


Indexing all of Wikipedia, on a laptop
- May 29, 2024
- 7 min read
Redis just got a whole lot better!
We just announced a bunch of new tools and features that a simpler way to build fast, powerful AI apps.
More Info Here!
In November, Cohere released a dataset containing all of Wikipedia, chunked and embedded to vectors with their multilingual-v3 model.
Computing this many embeddings yourself would cost in the neighborhood of $5000, so the public release of this dataset makes creating a semantic, vector-based index of Wikipedia practical for an individual for the first time.
Here’s what we’re building:

You can try searching the completed index on a public demo instance here.
Why this is hard
Sure, the dataset is big (180GB for the English corpus), but that’s not the obstacle per se. We’ve been able to build full-text indexes on larger datasets for a long time.
The obstacle is that until now, off-the-shelf vector databases could not index a dataset larger than memory, because both the full-resolution vectors and the index (edge list) needed to be kept in memory during index construction. Larger datasets could be split into segments, but this means that at query time they need to search each segment separately, then combine the results, turning an O(log N) search per segment into O(N) overall. (In their latest release, Lucene attempts to mitigate this by processing segments in parallel with multiple threads, but obviously (1) this only gives you a constant factor of improvement before you run out of CPU cores and (2) this does not improve throughput.)
Specifically, if you’re indexing 1536-dimension vectors (the size of ada002 or openai-v3-small), then you can fit about 5M vectors and their associated edge lists in a 32GB index construction RAM budget.
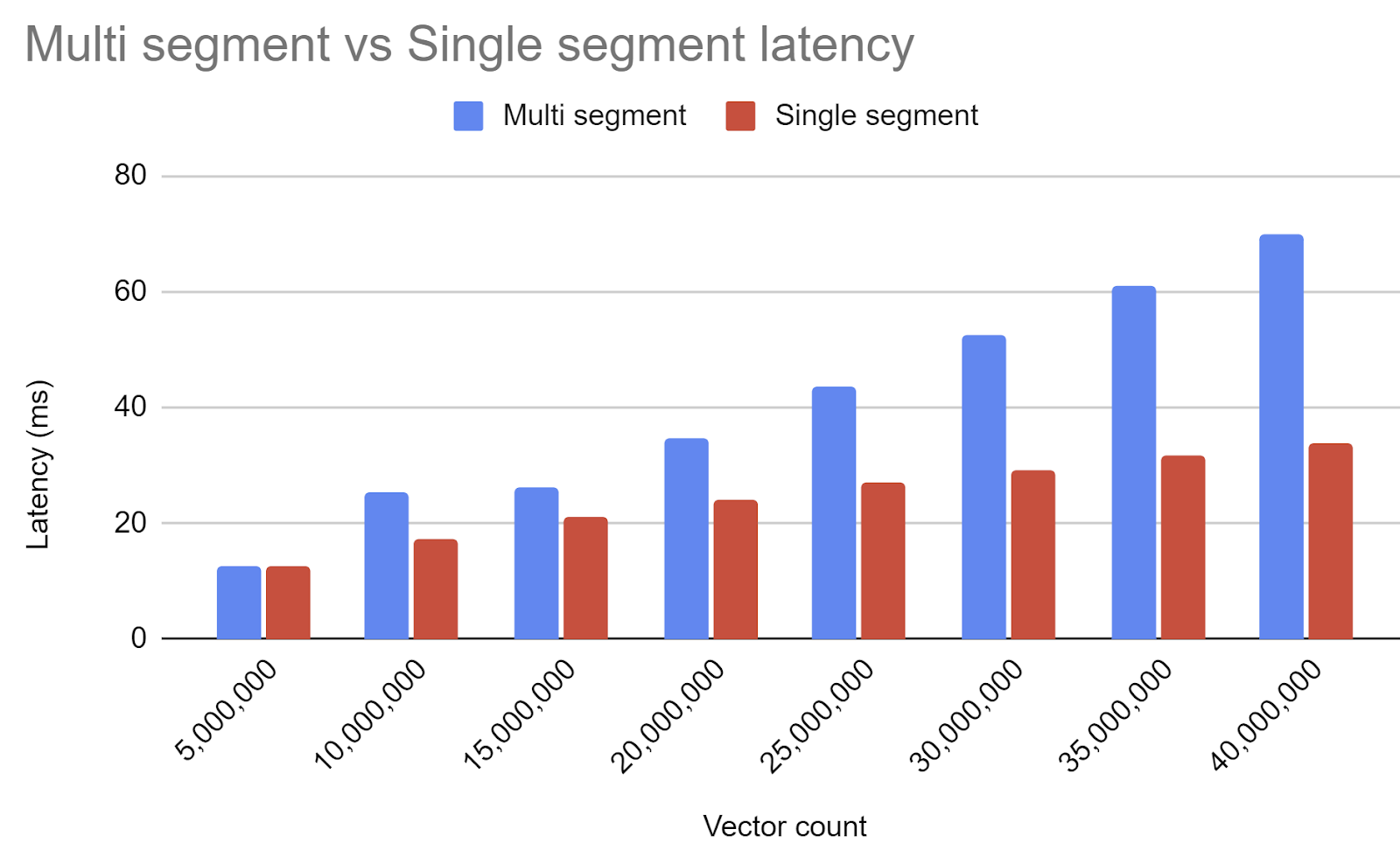
JVector, the library that powers DataStax Astra vector search, now supports indexing larger-than-memory datasets by performing construction-related searches with compressed vectors. This means that the edge lists need to fit in memory, but the uncompressed vectors do not, which gives us enough headroom to index Wikipedia-en on a laptop.
