

Context Is a Budget — Eight levers and three workflow patterns
- May 22, 2026
- 12 min read
- A. Context engineering — scope your asks
- B. Prompt caching — order matters
- C. Tool & MCP hygiene — every schema is a tax
- D. Custom instructions & skills — codify it once
- E. Model routing — start cheap, escalate when stuck
- F. Output discipline — diffs, not novels
- G. Repo hygiene — what the indexer sees
- H. Observability — latency is your token meter
Eight levers and three workflow patterns that pay for themselves in a week.
A team of fifty developers can quietly burn $30,000 a month on AI coding assistants without anyone noticing. Premium-request quotas vanish by the third week. The bill arrives. Nobody has a story for where it went.
The cost is the obvious pain. The other two are sneakier:
- Latency. Bigger contexts take longer. The model thinks more, but you also wait more.
- Context rot. This is the surprising one. Anthropic and Chroma have both shown that as the context window fills up, model recall and reasoning degrade — even well inside the advertised window. The 200K-token model is genuinely worse at the 150K mark than at the 20K mark. More context is not free; past a point, it's actively harmful.
The mental model that fixes all three: stop treating context as a free buffet. Treat it as a budget you spend on every turn.
This post is a practical guide to spending it well: where the tokens actually go, eight levers that move the needle, and three workflow patterns that compound on top of them.
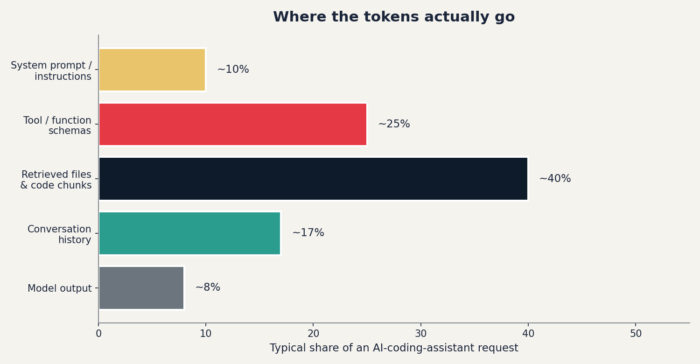
Where the tokens actually go
Every request to a coding assistant is a stack of buckets. The shape varies by tool and session, but it tends to look like this:
| Bucket | Typical share | Notes |
|---|---|---|
| System prompt / instructions | 5–15% | Boilerplate that's been copy-pasted for months |
| Tool / function schemas | 10–40% | Re-sent on every turn |
| Retrieved files & code chunks | 20–60% | The biggest lever, almost always |
| Conversation history | 10–30% | Grows linearly until you compact it |
| Model output | 5–20% | Verbose prose is expensive to produce and to read |
A few things to notice:
- Tool schemas dominate more than people expect. Five connected MCP servers can easily contribute 5,000–10,000 tokens to every request before you've typed a word. The model doesn't have to use the tool — the schema ships either way.
- Conversation history grows without bound. A 30-turn chat is paying for the first 29 turns on every new question, plus your fresh one.
- Output is small in volume but expensive per token. On most direct APIs, output tokens cost three to five times input tokens. A reply that says "Sure! Let me explain what I'm about to do…" before doing it is pure tax.
Rule of thumb: profile your own traffic before optimizing. The bucket dominating your sessions is rarely the one your gut says.
In a Copilot context, you can't see token counts directly — but you can see the symptom. Open Output → "GitHub Copilot Chat" and watch the ccreq lines: each one shows the model, latency, and request type per turn. When the same question takes three times longer in chat #2 than chat #1, you've just watched your token meter the entire time.
The Eight Levers
These aren't in priority order — they're in the order you'd naturally encounter them in a session. The first three (context, caching, tools) are about the request shape. The next three (instructions, model, output) are about how you talk to the assistant. The last two (repo, observability) are the foundations that make all of the others stick.

A. Context engineering — scope your asks
The single biggest waste in most AI workflows is asking vague questions of agent-mode chat with full codebase access. The agent dutifully explores, reads ten files to find the two it needed, summarizes them all, and then answers. You pay for every step.
