

Distributed Cache Invalidation Patterns
- April 21, 2026
- 7 min read
Caching is one of the most powerful tools developers have at their disposal for optimizing application performance. Caching systems can significantly reduce latency and reduce the load on databases or external systems by storing frequently accessed data as close as possible to the application layer. The result? Improved responsiveness and overall system usability.
In small monolithic applications, cache management is usually very simple. A service retrieves data from a database, stores it in memory, and fulfills subsequent requests by retrieving the data directly from the cache. When the data changes, the cache key is invalidated or updated.
Things get complicated—and not just a little—when the system evolves into a distributed architecture.
Modern, cloud-native applications run multiple service instances behind load balancers. Each instance can maintain its own local cache, and the system may include shared distributed caches such as Redis or Memcached. In these environments, maintaining cache consistency and coherence becomes much more difficult.
If one node updates a record while other nodes continue to serve stale records from the cache, users may notice inconsistent behavior across requests. The system may remain fast, but correctness is no longer guaranteed.
This is the main reason why cache invalidation is often considered one of the most complex issues to manage in distributed infrastructures.
In this article, we will explore several practical models for managing cache invalidation. We will focus on the different strategies developers can apply in real-world systems using tools such as Spring Boot, Redis, and Apache Kafka.
Why Cache Invalidation Becomes Hard in Distributed Systems
To better understand why cache invalidation in a distributed system is so complex, let’s consider how modern systems are typically implemented.
Most cloud applications, built according to 12-factor principles, run multiple instances of the same service to ensure scalability and fault tolerance. Each instance handles requests independently, and these applications often maintain a local in-memory cache to avoid repeated calls to the database or external services.
Let’s imagine a simple service tasked with retrieving information about products from the database:
- A request arrives at instance A
- The product data is loaded from the database
- The result is stored in the local cache
- Future requests are handled using the data in the cache
Now, let’s suppose that another request updates the product information. If the update occurs on instance B, only that instance is aware of it and will therefore invalidate its own cached record. Instance A might still retain the old value in memory.
The result? When the load balancer routes requests across instances, users might receive different responses depending on which node handles the request.
The following diagram shows and explains the current situation:
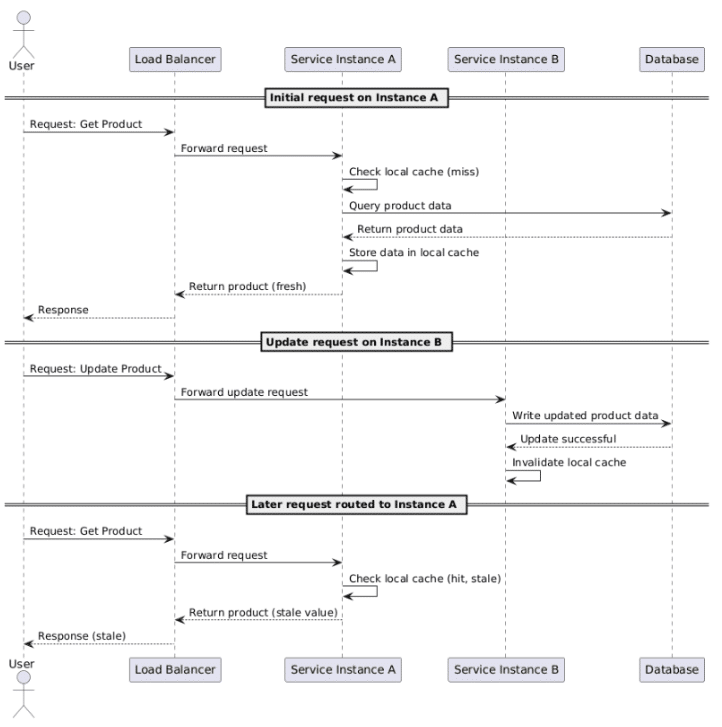
This problem becomes even more complex when the architecture includes multiple cache levels, such as:
- In-memory caches within application instances
- Distributed caches shared across services
- CDN or edge caches
Ensuring that all these levels remain consistent is no trivial matter. As systems scale and become increasingly distributed, we must balance competing priorities: data freshness, data consistency, system performance, and operational complexity.
