

How Java Litters Beyond the Heap: Part 2, Distributed Databases
- December 20, 2022
- 7 min read
Let’s create a simple Java application using a distributed database for the user data and see how the database generates litter in response to application requests.
While the Java Virtual Machine executes our code at runtime, it generates garbage in the heap, which is dutifully collected by the garbage collector. This is a known fact.
However, at the same time, Java apps don’t live in isolation and frequently communicate with services, databases, and other components. Some of those components also generate and collect garbage, while fulfilling the Java app’s requests. This is less known.
The first article in this series, How Java Litters Beyond the Heap: Part 1, Relational Databases, shows what happens if a Java application uses PostgreSQL as a persistence layer.
The database generates new versions of a record for every update, and the dead versions get garbage collected later. PostgreSQL is one of many relational databases that does this.
It’s a common behavior among all databases implementing MVCC (Multiversion concurrency control).
But, suppose our Java app uses a distributed database for the user data. Will that database also generate litter in response to application requests? Let’s find out….
LSM Tree-Based Databases
There is a class of distributed databases that stores and arranges application data in a log-structured merge (LSM) tree for its performance and scalability characteristics. Apache Cassandra, Apache HBase, ScyllaDB, and YugabyteDB all belong to this class.
The LSM-tree is a data structure that is optimized for the sequential disk write I/O, the most performant way to work with disk. The implementation of the tree usually varies from database to database, but the primary components remain the same:
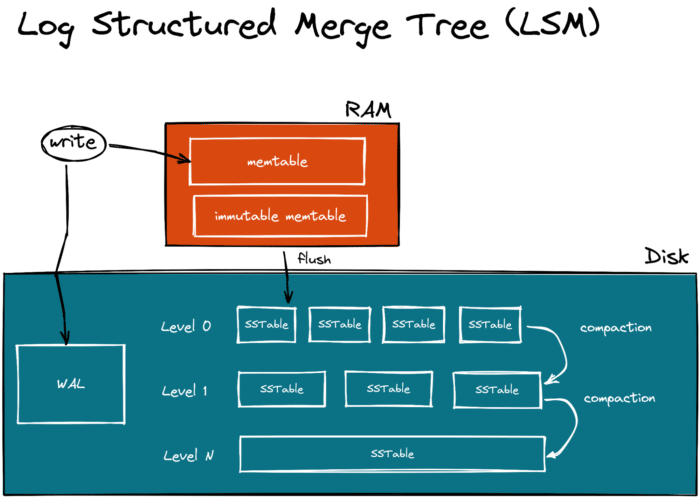
- Memtable and WAL (write-ahead-log) - this is where the data first ends up. When the app writes an update, the update is sequentially written to the WAL on disk and added to the memtable in DRAM. The memtable is a sorted tree that keeps the records in order. If the app updates an existing key in the memtable, then some databases will overwrite the existing value (Cassandra) while others (YugabyteDB) will keep the old value untouched and store the new value separately (for MVCC).
- Immutable memtable - over time, the memtable size reaches a predefined threshold. Once this happens, the current memtable is marked as immutable, and a new one is created. The new memtable starts handling writes from the application.
- SSTable (Sorted String Table) - then at some point, the immutable memtable gets flushed to disk as an SSTable. The SSTable is immutable as well. All the data stays sorted within the file—making index search and range queries fast.
When the database repeats the memtable->immutable memtable->SSTable cycle several times, it will end up having multiple SSTable files on disk. Some of those files can store duplicate keys holding the actual as well as old values.
Some can have data that is already deleted by the app but yet remains in the SSTable files for MVCC and crash recovery needs. All this stale and deleted data is eventually garbage collected during the regular compaction cycles.
There are several widespread compaction techniques. One database can take several SSTables from Level N, merge those files (removing stale and deleted data), and produce a new SSTable on Level N+1.
Another database can have just Level 0 and merge multiple SSTable into a new file once the initial files reach a certain size threshold. The next database might use a completely different approach.
Alright, enough of the theory. Let’s see how things work in practice.
Starting YugabyteDB and the App
Our sample app is a Spring Boot RESTful service for a pizzeria. The app tracks pizza orders.
As for an LSM tree-based database, we’ll look at YugabyteDB, a distributed SQL database built on PostgreSQL. Think of it as a distributed PostgreSQL that scales both reads and writes.
Let’s deploy a single-node YugabyteDB instance in Docker:
- Start the database in a container:
rm -r ~/yb_docker_data mkdir ~/yb_docker_data docker network create yugabytedb_network docker run -d --name yugabytedb_node1 --net yugabytedb_network \ -p 7001:7000 -p 9000:9000 -p 5433:5433 \ -v ~/yb_docker_data/node1:/home/yugabyte/yb_data --restart unless-stopped \ yugabytedb/yugabyte:2.14.4.0-b26 \ bin/yugabyted start --listen=yugabytedb_node1 \ --base_dir=/home/yugabyte/yb_data --daemon=false
- Connect to the container:
docker exec -it yugabytedb_node1 /bin/bash
- Connect to the database using the
ysqlshtool:bin/ysqlsh -h yugabytedb_node1
- Make sure the database is empty (no tables yet):
yugabyte=# \d Did not find any relations.
