


Benchmark JDBC Connectors and Java 21 Virtual Threads
- January 23, 2024
- 6 min read
Why should Java and database developers care about Virtual Threads? Developers can write faster and more resource efficient applications without having to refactor synchronous code a.k.a. "imperative") JDBC code into asynchronous (a.k.a "reactive") code that is hard to create, debug and maintain.
Writing scalable network code is always difficult. Synchronous APIs can't be scaled beyond a certain point because they can block when performing I/O operations, which in turn block the thread until the operation is ready. For example, if you try to read data from a socket when no data is available, the thread will freeze until data becomes available. Threads are also an expensive resource on the Java platform, so we don't want to force them to wait for I/O operations to complete. To avoid these limitations, we typically use asynchronous or reactive I/O frameworks such as Project Reactor, RxJava, or Vert.x and connectors like R2DBC. These frameworks allow us to write code that doesn't block a thread during an I/O operation, but instead uses a callback or event notification to notify the code when the I/O operation is complete or ready.
Java introduced Project Loom, creating a new type of thread called virtual threads. This API became generally available in Java 21. JEP 353 and JEP 373 reimplemented the synchronous Java networking APIs in preparation for Loom. When executed in a virtual thread, I/O operations that don't complete immediately cause the virtual thread to "park". The virtual thread is reactivated when the I/O operation is ready. This allows us to write synchronous code and avoid I/O limitations.
What is synchronous coding vs asynchronous coding?
To more deeply understand what this means for developers, let's back up a little and recap. Synchronous coding is a style where the developer writes code that defines a sequence of commands for the computer to perform, which is much easier to reason about and debug. It's about describing how things should be done. The control flow is explicit and step-by-step, often using loops, conditionals, and other control structures. State is manually managed and updated by the developer. The state is usually local and changes are made imperatively.
Asynchronous coding is a completely different programming paradigm for building systems that are responsive to events or changes in data. It focuses on defining what should happen in response to certain stimuli or data flows. The control flow is driven by data/events. It uses data streams and the propagation of change (i.e., reacting to inputs). State changes are often handled through data streams and bindings, which can automatically propagate changes through the system. Reactive programming can have a steeper learning curve due to its abstract nature and the requirement to think in terms of data flows and events.
| Synchronous/Blocking | Asynchronous/Non-Blocking | |
|---|---|---|
| Programming Model | Explicit sequence of commands | Respond to data and events |
| Control Flow | Loops/conditions | Data streams/event propagation |
| State Management | Manual | Often built-in |
| Ideal Workload | General, Control-oriented | Event-Driven |
| Learning Curve | Approachable | Difficult |
| Performance | Predictable, higher latency due to blocking I/O | Less predictable, lower latency since I/O is not blocked |
| Debugging | Approachable | Difficult |
| Ecosystem | Mainstream | Niche |
Of course, the choice between imperative and reactive programming depends on the specific needs of the application and the preferences of the developer, but as the JVM ecosystem adopts support for virtual threads, it will simplify developers lives significantly in the pursuit of lower latency and more resource efficient applications.
Virtual threads still have some limitations that may result in "pinning" virtual threads (i.e. making virtual threads wait as platform threads would). A JVM virtual thread gets pinned when it encounters a method that does not support the unmounting and mounting process, for instance: file IO operation or JNI (Java Native Interface) calls to the underlying operating system. The MariaDB Java connector 3.3.0 has been improved in order to avoid those I/O cases, and therefore, virtual thread compatibility.
Benchmark
The concept is nice, but what is the impact in reality? Let's do a benchmark test to find out.
We are using 2 DigitalOcean droplets with Ubuntu 22.04 16GB 4cpu, one with MariaDB Server 10.11 and another acting as a client.
The benchmark uses OpenJDK's JMH, to execute 100 queries with a pool of 16 connections, either using virtual threads and "platform" threads (platform threads is the new name for Java-wrapped OS threads).
The benchmark runs different types of queries:
- "SELECT 1" to test for minimal result-set
- "DO 1" to test commands that have small results, like insert commands without having a database doing real inserts.
- SELECT one row with 100 integer fields
- SELECT 1000 rows of one integer field
The benchmark source code is available on GitHub and is rather straightforward. Here's an example using the "SELECT 1" command:
@Benchmark
public void Select1Platform(MyState state, Blackhole blackHole) throws InterruptedException {
try (var executor = Executors.newCachedThreadPool()) {
executeSelect1(state, executor, blackHole);
}
}
@Benchmark
public void Select1Virtual(MyState state, Blackhole blackHole) throws InterruptedException {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
executeSelect1(state, executor, blackHole);
}
}
private void executeSelect1(MyState state, ExecutorService executor, Blackhole blackHole) throws InterruptedException {
IntStream.range(0, state.numberOfTasks).forEach(i -> executor.submit(() -> {
try (var conn = state.pool.getConnection()) {
try (Statement stmt = conn.createStatement()) {
try (ResultSet rs = stmt.executeQuery("select 1")) {
rs.next();
blackHole.consume(rs.getInt(1));
}
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}));
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
}
Notice how platform threads are created and used (pool) vs how virtual threads are (no pool).
Here are the benchmark results:

As expected, virtual threads permit way more operations per second.
To be fair, results using the platform pool of threads can perform better: I've run this test with different pool sizes, to see if the results differ. The best performance using platform threads was achieved when pool has 4 connections:

When using platform threads, having a smaller pool (4 connections vs 16) avoids context switching making performance better. Expectations when dealing with virtual threads are more natural: context switching for virtual threads is way less costly, so having more connections to pool just permits executing more queries simultaneously.
I've run the benchmark using 16 connections with the MySQL connector too, for the MySQL Connector the performance difference wasn't that big:
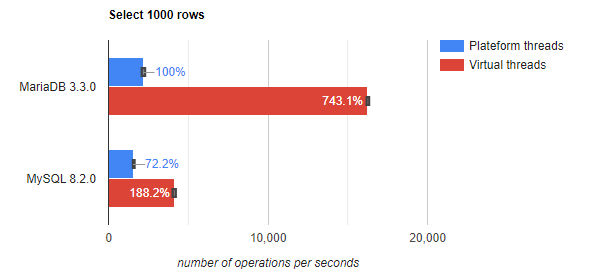
Virtual threads are incredible but still have some limitations. For example there's a limitation named 'pinning'—making a virtual thread blocking like a platform thread (tip: pinning can be logged using the Java option -Djdk.tracePinnedThreads=full). At the time of writing, the MySQL connector still makes intensive use of synchronized methods, making it susceptible to issues related to pinning. This explains the difference between the performance of the MariaDB connector and MySQL's connector.
R2DBC comparison
While at it, here is the benchmark achieved comparing a platform/virtual threads with JDBC connector and MariaDB R2DBC connector. (Results differ to the previous one, because this was run on 2 others machines with different ping)

R2DBC is a non-blocking connector based on specifications that differ from JDBC. This benchmark confirms that R2DBC presents a huge improvement compared to traditional threads. The main advantage of R2DBC is that it can already be used with frameworks like Spring Data R2DBC, but in terms of performance, virtual threads dethrone R2DBC.
Conclusion
Virtual threads promise better performance, specifically around I/O limitations. Goal achieved.
R2DBC is still in competition for now, because lots of frameworks still use synchronized methods, but that is improving as time passes and since dealing with sync code is way more maintainable, I really think virtual threads are the future.
Another point is correct pool sizing. This has always been a pain to configure. At some point, using more connections only results in less operations per second due to context switching. Using virtual threads changes this for the better.
Next Steps
- Download the latest Java connector, plus MariaDB Community Server software, Docker images, and more from mariadb.com/downloads
- Need help or want to connect? MariaDB is here to help with Remote DBA, Expert Technical Support, Migration, Training, Consulting and more.
- Contribute, learn from, and connect with your MariaDB community on Slack, DBA Stack Exchange, and the Community Knowledge Base.
- Learn more about Community Server on MariaDB.com
- Learn more about Java 21 and Virtual Threads (JEP)
- Learn how the popular Jetty app server is reacting to virtual threads
- Learn how Spring Boot 3.2 is reacting to virtual threads
- January 23, 2024
- 6 min read
Software Engineer at MariaDB Corporation
Kubernetes Product Manager at MariaDB










Comments (0)
No comments yet. Be the first.