


Semantic Caching with SpringBoot & Redis
- August 07, 2025
- 7 min read
TL;DR: You’re building a semantic caching system using Spring AI and Redis to improve LLM application performance.
Unlike traditional caching that requires exact query matches, semantic caching understands the meaning behind queries and can return cached responses for semantically similar questions.
It works by storing query-response pairs as vector embeddings in Redis, allowing your application to retrieve cached answers for similar questions without calling the expensive LLM, reducing both latency and costs.

The Problem with Traditional LLM Applications
LLMs are powerful but expensive. Every API call costs money and takes time. When users ask similar questions like “What beer goes with grilled meat?” and “Which beer pairs well with barbecue?”, traditional systems would make separate LLM calls even though these queries are essentially asking the same thing.
Traditional exact-match caching only works if users ask the identical question word-for-word. But in real applications, users phrase questions differently while seeking the same information.
How Semantic Caching Works
Video: What is a semantic cache?
Semantic caching solves this by understanding the meaning behind queries rather than matching exact text. When a user asks a question:
- The system converts the query into a vector embedding
- It searches for semantically similar cached queries using vector similarity
- If a similar query exists above a certain threshold, it returns the cached response
- If not, it calls the LLM, gets a response, and caches both the query and response for future use
Behind the scenes, this works thanks to vector similarity search. It turns text into vectors (embeddings) — lists of numbers — stores them in a vector database, and then finds the ones closest to your query when checking for cached responses.
Today, we’re gonna build a semantic caching system for a beer recommendation assistant. It will remember previous responses to similar questions, dramatically improving response times and reducing API costs.
To do that, we’ll build a Spring Boot app from scratch and use Redis as our semantic cache store. It’ll handle vector embeddings for similarity matching, enabling our application to provide lightning-fast responses for semantically similar queries.
Redis as a Semantic Cache for AI Applications
Video: What's a vector database
Redis Open Source 8 not only turns the community version of Redis into a Vector Database, but also makes it the fastest and most scalable database in the market today. Redis 8 allows you to scale to one billion vectors without penalizing latency.
For semantic caching, Redis serves as:
- A vector store using Redis JSON and the Redis Query Engine for storing query embeddings
- A metadata store for cached responses and additional context
- A high-performance search engine for finding semantically similar queries
Spring AI and Redis
Video: What’s an embedding model?
Spring AI provides a unified API for working with various AI models and vector stores. Combined with Redis, it allows developers to easily build semantic caching systems that can:
- Store and retrieve vector embeddings for semantic search
- Cache LLM responses with semantic similarity matching
- Reduce API costs by avoiding redundant LLM calls
- Improve response times for similar queries
Building the Application
Our application will be built using Spring Boot with Spring AI and Redis. It will implement a beer recommendation assistant that caches responses semantically, providing fast answers to similar questions about beer pairings.
0. GitHub Repository
The full application can be found on GitHub
1. Add the required dependencies
From a Spring Boot application, add the following dependencies to your Maven or Gradle file:
implementation("org.springframework.ai:spring-ai-transformers:1.0.0")
implementation("org.springframework.ai:spring-ai-starter-vector-store-redis")
implementation("org.springframework.ai:spring-ai-starter-model-openai")
2. Configure the Semantic Cache Vector Store
We’ll use Spring AI’s RedisVectorStore to store and search vector embeddings of cached queries and responses:
@Configuration
class SemanticCacheConfig {
@Bean
fun semanticCachingVectorStore(
embeddingModel: TransformersEmbeddingModel,
jedisPooled: JedisPooled
): RedisVectorStore {
return RedisVectorStore.builder(jedisPooled, embeddingModel)
.indexName("semanticCachingIdx")
.contentFieldName("content")
.embeddingFieldName("embedding")
.metadataFields(
RedisVectorStore.MetadataField("answer", Schema.FieldType.TEXT)
)
.prefix("semantic-caching:")
.initializeSchema(true)
.vectorAlgorithm(RedisVectorStore.Algorithm.HSNW)
.build()
}
}
Let’s break this down:
- Index Name:
semanticCachingIdx— Redis will create an index with this name for searching cached responses - Content Field:
content— The raw prompt that will be embedded - Embedding Field:
embedding— The field that will store the resulting vector embedding - Metadata Fields:
answer: TEXT field for storing the LLM's response- Prefix:
semantic-caching:— All keys in Redis will be prefixed with this to organize the data - Vector Algorithm: HSNW — Hierarchical Navigable Small World algorithm for efficient approximate nearest neighbor search
3. Implement the Semantic Caching Service
The SemanticCachingService handles storing and retrieving cached responses from Redis:
@Service
class SemanticCachingService(
private val semanticCachingVectorStore: RedisVectorStore
) {
private val logger = LoggerFactory.getLogger(SemanticCachingService::class.java)
fun storeInCache(prompt: String, answer: String) {
// Create a document for the vector store
val document = Document(
prompt,
mapOf("answer" to answer)
)
// Store the document in the vector store
semanticCachingVectorStore.add(listOf(document))
logger.info("Stored response in semantic cache for prompt: ${prompt.take(50)}...")