Requirements
- Linux or MacOS. It will not work on Windows because ChronicleMap, which we are going to use for the non-vector data, is limited to a 4GB size there. (If you are interested enough, you could shard the Map by vector id to keep each shard under 4GB and still have O(1) lookup times.)
- About 180GB of free space for the dataset, and 90GB for the completed index.
- Enough RAM to run a JVM with 36GB of heap space during construction (~28GB for the index, 8GB for GC headroom).
- Disable swap before building the index. Linux will aggressively try to cache the index being constructed to the point of swapping out parts of the JVM heap, which is obviously counterproductive. In my test, building with swap enabled was almost twice as slow as with it off.
Building and searching the index
- Check out the project:
$ git clone https://github.com/jbellis/coherepedia-jvector
$ cd coherepedia-jvector - Edit config.properties to set the locations for the dataset and the index.
- Run pip install datasets. (Setting up a venv or conda environment first is recommended but not strictly necessary.)
- Run python download.py. This downloads the 180 GB dataset to the location you configured. For me that took about half an hour.
- Run ./mvnw compile exec:exec@buildindex. This took about 5 and a half hours on my machine (with an i9-12900 CPU).
- Run ./mvnw compile exec:exec@serve and open a browser to http://localhost:4567. Search away!
How it works
We’re using JVector for the vector index and Chronicle Map for the article data. There are several things I don’t love about Chronicle Map, but nothing else touches it for simple disk-based key/value performance.
The full source of the index construction class is here. I’ll explain it next in pieces.
Compression parameters
JVector is based on the DiskANN vector index design, which performs an initial search using vectors compressed lossily with product quantization (PQ) in memory, then reranks the results using high-resolution vectors from disk. However, while DiskANN stores full, uncompressed vectors to perform reranking, JVector is able to improve on that using Locally-Adaptive Quantization (LVQ) compression.
To set this up, we’ll first load some vectors into a RandomAccessVectorValues (RAVV) instance. RAVV is a JVector interface for a vector container; it could be List or Map based, in-memory or on-disk. In this case we’ll use a simple List-backed RAVV. We’ll compute the parameters for both compressions (kmeans clustering for PQ, global mean for LVQ) from a single shard of the dataset. At about 110k rows, this is enough data to have a statistically valid sample.

Next, we compute the PQ compression codebook; we’re compressing the vectors by a factor of 64, because the Cohere v3 embeddings can be PQ-compressed that much without losing accuracy, after reranking. Binary Quantization only gives us 32x compression and is less accurate.

Finally, we need to set up LVQ. LVQ gives us 4x compression while losing no measurable accuracy over the full uncompressed vectors, resulting in both a smaller footprint on disk and faster searches. (I thank the vector search team at Intel Research for pointing this out to us.)

GraphIndexBuilder
Next, we need to instantiate and configure our GraphIndexBuilder.
