

Hardware Acceleration For Java? TornadoVM Can Do It!
- April 01, 2022
- 5 min read
Java programs can primarily run on x86 and Arm platforms and recent efforts focus on ports to PowerPC and RISC-V.
Despite the diverse range of ISAs, contemporary computers are equipped with heterogeneous devices, such as Graphics Processing Units (GPUs), Field Programmable Gate Arrays (FPGAs), and Tensor Processing Units (TPUs), which operate as co-processors that offload data processing from the main processor.
A question that rises is whether such compute power can be utilized by Java programs. The answer is that several frameworks have been created to address this challenge. For instance, IBM J9, Aparapi, and TornadoVM, are frameworks that aid Java programmers to accelerate their programs on heterogeneous hardware devices.
This article focuses on TornadoVM and aims to introduce the TornadoVM software architecture.
Figure 1 shows the conventional execution of Java applications on CPUs via the JVM (top), as well as the execution of Java applications through TornadoVM on heterogeneous accelerators.
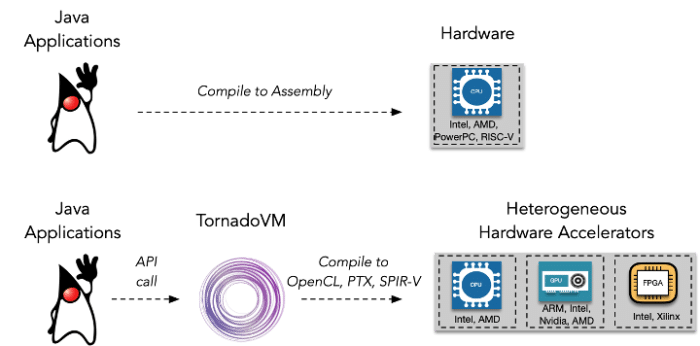
Figure 1: Execution of Java applications through JVM (top) and TornadoVM (bottom).
What is TornadoVM?
TornadoVM is an open-source software technology originated from the Beehive Lab at the University of Manchester. In a nutshell, TornadoVM can be used as a plug-in software for various JDK distributions (e.g., OpenJDK, Red Hat Mandrel, Amazon Corretto, etc.) to enable hardware acceleration.
Besides acceleration, TornadoVM offers several innovative runtime features, such as the live migration from one device to another and the composition of pipelines in Java.
The Interaction Points of TornadoVM with the JVM
The Java Virtual Machine (JVM) is a system that - among others - performs two prime functionalities: a) the translation of Java bytecodes to assembly code, and b) handles memory operations (e.g., allocation of memory, memory mapping, etc.).
This article will not dive into these functionalities, it rather aims to highlight how TornadoVM interacts with the JVM and said functionalities.
a) Bytecode Translation
Regarding bytecode translation, the JVM can operate either in an interpreted mode or in the JIT compilation mode. It starts execution on interpreted mode and switches to the latter mode once a code segment has reached a “hot” state. In practice, this means that a code segment has been executed multiple times, hence the optimized compiled code can be stored and re-used.
Currently, the JVM runs with various JIT compilers (e.g., C1, C2, Graal). The TornadoVM JIT compiler is an extension of Graal that translates Java methods to heterogeneous programming code (OpenCL) or binary (SPIR-V, PTX). The TornadoVM JIT compiler is invoked via the JVM compiler interface (JVMCI). Thus, it is a complementary JIT compiler that can generate code for heterogeneous hardware accelerators.
b) Managed Runtime Environment
The software architecture of TornadoVM is designed to be oblivious of the specific JDK version that it co-operates with, and it includes three layers (API, Runtime, Execution Engine), as shown in Figure 2.
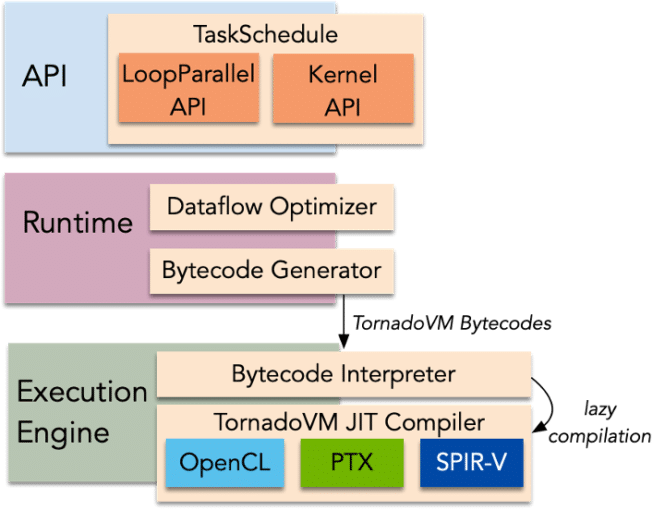
Figure 2: TornadoVM Software Stack.