Compare:
Bad: "Refactor the order confirmation email to use the new template engine."
The agent opens four files undersrc/main/java/com/example/demo/email/, readsWelcomeEmailService.javafor context it doesn't need, considers whether atemplates/resource directory should exist, and proposes a sprawling diff that renames a method on the way through.Good: "Refactor
#file:src/main/java/com/example/demo/email/OrderConfirmationService.javato callrenderon#file:src/main/java/com/example/demo/email/TemplateEngine.javainstead ofrenderLegacy. Keep behaviour identical."
The agent opens two files. The diff is three semantically meaningful lines. The whole turn is roughly a tenth of the cost.
Specificity is free. Every #file: (Copilot) or explicit path (Claude Code) you provide is a chunk the agent doesn't have to find. Every "keep behaviour identical" is a sentence of guard-rails that prevents a 200-line side quest.
Do this Monday: make #file: your default. Use agent-mode-with-broad-retrieval only when you genuinely don't know what you don't know.
B. Prompt caching — order matters
Every major provider supports prompt caching now. Anthropic and OpenAI both charge roughly 10% of base input cost for cache hits. Google's Gemini does it explicitly. The mechanism is the same: a stable prefix at the front of your prompt is cached after the first request and read back cheaply on subsequent ones.
The cost discipline is therefore about order:
[ tool definitions ] ← rarely change ┐
[ system prompt ] ← rarely changes │ cache these
[ skills / rules ] ← stable per repo ┘
[ retrieved files ] ← changes per task
[ conversation ] ← changes every turnStatic at the top, dynamic at the bottom. The longest stable prefix you can construct is the most cacheable one.
The classic anti-pattern is innocent-looking and brutal is to have dynamic values/variables part of your instructions, custom agent files. It will most likely busts the cache on every request. You will pay full price for the same 10 KB of preamble all day. The fix is to push dynamic content down into the user message or tail of the prompt.
Do this Monday: audit the first 200 tokens of your system prompts. Anything that changes per-request belongs further down.
C. Tool & MCP hygiene — every schema is a tax
Each connected tool ships its full JSON schema with every request. A typical MCP server with 8–15 tools costs 400–2,500 tokens per turn. Five servers connected? You may be paying 5,000–10,000 tokens per turn for tool definitions the model never invokes.
Treat MCP servers like browser extensions: useful, but only the ones you actually need today.
// .vscode/mcp.json — keep this short
{
"servers": {
"filesystem": { "command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem"] }
// disable github, playwright, brave-search, etc. when you don't need them
}
}The same discipline applies to the tools you build yourself. A tool that returns { id, summary } is cheap. A tool that returns a 50-field JSON object is expensive — the model re-processes all 50 fields on every turn it's referenced. Default to compact responses with optional ?expand=... for the rare caller that needs the rest.
Do this Monday: open MCP server list, disable everything you didn't actively use this week. Re-enable on demand.
D. Custom instructions & skills — codify it once
Anything you find yourself re-typing in chats belongs in an instructions file. The exact filename varies — .github/copilot-instructions.md, CLAUDE.md, AGENTS.md, Cursor Rules — but the principle is identical: write your team conventions once, commit them, and let every chat in the repo inherit them.
A small example is worth more than a long one:
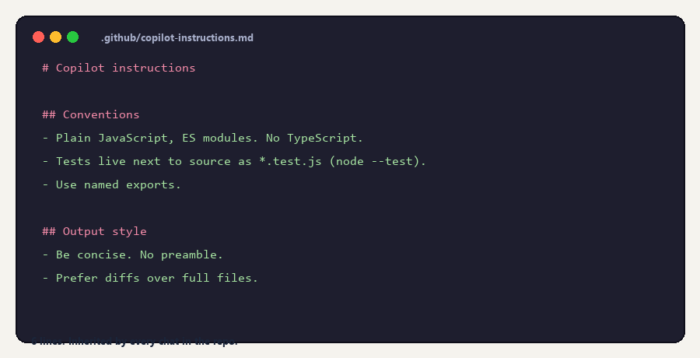
Six lines. Now no chat in this repo will propose Jest, no chat will dump a whole-file rewrite when a diff would do, and no chat will preface its answer with "Sure! Let me explain what I'm about to do…"
For stack-specific rules, use path-scoped instructions. In Copilot:
---
applyTo: "src/main/java/**/*.java"
---
# Test conventions for src/
- Use JUnit 5 via `mvn test`.