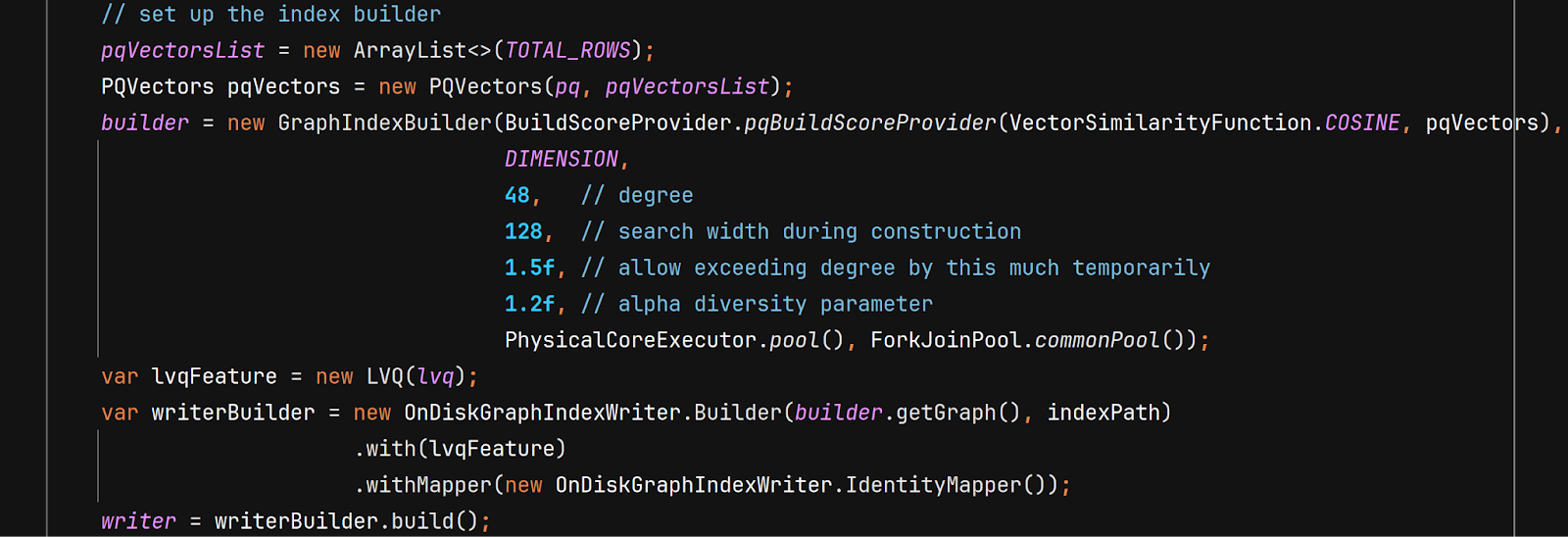
This instantiates a JVector GraphIndexBuilder and connects it to an OnDiskGraphIndexWriter, and tells it to use the PQ-compressed vectors list (which starts empty and will grow as we add vectors to the index) during construction (in the BuildScoreProvider).
Chronicle Map and RowData
We’ll store article contents in RowData records. This content is what has been encoded as the corresponding vector in the dataset, and is what we want to return to the user in our search results.

To turn the vector index’s search results (a list of integer vector ids) into RowData, we store the RowData in a Map keyed by the vector id. This will be a lot of data, so we use ChronicleMap to store this on disk with a minimal in-memory footprint.

We need to tell ChronicleMap how large it’s going to be, both in entry count and entry size. Undersizing these will cause it to crash (my primary complaint about ChronicleMap), so we deliberately use a high estimate.
We do not need to explicitly tell ChronicleMap how to read and write RowData objects, instead we just have RowData implement Serializable. While ChronicleMap supports custom de/serialize code, it’s perfectly happy to use simple out-of-the-box serialization and since profiling shows that’s not a bottleneck for us we’ll just leave it at that.
Ingesting the data
We use Java’s parallel Streams to process the shards in parallel. For each row in each shard, we
- Add it to pqVectorsList
- Call writer.writeInline to add the LVQ-compressed vector to disk
- Call builder.addGraphNode – order is important because both (1) and (2) are used when we call addGraphNode
- Call contentMap.put with the article chunk data.