The solution? A good cache invalidation strategy should minimize stale data while keeping the system scalable and resilient. Let’s see how to do that.
Time-Based Expiration (TTL)
One of the simplest strategies for cache invalidation is to apply a time-based expiration, often implemented using a TTL (time-to-live).
With this strategy, the system allows cached values to expire after a predefined time-to-live (TTL) rather than actively invalidating records in the cache when the data changes. This is a simplified approach that avoids the need for distributed coordination among service instances.
For example, a Redis-based cache in a Spring Boot application can be configured with a default expiration time.
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(10));
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(config)
.build();
}
}
Entries logically expire after ten minutes. Redis removes expired keys lazily when they are accessed, plus a background process periodically cleans them up. This means expired keys may still consume memory briefly after their TTL expires.
We can indicate that the result of a method should be cached by using Spring's caching abstraction:
@Service
public class ProductService {
@Cacheable("products")
public Product getProduct(String id) {
return productRepository.findById(id).orElseThrow();
}
}
The main advantage of TTL-based caching is definitely its simplicity: it works well when the application can tolerate short periods of outdated data.
However, TTL alone rarely solves the entire problem: if a record changes immediately after being cached, the system may serve outdated information for the entire TTL.
More proactive and effective invalidation strategies are necessary when dealing with highly dynamic data.
The Cache-Aside Pattern
A widely used approach to application-level caching is the “cache-aside” model, also known as the “lazy loading” mechanism. In this model, the application itself handles interactions with both the cache and the database (or any other system to be cached).
When reading data, the service first checks the cache. If the value is not there, the application fetches it from the database and stores it in the cache for future requests.
This model is exactly what Spring’s @Cacheable annotation implements:
@Cacheable(value = "products", key = "#id")
public Product getProduct(String id) {
return productRepository.findById(id).orElseThrow();
}
When data changes, the application explicitly removes the corresponding cache entry.
@CacheEvict(value = "products", key = "#id")
public void updateProduct(Product product) {
productRepository.save(product);
}
The next request will trigger the process again: reading from the database and repopulating the cache.
Cache-aside works very well in single-instance applications. In distributed systems, however, it invalidates the cache only on the node that performs the update. The other nodes may continue to serve outdated values unless additional coordination mechanisms are implemented.
Event-Based Cache Invalidation
A common approach to invalidating a distributed cache is to use event-driven communication.
Instead of relying on individual nodes to invalidate their own caches, services publish events whenever data changes. The other nodes listen for these events and invalidate their cache entries accordingly.
The typical workflow is as follows:
- A record is updated
- The service publishes an invalidation event
- All application instances receive the event
- Each instance deletes the corresponding cache entry.
For this purpose, messaging platforms such as Apache Kafka or RabbitMQ are typically used. For simpler systems, Redis Pub/Sub may be sufficient.
Let’s look at a small example that uses Redis to publish an invalidation message every time a product is updated.
@Service
public class ProductService {
private final RedisTemplate<String, String> redisTemplate;
public void updateProduct(Product product) {
productRepository.save(product);
redisTemplate.convertAndSend(
"cache-invalidation",
product.getId()
);
}
}
Each service instance subscribes to the invalidation channel and clears the cache entry locally.
@Component
public class CacheInvalidationListener implements MessageListener {
private final CacheManager cacheManager;
@Override
public void onMessage(Message message, byte[] pattern) {
String productId = new String(message.getBody());
cacheManager.getCache("products")
.evict(productId);
}
}
This approach ensures that all nodes have the opportunity to respond to the same stream of events, keeping caches synchronized across the entire system.
The main challenge lies in managing reliability issues, such as message delivery guarantees and duplicate events. For this reason, enterprise systems with strict requirements often rely on durable messaging platforms rather than the simple Pub/Sub model.
Versioned Cache Keys
Another effective strategy is using versioned cache keys. Instead of deleting cache entries when data changes, the system creates a new cache key with an incremented version.
For example:
product:123:v1 product:123:v2
When the product changes, the application increments the version number and writes the updated value under the new key; at this point, users automatically retrieve the latest version.