Next, start the application:
- Clone the app:
git clone https://github.com/dmagda/java-litters-everywhere.git && cd java-litters-everywher
- Open the
src\main\resources\application.propertiesfile and enable YugabyteDB connection properties:
#Uncomment the YugabyteDB-specific connectivity settings: spring.datasource.url = jdbc:postgresql://127.0.0.1:5433/yugabyte spring.datasource.username = yugabyte spring.datasource.password = yugabyte #And disable to Postgres-specific settings # spring.datasource.url = jdbc:postgresql://localhost:5432/postgres # spring.datasource.username = postgres # spring.datasource.password = password
- Launch the app:
mvn spring-boot:run
Once the application starts, it will be listening on port 8080 for user requests:
INFO 58081 --- [main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... INFO 58081 --- [main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed. INFO 58081 --- [main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path
Finally, go back to your ysqlsh session within the Docker container to make sure the application created the pizza_order table:
yugabyte=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------+-------+----------
public | pizza_order | table | yugabyte
(1 row)
yugabyte=# select * from pizza_order;
id | status | order_time
----+--------+------------
(0 rows)
Generating Garbage in the Database
Now, go ahead and put the first pizza order in the queue.
- Call the API endpoint below with curl or in the browser:
curl -i -X POST \ http://localhost:8080/putNewOrder \ --data 'id=1' - The application persists the order to the database (check the application logs):
Hibernate: insert into pizza_order (order_time, status, id) values (?, ?, ?) - Use the
ysqlshsession to ensure the order made it to the database:
yugabyte=# select * from pizza_order; id | status | order_time ----+---------+------------------------ 1 | Ordered | 2022-12-13 14:56:32.13 (1 row)
As the next step, update the order status two times:
- Change the status to
Bakingusing the following API call:
curl -i -X PUT \ http://localhost:8080/changeStatus \ --data 'id=1' \ --data 'status=Baking' - And then to
Delivering:
curl -i -X PUT \ http://localhost:8080/changeStatus \ --data 'id=1' \ --data 'status=Delivering'
If you select the data from the pizza_order table, it’s not surprising that you’ll see the status column is set to Delivering:
yugabyte=# select * from pizza_order; id | status | order_time ----+------------+------------------------ 1 | Delivering | 2022-12-13 14:56:32.13 (1 row)
Does that mean that the previous status values (Ordered and Baking) are gone from the database? Nope! They are still there, sitting in the memtable.
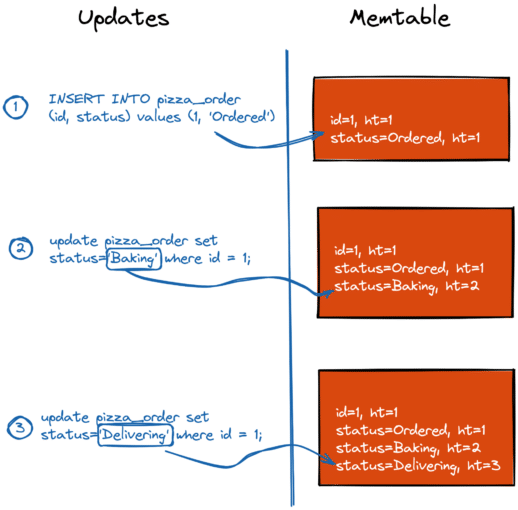
- If the app updates a column of an existing record, the new column value is stored alongside the old ones. YugabyteDB keeps both the actual and old column values (even in the memtable) to ensure concurrent and consistent data access with its multi-version concurrency control (MVCC) implementation.
- Each column value is assigned a unique version. YugabyteDB uses the hybrid time (ht) for that. The higher the hybrid time, the newer the column’s version. The status column with
Deliveringhasht=3, so, this value is visible to all future application requests such asselect * from pizza_order.
YugabyteDB doesn’t currently provide a way to look into the state of the memtable.
