

Preserving Software Continuity: Empowering Failover Strategies for Uninterrupted Operations
- November 16, 2023
- 5 min read
In today’s ever-changing and fast-paced digital landscape, maintaining uninterrupted business continuity is of utmost importance.
Enter Chronicle Services, a robust mechanism dedicated to upholding application integrity even in the face of service disruptions.
Let’s examine the world of failover strategies and explore how they safeguard software continuity.
Stateless vs. Stateful Services
It’s important to appreciate the difference between stateless and stateful services. Your choice of failover approach is highly influenced by this understanding, especially if the aim is to resume services seamlessly from where they were interrupted.
A stateless service, which can be likened to a pure function in functional programming, handles requests independently of previous occurrences and maintains no mutable state between them. The service will always produce the same output when supplied with the same input value(s). While the appeal of simplicity and lack of ordering concerns are enticing, not all facets of an application can be represented as stateless, hence the requirement for stateful services.
Contrarily, output from a stateful service depends on information from past invocations. Echoing the notion of side effects in functional programming, the output of a stateful service may differ for identical input due to this mutable state. In the event that a service fails and requires to be restarted, it is necessary to implement a strategy to recreate the service’s state as it was when it was stopped.
Event stores such as Chronicle Queue offer powerful and efficient ways of achieving this. All mutations to a service’s state are posted as events, and it is straightforward to reconstruct the state by replaying these events. The fast and efficient event processing of Chronicle Queue makes the task of replaying events manageable.
However, complexities might crop up when alterations are made to your business logic across different versions of your services. In such situations, the same input might yield a different output, creating possible problems in maintaining uniform system behavior. It’s crucial to remember here that while events that update the state are deterministic, business logic, which generates the events, might not be. Therefore, while the outcomes (events) of what you did (business logic) stay the same, the reasons why you do things (business logic) could evolve.
One effective mitigation strategy involves periodic snapshotting of system state into the output queue. By integrating these snapshots into the event queue, you establish consistent recovery points that capture the state of your system at specific intervals.
If a system restart or recovery occurs, the state can be rebuilt from the latest snapshot instead of replaying the entire history of events. This approach reduces the amount of data that needs to be processed, as well as speeds up the system recovery time.
Still, it’s crucial to strike a careful balance with the frequency of snapshots. This balance depends on factors such as data volume, business logic throughput, and desired recovery time, while also considering the storage costs and resources needed to create and manage these snapshots. Note: Snapshot generation can be time consuming, so Chronicle Services can support generation of snapshots on a background thread.
In summary, an amalgamated approach of efficient event replay using a tool like Chronicle Queue and strategic snapshotting can offer a robust solution for managing state in a continually evolving event-driven architecture. Note: It is also possible for Chronicle Services to handle replaying from the output queue and not just the input queue.
The Challenge of Failover: Rebooting Services and Reestablishing State
In failover situations, the critical task is rebooting a service and restoring its local state to align with the prior service instance. Chronicle Services provides tools for successful failover, specifically focusing on restoring state in stateful services.
Reinitializing a service and restoring its local state to reflect the preceding service instance’s state are key challenges in failover situations. This is particularly pertinent for stateful services, where consistency is a necessity.
The complexity is heightened when a warm standby instance is involved in the failover. The standby instance, kept in sync with the primary service, is poised to take over immediately. The challenge involves synchronizing the primary and standby instances and facilitating the standby’s seamless transition to primary mode during failover. This process demands meticulous coordination to ensure service continuity, which includes traffic rerouting and final state changes synchronization after the last update to the standby.
Consider an application with three services: Service-a, Service-b, and Service-c. While Service-a and Service-b are stateless, Service-c is stateful with a high sensitivity to event processing order.
In the wake of a service restart following a failover, it’s crucial to restore its internal state to match the point of failure. Chronicle Queue‘s dual role as an event transport and persistent storage mechanism enables this by replaying events stored on disk.