- Tests mirror the source tree under `src/test/java/...` as `<Name>Test.java`.This file is loaded only when a matching file is in scope. Repo-wide rules go in the global instructions; stack-specific rules go in scoped ones. Both are committed, both are versioned, both are team artifacts — not personal preferences buried in someone's IDE settings.
Do this Monday: check what you've typed into chat windows in the last week. Anything that reappeared more than twice is a candidate for an instructions file.
E. Model routing — start cheap, escalate when stuck
Routine tasks pick the most expensive model by default if you let them. You probably just paid 10× for the same answer.
A defensible default routing table:
| Task | Model | Multiplier (Copilot) |
|---|---|---|
| Inline completions, simple chat | Cheapest available (e.g. GPT-4.1) | 0× |
| Real coding work | Mid-tier (GPT-5 / Claude Sonnet) | 1× |
| Long-context refactor / agent mode | Mid-tier with long context | 1× |
| Genuinely hard reasoning | Top-tier (Claude Opus) | 10× |
The rule is: start cheap, escalate only when stuck. "Stuck" means you've tried the mid-tier model with good context and it's plainly missing the point — not "I want to feel sure," not "I have time to spare."
The math compounds. A team of fifty doing twenty agent runs each per day at 10× costs five times more than at 2× — for the same diffs, on most days.
Do this Monday: pin your default to the mid-tier. Make Opus a deliberate choice with a reason.
F. Output discipline — diffs, not novels
Every model has a "let me explain what I'm about to do" reflex. It's polite. It's also pure cost.
Same fix, two ways to ask:
"In
templateEngine.js, thewelcometemplate is missing an exclamation mark. Show me the updated file."
→ 30 lines back. (With a 600-line file, 600 lines.)"In
templateEngine.js, thewelcometemplate is missing an exclamation mark. Reply with a unified diff only, no commentary."
→ 5 lines back.
Output tokens are typically three to five times the price of input tokens on direct APIs. In a per-request model like Copilot's, verbose output still hurts: it increases latency, fills the context for subsequent turns, and evicts earlier useful content sooner.
The leverage is in the system prompt. Two lines in copilot-instructions.md make every chat in the repo behave better forever:
- Be concise. No preamble.
- Prefer diffs over full files.Do this Monday: add those two lines.
G. Repo hygiene — what the indexer sees
The indexer that powers retrieval respects .gitignore. Tighten it.
+target/
+*.class
+*.jar
+.idea/
+*.iml
*.logImportant gotcha: if a file is already tracked in git, adding the path to .gitignore does not untrack it — the indexer still sees it. You also need:
git rm --cached target/demo-0.0.1-SNAPSHOT.jarFor secrets, fixtures, and vendored deps, use content exclusions at the org/repo level (most coding-assistant providers expose this).
The other half of repo hygiene is summary comments at the top of each module:
// TemplateEngine — central renderer. Use render(id, data) for new emails.
// renderLegacy(id, data) is deprecated and only used by OrderConfirmationService.
// Templates registered: welcome, order_confirmation_v2.Three lines, ~50 tokens. Now "what does the template engine do?" can be answered without reading the rest of the file. A 200-token summary at the top of each module beats re-reading 5,000 tokens of code, every single time.
Do this Monday: git rm --cached whatever shouldn't be indexed; add three-line summaries to your top-of-mind modules.
H. Observability — latency is your token meter
You can't see Copilot's token counts. You don't need to. Use the proxy you already have:
| Reply latency | ≈ Input tokens | |
|---|---|---|
| < 5 s | 20 s | Near limit — start a new chat |
When the same question takes three times longer in your fourth chat than in a fresh one, you've just watched your context bloat in real time. The fix is "new chat with a summary," not "wait it out."