}
fun getFromCache(prompt: String, similarityThreshold: Double = 0.8): String? {
// Execute similarity search
val results = semanticCachingVectorStore.similaritySearch(
SearchRequest.builder()
.query(prompt)
.topK(1)
.build()
)
// Check if we found a semantically similar query above threshold
if (results?.isNotEmpty() == true) {
val score = results[0].score ?: 0.0
if (similarityThreshold < score) {
logger.info("Cache hit! Similarity score: $score")
return results[0].metadata["answer"] as String
} else {
logger.info("Similar query found but below threshold. Score: $score")
}
}
logger.info("No cached response found for prompt")
return null
}
}
Key features of the semantic caching service:
- Stores query-response pairs as vector embeddings in Redis
- Retrieves cached responses using vector similarity search
- Configurable similarity threshold for cache hits
- Comprehensive logging for debugging and monitoring
4. Integrate with the RAG Service
The RagService orchestrates the semantic caching with the standard RAG pipeline:
@Service
class RagService(
private val chatModel: ChatModel,
private val vectorStore: RedisVectorStore,
private val semanticCachingService: SemanticCachingService
) {
private val logger = LoggerFactory.getLogger(RagService::class.java)
fun retrieve(message: String): RagResult {
// Check semantic cache first
val startCachingTime = System.currentTimeMillis()
val cachedAnswer = semanticCachingService.getFromCache(message, 0.8)
val cachingTimeMs = System.currentTimeMillis() - startCachingTime
if (cachedAnswer != null) {
logger.info("Returning cached response")
return RagResult(
generation = Generation(AssistantMessage(cachedAnswer)),
metrics = RagMetrics(
embeddingTimeMs = 0,
searchTimeMs = 0,
llmTimeMs = 0,
cachingTimeMs = cachingTimeMs,
fromCache = true
)
)
}
// Standard RAG process if no cache hit
logger.info("No cache hit, proceeding with RAG pipeline")
// Retrieve relevant documents
val startEmbeddingTime = System.currentTimeMillis()
val searchResults = vectorStore.similaritySearch(
SearchRequest.builder()
.query(message)
.topK(5)
.build()
)
val embeddingTimeMs = System.currentTimeMillis() - startEmbeddingTime
// Create context from retrieved documents
val context = searchResults.joinToString("\n") { it.text }
// Generate response using LLM
val startLlmTime = System.currentTimeMillis()
val prompt = createPromptWithContext(message, context)
val response = chatModel.call(prompt)
val llmTimeMs = System.currentTimeMillis() - startLlmTime
// Store the response in semantic cache for future use
val responseText = response.result.output.text ?: ""
semanticCachingService.storeInCache(message, responseText)
return RagResult(
generation = response.result,
metrics = RagMetrics(
embeddingTimeMs = embeddingTimeMs,
searchTimeMs = 0, // Combined with embedding time
llmTimeMs = llmTimeMs,
cachingTimeMs = 0,
fromCache = false
)
)
}
private fun createPromptWithContext(query: String, context: String): Prompt {
val systemMessage = SystemMessage("""
You are a beer recommendation assistant. Use the provided context to answer
questions about beer pairings, styles, and recommendations.