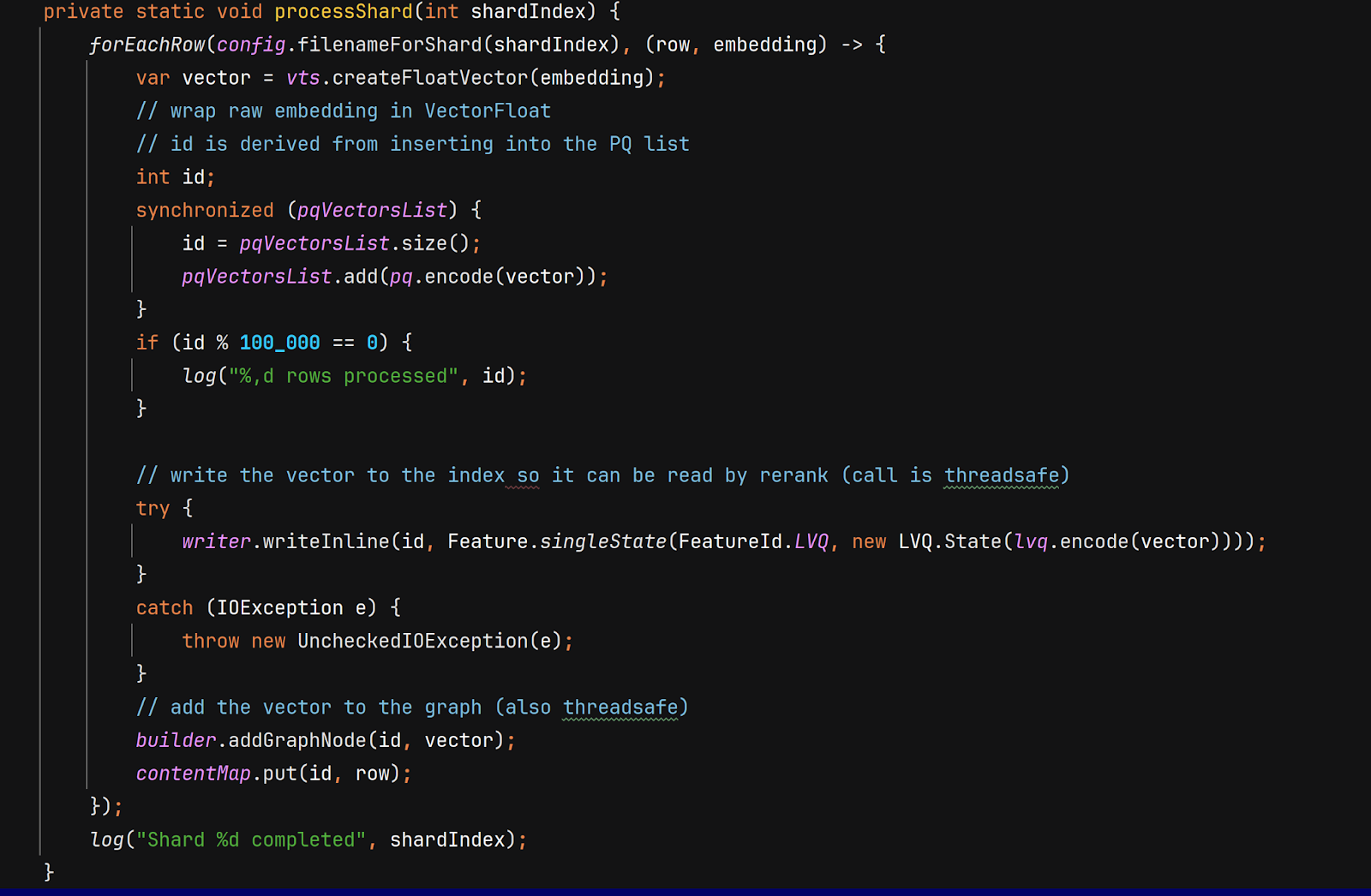
You can look at the full source if you’re curious about forEachRow, it’s just standard “pull data out of Arrow” stuff.
When the build completes, you should see files like this:
$ ls -lh ~/coherepedia
-rw-rw-r-- 1 jonathan jonathan 48G May 20 15:53 coherepedia.ann
-rw-rw-r-- 1 jonathan jonathan 36G May 20 18:05 coherepedia.map
-rw-rw-r-- 1 jonathan jonathan 2.5G May 20 15:53 coherepedia.pqv
-rw-rw-r-- 1 jonathan jonathan 4.1K May 17 23:04 coherepedia.lvq
-rw-rw-r-- 1 jonathan jonathan 1.1M May 17 23:04 coherepedia.pq
These are respectively
- ANN: the vector index, containing the edge lists and LVQ-compressed vectors for reranking.