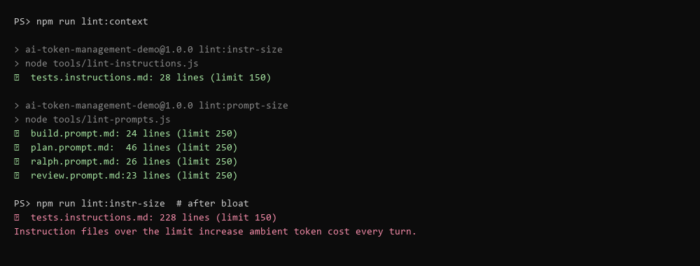
You can also lint for context bloat the same way you lint for bundle size. A 30-line script in CI is enough to catch the most common regressions:
// fail if any .github/instructions/*.md exceeds 150 lines
import { readdir, readFile } from "node:fs/promises";
const files = (await readdir(".github/instructions")).filter(f => f.endsWith(".md"));
let failed = false;
for (const f of files) {
const lines = (await readFile(`.github/instructions/${f}`, "utf8")).split("\n").length;
console.log(`${lines > 150 ? "❌" : "✅"} ${f}: ${lines} lines`);
if (lines > 150) failed = true;
}
if (failed) process.exit(1);Wire it into CI and context bloat stops accumulating silently across PRs.
Do this Monday: put a stopwatch next to your editor for one day. Count "Amsterdam" (not Mississippi's) . You'll know which chats to rotate.
Three workflow patterns that compound
The eight levers above shrink the cost of an individual turn. These three patterns shrink the number of expensive turns. Apply them on top.

1. The Ralph Wiggum loop
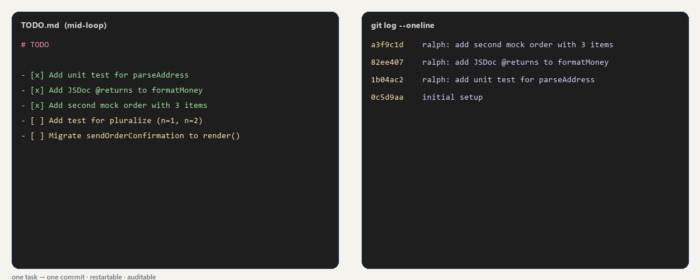
Named after the Simpsons character whose superpower is relentless dumbness. The recipe is unglamorous on purpose:
- Write a
TODO.mdwith checkbox tasks. - Open agent-mode chat with a cheap model.
- Tell it: "Read
TODO.md. Pick the first unchecked item. Implement only that. Runnpm test. If green, check the box and commit. Pick the next. Repeat."
That's it. The agent burns through the list one item at a time.
Why it works:
- Each iteration starts with a small, fresh context. The chat history isn't growing the way it would in a free-form conversation.
- State lives on disk (
TODO.mdand git commits), not in conversation tokens. - A cheap model is good enough, because each task is small and self-contained.
- It's restartable. Kill the chat halfway, start a new one, run the prompt again — it picks up where it left off.
After it runs, git log --oneline reads like a changelog: one commit per task, message starts with the task title, easy to revert any one step. Compare with the typical "fix things" mega-commit and you'll never go back.
2. Auto-compact
Most assistants don't compact aggressively on their own. You have to drive it.
When a chat hits 60–80% of the context window (you'll know — replies start to crawl), stop and ask:
Summarize what we've discussed: the goal, files we've touched, decisions made, open questions, and the next step. Keep it under 300 words and use bullet points.
Save the output to plan.md. Open a brand new chat. Attach it:
Continue from
#file:plan.md. The next step is…
The new chat's first request is dramatically smaller than the old chat's last one. The model picks up the thread without missing a beat. Roughly: a 4 KB summary keeps 95% of the signal at 3% of the cost.
The bonus pattern: that summary file becomes a stable, cacheable prefix. Every future chat that references it benefits from prompt caching on top of the compaction. Two compounding wins for one summarization.
If you are interested in a sofisticated implementation of compaction, check this skill which is used by some of the custom agents.
Rule of thumb: one task per chat. New task → new chat with summary attached.