Context: $context
""".trimIndent())
val userMessage = UserMessage(query)
return Prompt(listOf(systemMessage, userMessage))
}
}
Key features of the integrated RAG service:
- Checks semantic cache before expensive LLM calls
- Falls back to standard RAG pipeline for cache misses
- Automatically caches new responses for future use
- Provides detailed performance metrics including cache hit indicators
Running the Demo
The easiest way to run the demo is with Docker Compose, which sets up all required services in one command.
Step 1: Clone the repository
git clone https://github.com/redis-developer/redis-springboot-resources.git cd redis-springboot-resources/artificial-intelligence/semantic-caching-with-spring-ai
Step 2: Configure your environment
Create a .env file with your OpenAI API key:
OPENAI_API_KEY=sk-your-api-key
Step 3: Start the services
docker compose up --build
This will start:
- redis: for storing both vector embeddings and cached responses
- redis-insight: a UI to explore the Redis data
- semantic-caching-app: the Spring Boot app that implements the semantic caching system
Step 4: Use the application
When all services are running, go to localhost:8080 to access the demo. You'll see a beer recommendation interface:
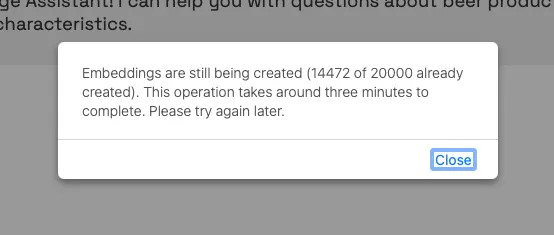
If you click on Start Chat, it may be that the embeddings are still being created, and you get a message asking for this operation to complete. This is the operation where the documents we'll search through will be turned into vectors and then stored in the database. It is done only the first time the app starts up and is required regardless of the vector database you use.
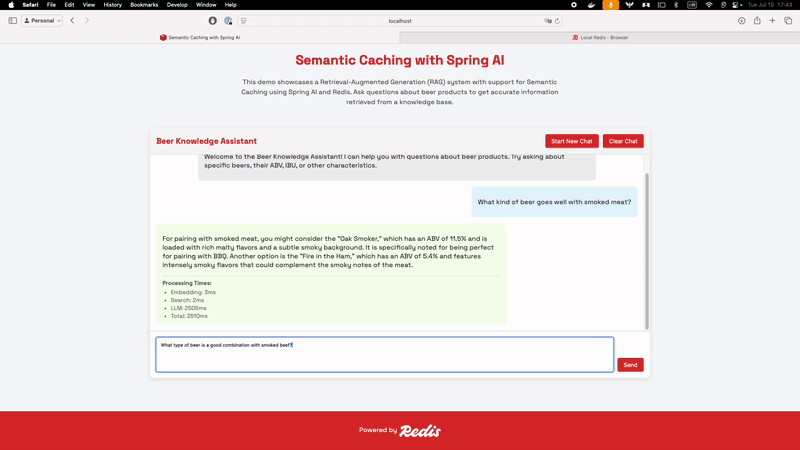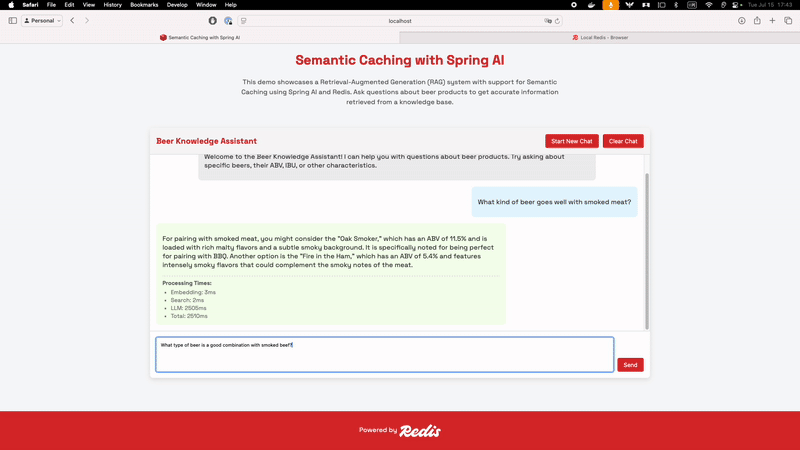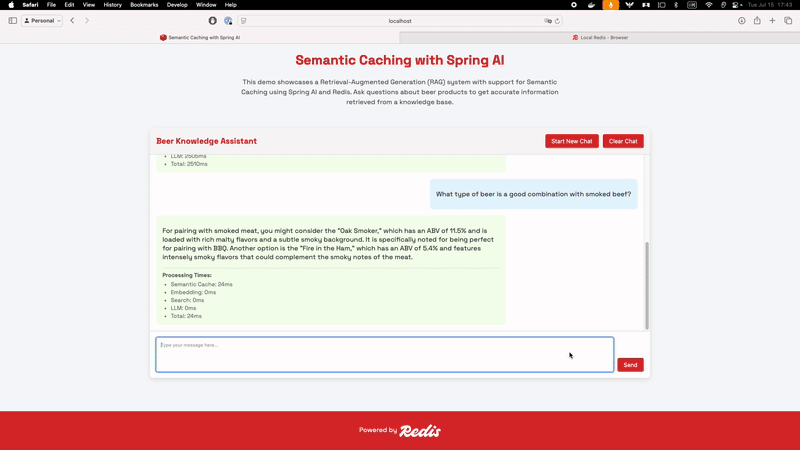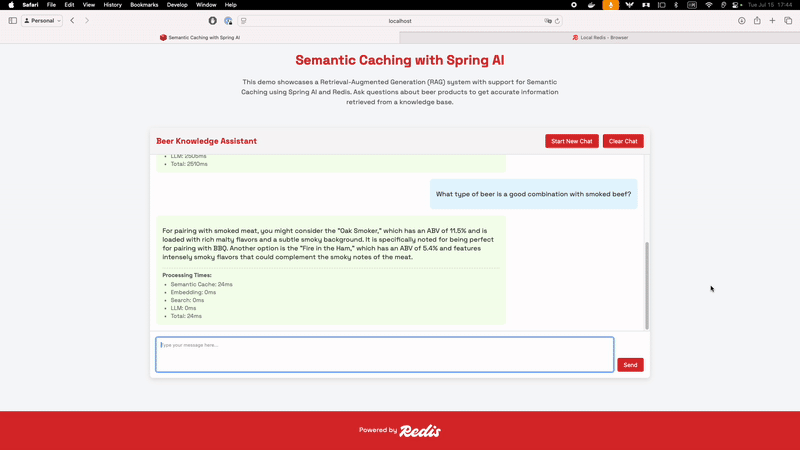
Once all the embeddings have been created, you can start asking your chatbot questions. It will semantically search through the documents we have stored, try to find the best answer for your questions, and cache the responses semantically in Redis:

If you ask something similar to a question had already been asked, your chatbot will retrieve it from the cache instead of sending the query to the LLM. Retrieving an answer much faster now.
