
public Builder summarizer(Summarizer summarizer) {
this.summarizer = summarizer;
return this;
}
public SummarizingTokenWindowChatMemory build() {
return new SummarizingTokenWindowChatMemory(this);
}
}
}
The SummarizingTokenWindowChatMemory class manages chat messages, ensuring they stay within a specified token limit by summarizing older messages when necessary. It uses an OpenAiTokenizer to estimate token counts and a Summarizer to generate summaries.
The class also handles system messages separately, preserving them during summarization. The \Builder\ class provides a convenient way to construct SummarizingTokenWindowChatMemory instances with the required dependencies.
Now, let's work on the Sumerizer.
The Summarizer Interface
At its core, OpenAILLMSummarizer implements the Summarizer interface:
import dev.langchain4j.data.message.ChatMessage;
import java.util.List;
public interface Summarizer {
String summarize(List<ChatMessage> messages);
}
This provides a contract for any summarization strategy.
Summarization Logic
The main implementation, OpenAILLMSummarizer , is responsible for processing chat history and condensing it into a summary:
package ca.bazlur.chefbot.ai;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.SystemMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.V;
import java.util.List;
public class OpenAILLMSummarizer implements Summarizer {
private final int desiredTokenLimit;
private final SummarizerAssistant assistant;
public OpenAILLMSummarizer(OpenAiChatModel openAiChatModel, int desiredTokenLimit) {
this.desiredTokenLimit = desiredTokenLimit;
assistant = AiServices.builder(SummarizerAssistant.class)
.chatLanguageModel(openAiChatModel)
.build();
}
@Override
public String summarize(List<ChatMessage> messages) {
StringBuilder promptBuilder = new StringBuilder("Summarize the following conversation: \n");
for (ChatMessage msg : messages) {
if (msg instanceof UserMessage) {
promptBuilder.append("User: ").append(((UserMessage) msg).contents()).append("\n");
} else if (msg instanceof AiMessage) {
promptBuilder.append("Assistant: ").append(((AiMessage) msg).text()).append("\n");
} else if (msg instanceof SystemMessage) {
promptBuilder.append("System: ").append(((SystemMessage) msg).text()).append("\n");
}
}
String summary = assistant.summarize(promptBuilder.toString(), desiredTokenLimit);
return summary.trim();
}
}
- Constructs a structured prompt containing key user, AI, and system messages.
- Invokes the SummarizerAssistant , which interacts with OpenAI's language model to generate the summary.
LLM Summarization
The SummarizerAssistant provides an AI-driven summarization method:
interface SummarizerAssistant {
@dev.langchain4j.service.UserMessage("""
You are a helpful assistant summarizing past conversation turns for a chatbot.
Your goal is to create a concise and informative summary of the provided conversation history,
focusing on key information relevant to continuing the conversation.
Pay close attention to user preferences, requests, and any decisions they have made.
Also note any specific topics or tasks discussed. Be sure to retain information that might be needed
to fulfill a user request or provide a relevant response.
The summary should be under {desiredTokenLimit} tokens and written in a clear, natural language style.
Avoid simply listing the turns. Instead, synthesize the information into a coherent narrative.
Conversation History:
{message}
""")
String summarize(@V("message") String messages, @V("desiredTokenLimit") int desiredTokenLimit);
}
This mechanism:
- Calls an LLM model (e.g., OpenAI's GPT) to generate concise summaries.
- Ensures that the summarized conversation remains within a predefined token limit.
Why This Matters
The SummarizingTokenWindowChatMemory approach effectively manages long conversations while staying within the constraints of an LLM's context window. The chatbot can retain essential details by summarizing older exchanges, ensuring coherence without exceeding token limits.
This results in a more fluid and engaging user experience, where the chatbot can "remember" and refer back to past interactions naturally. Additionally, it optimizes efficiency by reducing the amount of text processed with each request, potentially leading to faster response times and lower costs.
This makes it particularly valuable when maintaining conversational history, which is crucial for customer support, complex problem-solving, or multi-turn discussions.
That said, this approach isn't without its challenges. The very nature of summarization means that some details---especially infrequent ones---might get lost in the process. This could occasionally impact the chatbot's ability to deliver the most precise or personalized responses.
Moreover, the summarization step itself adds computational overhead, and its effectiveness heavily depends on the prompt design and the capabilities of the underlying LLM. Another potential issue is contextual drift ---over multiple rounds of summarization, the chatbot's understanding of the conversation could gradually shift away from its original meaning.
These trade-offs must be carefully weighed when deciding whether this approach is the right fit for a given application.
Conclusion
To test its functionality, I created a simple chatbot that suggests recipes.
The chatbot will ask you a few questions and recommend a recipe based on your responses.
As the conversation progresses, the chatbot will start summarizing older messages to retain essential context while staying within the allowed token threshold if the token limit is exceeded.
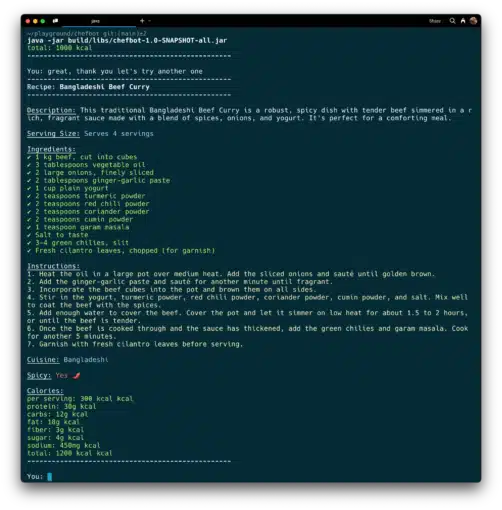
The source code is here: https://github.com/rokon12/chefbot
- March 03, 2025
- 6 min read
A N M Bazlur Rahman is a Software Engineer with over a decade of specialized experience in Java and related technologies. His expertise has been formally recognized through the prestigious title of Java Champion. Beyond his professional commitments, Mr. Rahman is deeply involved in community outreach and education. He is the founder and current moderator of the Java User Group in Bangladesh, where he has organized educational meetups and conferences since 2013. He was named Most Valuable Blogger (MVP) at DZone, one of the most recognized technology publishers in the world. Besides DZone, he is an editor for the Java Queue at InfoQ, another leading technology content publisher and conference organizer, and an editor at Foojay.io, a place for friends of OpenJDK. In addition, he has published five books about the Java programming language in Bengali; they were bestsellers in Bangladesh. He earned his bachelor's degree from the Institute of Information Technology, University of Dhaka, Bangladesh, in Information Technology, majoring in Software Engineering. He currently lives in Toronto, Canada.










Comments (0)
No comments yet. Be the first.