- MAP: the map containing article data indexed by vector id.
- PQV: PQ-compressed vectors, which are read into memory and used for the approximate search pass.
- LVQ: the LVQ global mean, used during construction.
- PQ: the PQ codebooks, used during construction.
Loading the index (after construction)
The code for serving queries is found in the WebSearch class. We’re using Spark (the web framework, not the big data engine) to serve a simple search form:
Construction needed a relatively large heap to keep the edge lists in memory. With that complete, we only need enough to keep the PQ-compressed vectors in memory; exec@serve is configured to use a 4GB heap.
WebSearch (the class behind exec@serve) first has a static initializer to load the PQ vectors and open the ChronicleMap. We also create a reusable GraphSearcher instance:

Performing a search
Executing a search and turning it into RowData for the user looks like this:
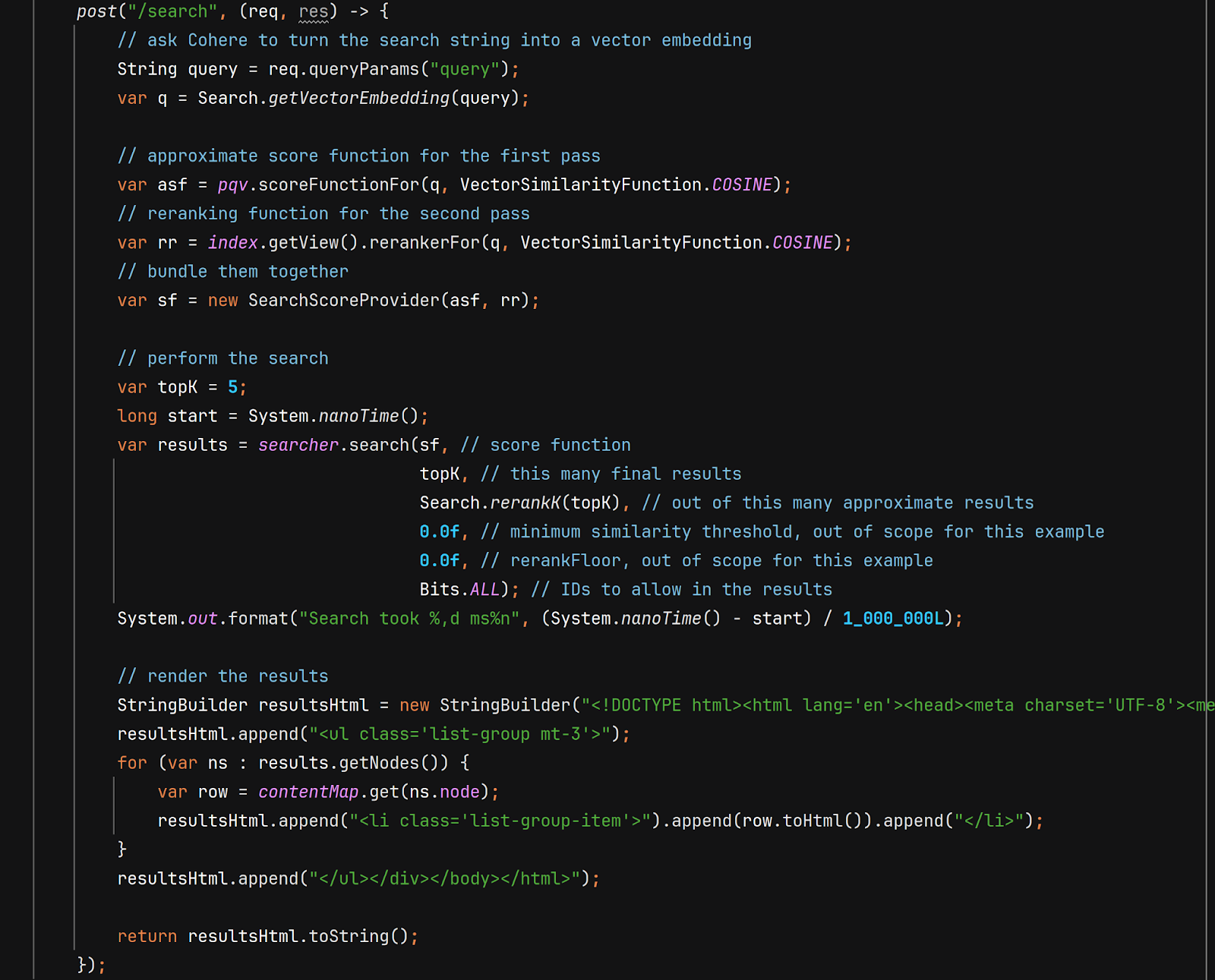
There are four “paragraphs” of code here, containing
- The call to getVectorEmbedding. This calls Cohere’s API to turn the search query (a String) into a vector embedding.