API
TornadoVM exposes a task-based API (named TaskSchedule) that marks the methods (i.e., TornadoVM tasks) for acceleration and indicates the level of parallelism, as well as the corresponding input and output data. A TaskSchedule exposes the following methods:
streamIn(): to pass the input data;streamOut(): to pass the output data;task(): to pass the signature of a method that will be accelerated;execute(): to perform the compilation and execution.
The TaskSchedule API is supported by various Java versions (JDK 8 - JDK 17). In addition, the TornadoVM API provides two separate ways for expressing parallelism in Java, the LoopParallel API and the Kernel API. The former API enables Java programmers to annotate for-loops as capable of being executed in parallel (via @Parallel annotation).
The latter API exposes - via the KernelContext object - some features that are available at the kernel level. These features regard functionalities (e.g., local memory utilization, memory barriers, etc.) used in OpenCL and CUDA for enhancing the execution of heterogeneous kernels.
Runtime
The meta-data stored in a TaskSchedule is utilized by the TornadoVM runtime to optimize the dataflow and compose custom bytecodes (the TornadoVM Bytecodes).
The dataflow optimization ensures that data produced by one task remain on the accelerator memory for the execution of a second task; with no need to send it back to the host CPU and reload it. This optimization is transparently applied at runtime for tasks which are combined within the same TaskSchedule.
The TornadoVM Bytecodes are responsible for orchestrating the compilation and execution of tasks on hardware accelerators. That functionality empowers features, such as parallel batch processing, live task migration, and execution of Multiple Tasks on Multiple Devices (MTMD)*.
*This functionality is not currently upstream.
JIT Compiler
By extending the Graal compiler, the TornadoVM JIT compiler capitalizes on a rich set of compiler optimizations, such as inlining methods, replacement of Lambda functions by ordinary function calls, scalar replacement of allocated objects via partial escape analysis, etc.
Additionally, it allows fast development of new compiler phases, since Graal is highly modular and written in Java. The compilation is performed gradually. It crosses from the high-tier (architecture agnostic) to the low-tier where the code generation is performed. The TornadoVM JIT Compiler encompasses three code generation backends:
- The OpenCL backend emits parallel code in OpenCL C source code that can be executed on multi-core CPUs (x86, Arm), GPUs (Nvidia, AMD, Intel, Arm), and FPGAs (Intel, Xilinx).
- The PTX backend emits parallel implementations in assembly code that can be executed on Nvidia GPUs.
- The SPIR-V backend emits binary SPIR-V code that can be executed currently on Intel Integrated GPUs and any SPIR-V compatible devices.
Applications of Interest
Applications that can merit from hardware acceleration must exhibit a high degree of parallelism. The kind of parallelism can indicate which hardware type is more suitable for execution. For example, applications aiming at high-throughput processing can target GPU hardware. On the other hand, applications that focus on low latency calculations can harness FPGAs.
Regardless of the hardware type, there is a common denominator that can impact performance. This is the size of data that is processed by applications. The reason is that heterogeneous programming models (e.g., CUDA, OpenCL) require data to be transferred between the host CPU and the accelerators (e.g., GPUs, FPGAs). This case is noted for accelerators that are connected to the CPU via PCIe, and therefore, the speedup you can get from acceleration is offset by the time spent in data transfers.
Accelerators can be also integrated on the same silicon and share memory with the CPU. Figure 3 presents some application domains that have been accelerated with TornadoVM, including Kinect Fusion, Viola Jones Face Detection, Ray Tracing, Natural Language Processing, Machine Learning, and Analytics of data from IoT sensors.
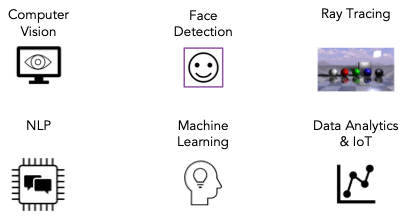
Figure 3: TornadoVM Use Cases.
Summary
To summarize, TornadoVM is a software technology that enables hardware acceleration for Java and potentially other JVM programming languages.
It is designed to offer a hardware agnostic API, while also transparently applying hardware-related code specializations at runtime.
TornadoVM is currently supported by various Java versions (JDK 8 - JDK 17) and can execute on the vast majority of hardware vendors.
If your application can benefit from hardware acceleration you can try TornadoVM today, it is open source on GitHub. If you are not sure, talk to us!
- April 01, 2022
- 5 min read
Research Fellow at The University of Manchester, TornadoVM Technology and Commercialisation








Comments (0)
No comments yet. Be the first.