However, the reliability of this process depends on successfully syncing events to the disk before the primary service fails. In rare situations, such as kernel panic, this sync might not be assured. Unwritten data at the time of system failure might be lost, affecting precise state reconstruction during recovery. Implementing safeguards for regular and reliable data synchronization from memory to disk can minimize the risk of sudden data loss.
An effective risk mitigation strategy involves keeping a safe copy of the data on a separate machine, acting as a ‘warm standby’. This machine can be within the same network or geographically separate, to protect against simultaneous failures. Having a near up-to-date state of the system at failover time, the standby machine enables quicker recovery. To handle the case of the primary going down while messages are in-flight, consumers of the queue can be set up so they do not see the message in the queue until a safe copy of the message has been successfully acknowledged from the secondary, adopting this robust approach ensures that no messages are ever lost, but it comes at the cost of accepting the round trip network latency.
The restart of a service after a failover necessitates the alignment of its internal state with the point of failure.
The ‘History Record,’ an integral part of event replay, includes meta-information about each event, such as the originating service and posting time. Configuring the ‘startFromStrategy’ and ‘inputsReplayStrategy’ fields allows control over event processing order and choice of events for state reconstruction.
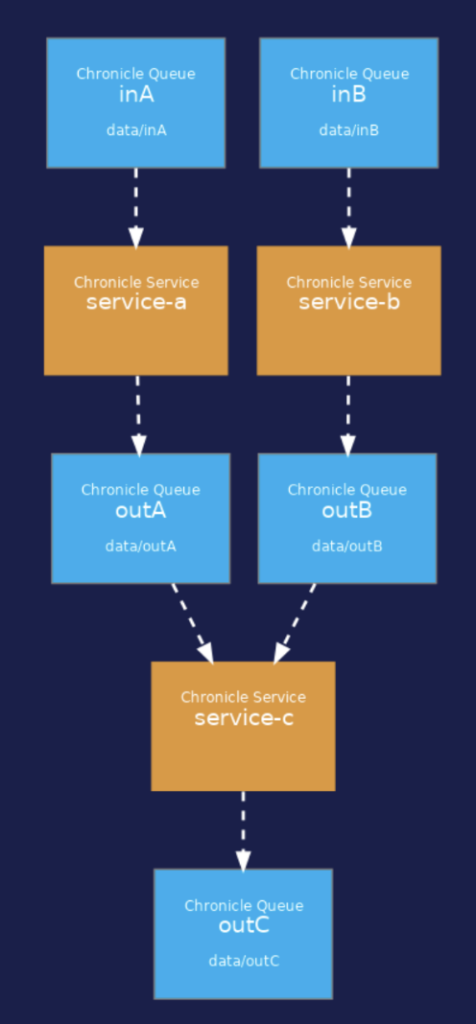
However, maintaining exact event order can be complex with multiple input queues. To navigate this challenge, Chronicle Services uses History Records for each input event, ensuring a strict time-ordered replay regardless of the queue origin.
Addressing Stateless Services in Failover Scenarios
In contrast, implementing failover for stateless services like Service-a and Service-b is relatively straightforward due to their lack of internal state. Upon restart, these services can directly read new events from the queue, conveniently ignoring those that don’t impact their state.
This default behavior, characterized by the ‘startFromStrategy’ property’s default value of ‘LAST_WRITTEN,’ obviates the need for event replay in stateless services.
In conclusion, by harnessing the power of Chronicle Services, both stateful and stateless services can seamlessly recover from failovers, ensuring robustness and high availability. The thoughtful interplay between service design, event replay, and strategic event handling mechanisms guarantees that the application state is safeguarded and accurately replicated during disruptions. As a result, continuity of service and operational efficiency are promoted, providing a resilient foundation for your software ecosystem.
Resources
For further details and examples of Chronicle Services, see the documentation portal here.
- November 16, 2023
- 5 min read
As a Java developer with more than 20 years of experience, primarily on trading systems for investment banks, he has mostly focused on performance-critical pricing systems. As one of the first employees at Chronicle Software, he has been instrumental in building up its suite of software libraries.






Comments (0)
No comments yet. Be the first.