- Creating approximate and reranking score functions. Approximate scoring is done through our product quantization, and reranking is done with the LVQ vectors in the index. Since the LVQ vectors are encapsulated in the index itself, we never need to explicitly deal with LVQ decoding; the index does it for us.
- The call to searcher.search that actually does the query, and finally
- Retrieving the RowData associated with the top vector neighbors using contentMap.
That’s it! We’ve indexed all of Wikipedia with high performance, parallel code in about 150 loc, and created a simple search server in another 100.
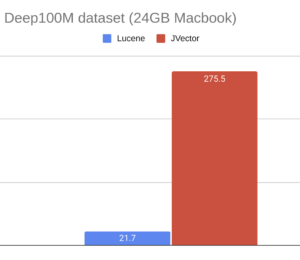
On my machine, searches (which each run in a single thread) take about 50ms. We would expect it to take over twice as long if this were split across multiple segments. We would also expect it to lose significant accuracy if searches were performed only with compressed vectors without reranking.
Conclusion
Indexing the entirety of English Wikipedia on a laptop has become a practical reality thanks to recent advances in the JVector library that will be part of the imminent 3.0 release. (Star the repo and stand by!) This article demonstrates how to do exactly that using JVector in conjunction with Chronicle Map, while also showcasing the use of LVQ to reduce index size while preserving accurate reranking.
To take advantage of the power of JVector alongside powerful indexing for non-vector data, rolled into a document api with support for realtime inserts, updates, and deletes, check out the DataStax Astra service.
Enjoy hacking with JVector and Astra!
Watch Java’s Place in the AI Revolution Webinar
Watch as Java Champions Frank Greco, Zoran Sevarac, and Pratik Patel feature in a live new webinar highlighting Java's place in the AI Revolution, focusing on Exploring AI/ML Using Pure Java Tools.
Watch Here!
- May 29, 2024
- 7 min read
Jonathan is the founder of Brokk (https://brokk.ai). Brokk keeps LLMs on-task in million-line codebases by adding compiler-grade understanding of your code's structure and semantics. Jonathan is also the author of JVector, co-founder of DataStax, and the founding project chair of Apache Cassandra.









Comments (8)
Vector indexing all of Wikipedia on a laptop tjake on May 29, 2024 at 12:05 Hacker News: Front Page - Bharat Courses
2 years ago[…] Article URL: https://foojay.io/today/indexing-all-of-wikipedia-on-a-laptop/ […]
Vector indexing all of Wikipedia on a laptop - CIBERSEGURANÇA
2 years ago[…] Read More […]
New best story on Hacker News: Vector indexing all of Wikipedia on a laptop – Cassinni
2 years ago[…] Vector indexing all of Wikipedia on a laptop 494 by tjake | 140 comments on Hacker News. […]
Vector indexing all of Wikipedia on a laptop – Latest-News-Events
2 years ago[…] Vector indexing all of Wikipedia on a laptop 494 by tjake | 140 comments . […]
Mobile development for week #540 (May 27 - June 2) - Prog.World
2 years ago[…] Unix clone in about a month• MobileLlama3: Run Llama3 locally on mobile• Big Data is Dead• Indexing all of Wikipedia, on a laptop• AI-Friendly Programming Languages: the Kotlin Story• Don't DRY Your Code Prematurely• […]
Mobile development for week #540 (May 27 - June 2) - TechBurst Magazine
2 years ago[…] • Indexing all of Wikipedia, on a laptop […]
Мобильная разработка на неделе №540 (27 мая – 2 июня) - Новостной вестник
2 years ago[…] на мобильном устройстве.• Большие данные мертвы• Индексируйте всю Википедию на ноутбуке• Языки программирования, адаптированные к ИИ: […]
Java Weekly, Issue 545 | Baeldung
2 years ago[…] >> Indexing all of Wikipedia, on a laptop [foojay.io] […]