


Duplicate Finder for Documentation
- May 08, 2024
- 3 min read
Other languages: Español 한국어 Português 中文
Anyone who worked on technical documentation in a big team is certainly aware of the content duplication issue. Even with the best tools and practices at hand, duplication is fundamentally difficult to overcome.

As the project grows in size, duplicated content will start to occur. This is especially true for big projects including many similar products or features.
Good:
define once:
<p>
If you encounter any issues, refer to the troubleshooting guide
or contact support.
</p>
reuse elsewhere:
<TroubleshootingNote/>
Bad:
<p>
If you encounter any issues, refer to the troubleshooting
guide or contact support.
</p>
<!-- same meaning, slightly different wording-->
<p>
In case of problems, consult the troubleshooting guide
or contact support
</p>
The idea that advocates against duplication is commonly known as DRY Principle. Though it is primarily associated with programming, the same property is highly favoured in documentation.
Project intro
Modern authoring tools typically have features for content reuse, making technical constraints less of a concern. The real problem, on the other hand, lies in spotting duplicates. Before you extract something to a reusable chunk, you need to know what to extract.
If you are a programmer, your IDE might highlight duplicate code for you:

Unfortunately, the same feature is not suitable for documentation, as it relies on comparing abstract syntax trees (AST). This approach doesn't work well with text.
One of my ongoing projects is to implement a duplicate finder for documentation. The tool will be capable of quickly finding non-exact, or fuzzy, matches, such as the bad example above.
Current status
As of this writing, the project is WIP, but there is already a working prototype:
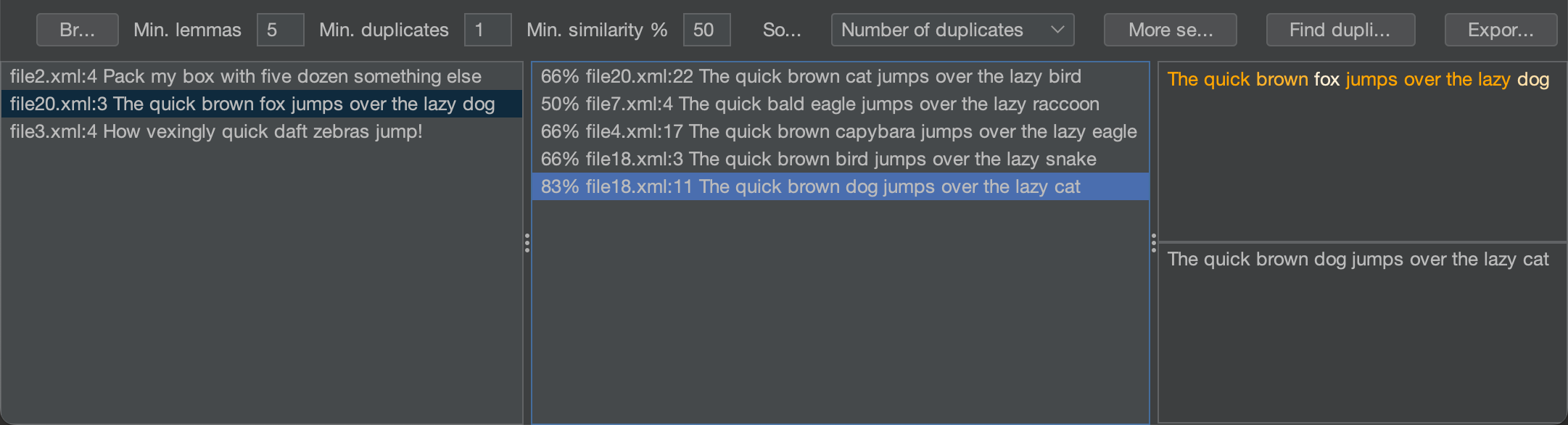
The algorithm takes under 30 seconds to analyze a project with ~6k source files on my MBP M1, and I'm planning on improving it to instantly highlight duplicates right as you type in the editor.
The prototype has already helped me and my colleagues find a lot of duplicates in real projects, so I'm quite enthusiastic about the results and future improvements.
What's next
In the following posts, I will lay out the algorithm step-by-step and perform benchmarks to evaluate its performance. If you are into programming, you are welcome to code along.
Alternatively, you can keep an eye on the progress and use the final deliverable when the project is complete. Once finished, this feature will be available in Writerside, a great authoring tool made by my colleagues.
I hope that the project description resonates with you, and that you'll find the walkthrough useful. You won't miss the future chapters of this series if you regularly check out Foojay, but it's still a good idea to subscribe to my blog and Twitter account.
See you in the next posts!
- May 08, 2024
- 3 min read
Technical writer at JetBrains, hobbyist developer, author at flounder.dev










Comments (0)
No comments yet. Be the first.