3. Planner → Implementer → Reviewer (agent handover)
This is the one that changes how features get built. Three short, focused chats with three different model choices and one shared artifact:
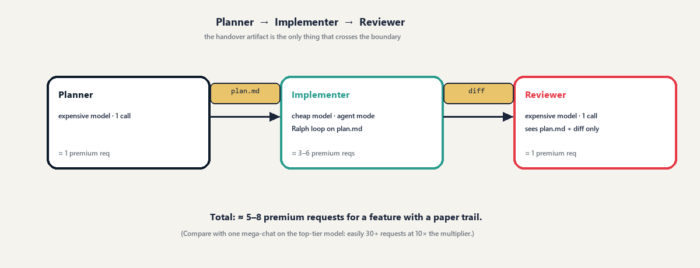
- Planner — expensive model, one call. Reads the feature request, produces
plan.mdwith goal, acceptance criteria, tasks, files expected to change, out-of-scope items, and risks. No code yet. - Implementer — cheap model, agent mode, fresh chat. Sees only
plan.md. Runs a Ralph loop on it: pick first unchecked task, implement, test, check the box, commit, repeat. - Reviewer — expensive model, fresh chat. Sees only
plan.mdand the diff. Marks each acceptance criterion PASS or FAIL, lists bugs, smells, out-of-scope edits. Ends withVERDICT: APPROVEorVERDICT: REQUEST CHANGES.
Three chats, ~5–8 premium requests total for an end-to-end feature. Compare with one mega-chat using the most expensive model the whole way: easily 30+ requests at 10× the multiplier.
The crucial discipline: the handover artifact (plan.md, the diff, the review notes) is the only thing that crosses the boundary. Never chat history. That's how you keep each agent's context small, focused, and cheap.
The Monday checklist
Pin this to your team's wiki. Take what's useful, ignore the rest.
Repo setup
- [ ] Add a top-level instructions file (
copilot-instructions.md,AGENTS.md,CLAUDE.md, or your tool's equivalent) with build, test, lint, conventions, and output-style rules. - [ ] Add path-scoped instruction files for stack-specific rules (e.g. test conventions under
src/). - [ ]
.gitignorebuild outputs, snapshots, and large fixtures.git rm --cachedanything already tracked. - [ ] Add three-line "what does this module do" summary comments to your top 10 modules.
- [ ] Add a CI lint that fails if instruction files exceed ~150 lines or prompt files exceed ~250 lines.
Per-session habits
- [ ] Disable MCP servers you don't need this session. Re-enable on demand.
- [ ] Default to a mid-tier model. Escalate to a top-tier model only when stuck — and only with a reason.
- [ ] Use
#file:(or your tool's equivalent) instead of broad-retrieval / agent mode for scoped tasks. - [ ] Ask for diffs, not full files.
- [ ] Start each new task in a fresh chat.
- [ ] When responses start to crawl (~60% context), summarize to a
plan.mdand continue in a new chat.
Workflow patterns to try this week
- [ ] Run a Ralph loop on a
TODO.mdof small chores. - [ ] Use the planner / implementer / reviewer split for one real feature. Notice the request count.
- [ ] Treat latency as your token meter. Count Amsterdam for one day.
Closing
The mindset shift is small and the wins are not.
Prompt engineering used to be about clever phrasing. Context engineering — what this post was really about — is about what's in the window and what isn't. Smaller prompts, fewer tools, scoped retrieval, summaries instead of histories, cheap models for cheap work, expensive models for the rare hard parts.
None of it is novel. None of it is hard. Most teams don't actually have a token problem; they have a discipline problem. The levers are boring. The compounding is real: a team that adopts even half of the above will see latencies fall, premium-request burn drop noticeably, and, counterintuitively, answer quality go up, because the model isn't drowning in irrelevant context.
One sticky line to take with you:
The worst tokens are the ones you're paying for and not noticing.
Watch your ccreq lines. Count Amsterdams. Spend the budget like it's yours.
- May 22, 2026
- 12 min read
Technology enthusiast | Agentic AI | Architect | Programmer | Cloud Native | Blogger | Speaker








Comments (2)
fantaman
2 months agoWhat does "Count Amsterdam" mean actually?
Soham
2 months agoI just didn't want to use "count Mississippi", so used "count Amsterdam" instead 😊