Exploring the Data in Redis Insight
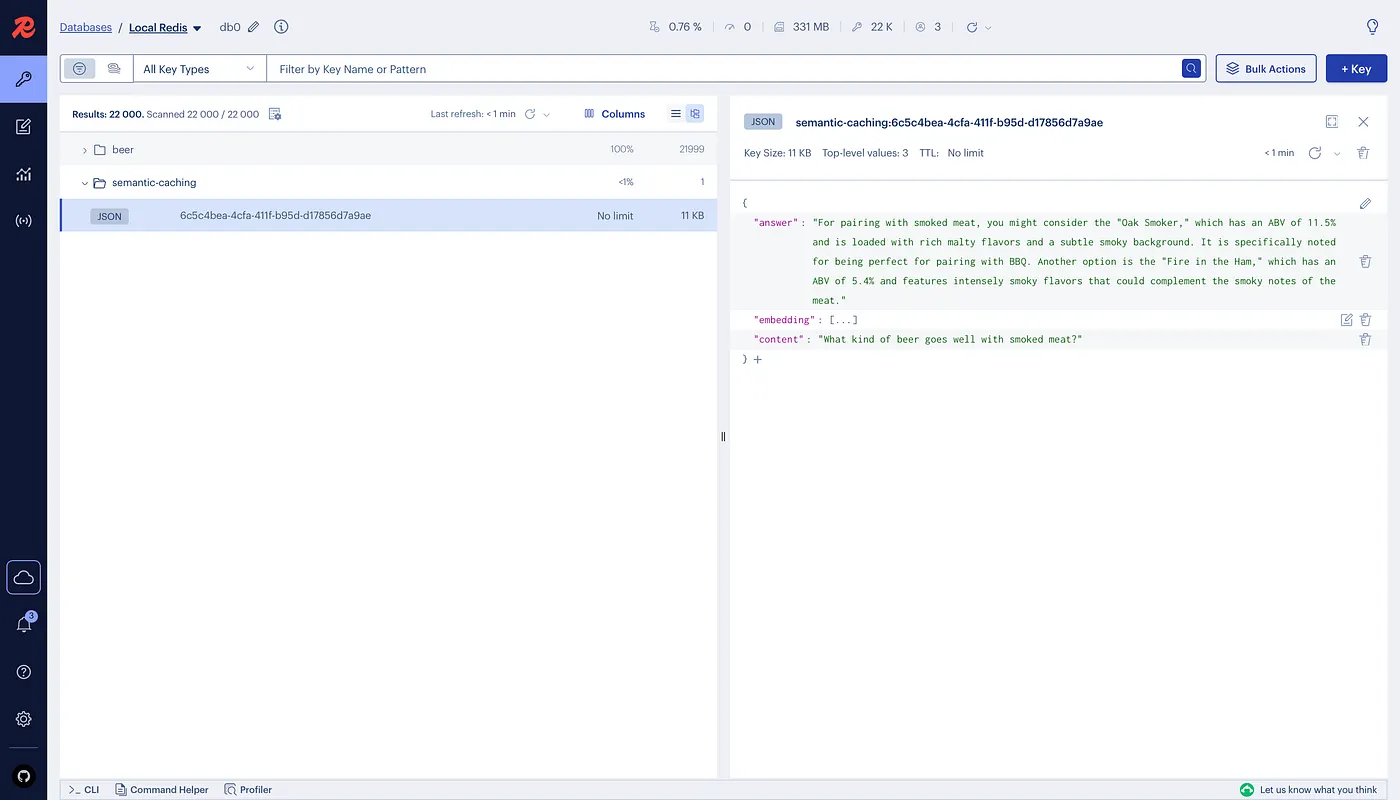
RedisInsight provides a visual interface for exploring the cached data in Redis. Access it at localhost:5540 to see:
- Semantic Cache Entries: Stored as JSON documents with vector embeddings
- Vector Index Schema: The schema used for similarity search
- Performance Metrics: Monitor cache hit rates and response times
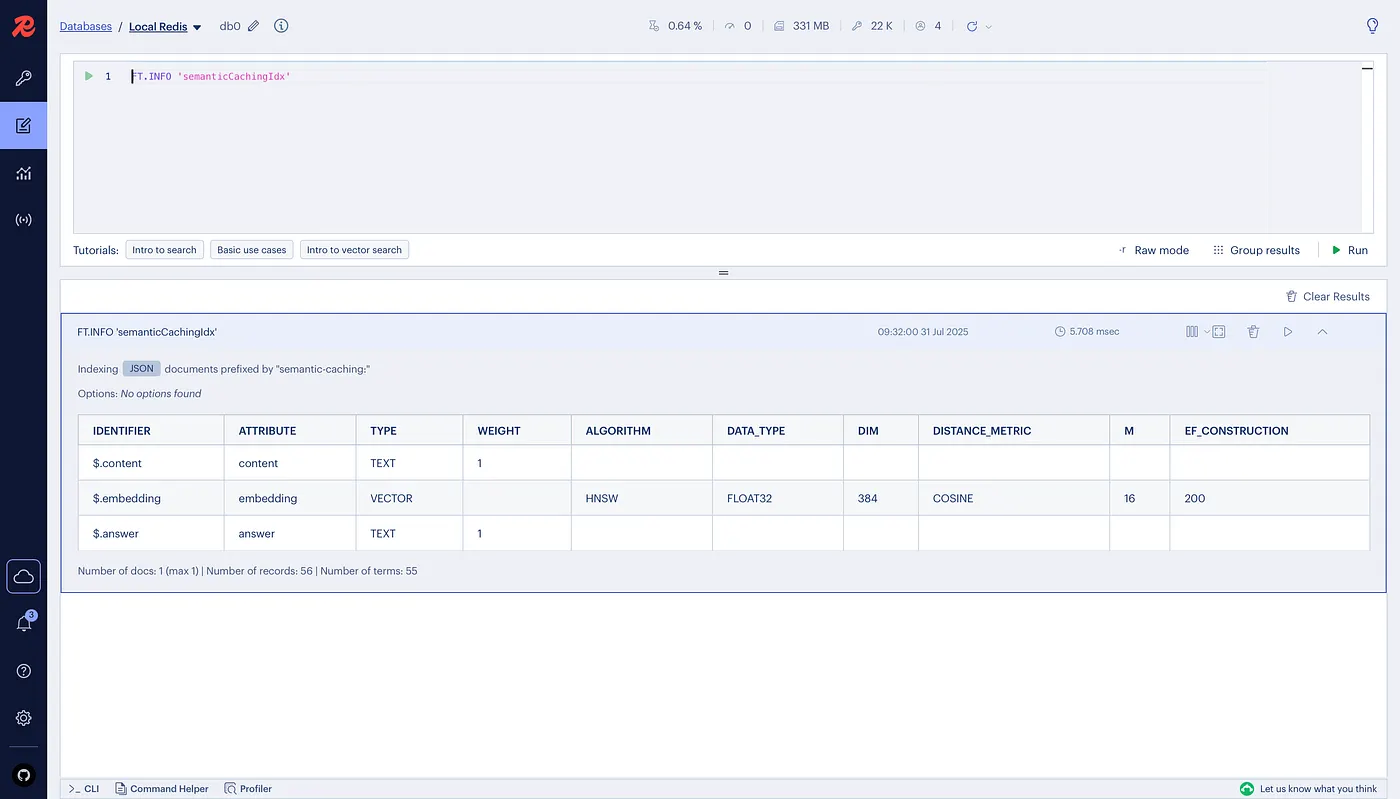
If you run the FT.INFO semanticCachingIdx command in the RedisInsight workbench, you'll see the details of the vector index schema that enables efficient semantic matching.
Wrapping up
And that’s it — you now have a working semantic caching system using Spring Boot and Redis.
Instead of making expensive LLM calls for every similar question, your application can now intelligently cache and retrieve responses based on semantic meaning. Redis handles the vector storage and similarity search with the performance and scalability Redis is known for.
With Spring AI and Redis, you get an easy way to integrate semantic caching into your Java applications. The combination of vector similarity search for semantic matching and efficient caching gives you a powerful foundation for building cost-effective, high-performance AI applications.
Whether you’re building chatbots, recommendation engines, or question-answering systems, this semantic caching architecture gives you the tools to dramatically reduce costs while maintaining response quality and improving user experience.
Try it out, experiment with different similarity thresholds, explore other embedding models, and see how much you can save on LLM costs while delivering faster responses!
Stay Curious!
- August 07, 2025
- 7 min read
Software Engineer | Developer Advocate | International Conference Speaker | Tech Content Creator | Working @ Redis












Comments (0)
No comments yet. Be the first.