We can create a helper method to manage versioned keys:
public String buildCacheKey(String productId, int version) {
return "product:" + productId + ":v" + version;
}
This technique eliminates race conditions in which one node invalidates a cache entry while another node is writing a new value to that entry.
Versioned keys are particularly useful in high-throughput systems, where invalidation events may arrive in random order. What is the drawback? Keys can accumulate over time, leading to cache overload. It is therefore necessary to implement a periodic cleanup process to remove obsolete and no-longer-useful versions.
Multi-Layer Caching
Many modern systems combine local in-memory caches with distributed caches. This multi-tiered approach reduces latency while maintaining the necessary scalability.
Let’s imagine a typical architecture:
- One or more application instances
- Local in-memory caches (e.g., Caffeine)
- Distributed cache (e.g., Redis)
- Database
The local cache ensures extremely fast reads, while the distributed cache ensures that data is shared across nodes. For example, we can configure our application to use Caffeine for local caching and Redis for distributed in-memory storage.
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager caffeineManager = new CaffeineCacheManager("products");
caffeineManager.setCaffeine(
Caffeine.newBuilder()
.expireAfterWrite(5, TimeUnit.MINUTES)
.maximumSize(10_000)
);
return caffeineManager;
}
In a setup like this, invalidation events must clear both cache levels. While this adds complexity, it allows us to significantly reduce the number of remote cache calls and improve response times under heavy load. It’s important to note that local cache size should be tuned relative to the number of instances. With 10 instances each caching 10,000 entries, total memory consumption across the fleet is 100,000 entries. Size it carefully!
Event-Driven Cache Rebuilds
There are some architectural strategies, particularly those inspired by CQRS, where caches are not simply invalidated but are rebuilt from domain events.
In this case, the system maintains read models derived from a stream of events rather than storing arbitrary cache entries.
Every time an entity changes, the system emits an event of the type:
- ProductCreatedEvent
- ProductUpdatedEvent
- InventoryAdjustedEvent
Consumers subscribe to these events and update read-optimized data structures.
A Kafka listener in a Spring Boot application might look like this:
@KafkaListener(topics = "product-events")
public void handleProductUpdate(ProductUpdatedEvent event) {
cacheManager.getCache("products")
.put(event.getProductId(), event.getProduct());
}
Applying this pattern transforms the cache into a projection of the event stream rather than a layer of temporary storage.
It is a powerful pattern, but it requires a mature event infrastructure and careful design focused on ensuring the consistency of the final result.
Choosing the Right Strategy
So what is the best approach? None. There is no single optimal approach to cache invalidation in distributed systems.
Different applications have different levels of tolerance for stale data, operational complexity, and infrastructure resilience. Furthermore, the best strategy depends on the data and the business process at hand. Every case is unique and must be treated as such.
In many real-world systems, a hybrid strategy is certainly the best approach.
A starting combination could be:
- TTL expiration as a safety net
- cache-aside loading for simplicity
- event-driven invalidation for faster consistency
Systems with high-throughput requirements can adopt versioned keys or event-driven read patterns to ensure the overall effectiveness of the invalidation model.
Final Thoughts
Caching remains one of the most effective ways to improve the performance of distributed systems. When implemented effectively and in line with business requirements, it can drastically reduce the load on the database or external services and greatly improve response times and overall system latency.
However, there is a downside. Distributed caches introduce new challenges in terms of consistency and coordination. Without proper invalidation strategies, caches can serve stale data and compromise system correctness without anyone noticing.
The modern Java ecosystem offers excellent tools for implementing solid and robust caching solutions. Spring Boot simplifies cache integration within an application, whether local or distributed. Technologies like Redis and Apache Kafka enable scalable and resilient distributed coordination.
By combining models such as TTL expiration, cache-aside loading, event-driven invalidation, and multi-tier caching, you can build systems that remain fast and consistent even as they scale.
In conclusion, caching is not a feature to simply enable or disable. It is an architectural component to be integrated and managed within the ecosystem, designed alongside the application to ensure consistency and reliability.
If you’d like to take a look at the examples in the article, feel free to visit the repository.
- April 21, 2026
- 7 min read
Senior Solution Architect presso GOSP - Generali Operations Service Platform







Comments (0)
No comments yet. Be the first.