But, we can see the multiple versions of the status column by forcefully flushing the memtable to disk and by looking at a respective SSTable file:
- Exit the
ysqlshsession with the YugabyteDB node container:
\q
- Use
yb_admincommand to find thepizza_ordertable ID:
yb-admin -master_addresses yugabytedb_node1:7100 list_tables include_table_id | grep pizza_order
- Flush the memtable to disk:
yb-admin -master_addresses yugabytedb_node1:7100 flush_table ysql.yugabyte pizza_order
- Open the SSTable file with multiple versions of the
statuscolumn:
./bin/sst_dump --command=scan --file=/home/yugabyte/yb_data/data/yb-data/tserver/data/rocksdb/table-{PIZZA_ORDER_TABLE_ID}/tablet-{TABLET_ID}/000010.sst --output_format=decoded_regulardb #The output might be as follows Sst file format: block-based SubDocKey(DocKey(0x1210, [1], []), [SystemColumnId(0); HT{ physical: 1670964617951372 }]) -> null; intent doc ht: HT{ physical: 1670964617927460 } SubDocKey(DocKey(0x1210, [1], []), [ColumnId(1); HT{ physical: 1670964638701253 }]) -> 4629700416936886278; intent doc ht: HT{ physical: 1670964638692844 } SubDocKey(DocKey(0x1210, [1], []), [ColumnId(1); HT{ physical: 1670964624310711 }]) -> 4611686018427404292; intent doc ht: HT{ physical: 1670964624295329 } SubDocKey(DocKey(0x1210, [1], []), [ColumnId(1); HT{ physical: 1670964617951372 w: 1 }]) -> 4575657221408440322; intent doc ht: HT{ physical: 1670964617927460 w: 1 } SubDocKey(DocKey(0x1210, [1], []), [ColumnId(2); HT{ physical: 1670964638701253 w: 1 }]) -> 724261817884000; intent doc ht: HT{ physical: 1670964638692844 w: 1 }
There are three versions of ColumnId(1), which is the status column.
- Line #6 - this is the latest column value that is visible to all future requests (
status=’Delivering’). It has the highest hybrid time (HT) which isHT{ physical: 1670964638701253 }. - Line #7 - this is the version of the column when the
statuswasBaking - Line #8 - and this is the very first version of
status=Ordered
For curious minds, ColumnId(2) on line #9 is the order_time column. As long as it has not been updated after the order was placed in the database, there is only one version of the column.
Garbage Collection in the Database
It’s clear that YugabyteDB can’t and doesn’t want to keep stale and deleted data forever. This is why the database has its own garbage collection process called compaction.
YugabyteDB uses size-tiered compaction and comes with a single level of SSTable files - Level 0.
Once the cumulative size of several SSTables reaches a certain threshold, the files get merged into a new larger SSTable that no longer has keys with stale and deleted data.
After that, the initial SSTable files get deleted from the file system.
Let’s use the picture below to break things down:
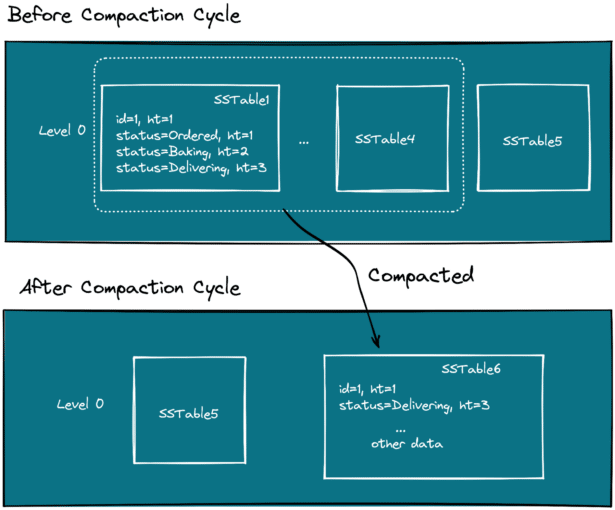
- SSTable1 through SSTable4 files meet the compaction criteria and YugabyteDB starts compacting them. SSTable1 file includes two versions of the
statuscolumn that are no longer needed -OrderedandBaking - The files got merged, with stale and deleted data removed. The new SSTable6 file is created to hold the compacted data. The resulting file has only the latest version of the
statuscolumn which isDelivering. - The SSTable1 through SSTable4 files get deleted.
- The SSTable5 is left untouched. It was not included in the compaction cycle.
Wrapping Up
As you can see, garbage collection is a widespread technique used far beyond the Java ecosystem.
Not only classic relational databases like PostgreSQL use garbage collection to their advantage.
The new class of distributed databases backed by the LSM tree also store multiple versions of the data, which is garbage collected later by the compaction process.
This allows distributed databases to execute transactions across multiple nodes concurrently and consistently.
But the story isn’t over yet! In my next article, I’ll show what happens if a Java application uses solid-state drives (SSDs).
I also invite you to read the first article in this series How Java Litters Beyond the Heap: Part 1, Relational Databases.
- December 20, 2022
- 7 min read
Denis started his professional career at Sun Microsystems and Oracle, where he built JVM/JDK and led one of the Java development groups. After learning Java from the inside, he joined the world of distributed systems and databases, where he has remained ever since.







Comments (0)
No comments yet. Be the first.