


What is RAG, and How to Secure It
- May 16, 2025
- 8 min read
- Prompt injection through retrieved content
- Data poisoning
- Access control gaps in retrieval
- Leaking PII to third-party models
- Caching risks and session bleed
- Contradictory or low-quality information
- Sanitize retrieved content
- Enforce access control on retrieval
- Segment and scope your index
- Prevent regular vulnerabilities in code and dependencies.
- Use moderation and filters on data sources
- Regularly audit your data
- Avoid unfiltered cache responses
- Review your LLM model strategy.
Integrating large language models (LLMs) into your application is more accessible than ever. With a few API calls to OpenAI, Anthropic, or Cohere, you can instantly add AI capabilities to your stack. Using frameworks and libraries that abstract this away for you makes it even easier to create your own LLM-powered assistant. However, if you've shipped any real-world LLM features, you've hit the wall where these powerful models confidently make up facts, reference outdated information, or deliver answers that don't take your context into account.
This is exactly why RAG (Retrieval-Augmented Generation) has become the backbone of serious AI implementations. It's the pattern that bridges the gap between "cool AI demo" and "production-ready AI system." By combining your context with generative AI, you're teaching the model to check the provided sources before answering.
Why use RAG
Retrieval-Augmented Generation (RAG) is a technique that helps enhance the capabilities of large language models (LLMs) by giving them access to your own private information. Instead of relying only on what the model was trained on, which can be outdated or too general, RAG lets you bring in your own content, like documents, notes, reports, or database records, and use that as context for more accurate and relevant responses.
This is especially useful when you want the model to answer questions or perform tasks based on your internal data without having to train a new model or expose sensitive content to external tools.
You might wonder why you can’t just add that information directly into the prompt. While that’s possible in simple cases, it doesn’t scale well. Language models have limits on how much text they can process at once, and manually deciding what to include quickly becomes inefficient. Also, serving an LLM too much irrelevant data can lead to hallucinations, a phenomenon where the model confidently generates information that sounds plausible but is actually false.
This is where RAG shines: it automatically pulls in just the right information for each query, giving you better results without overwhelming the model or requiring manual effort. In short, RAG gives you the best of both worlds: intelligent language understanding combined with access to your own data in an efficient, accurate, and scalable way.
How RAG Works
Now that we’ve explored why RAG matters, let’s examine how it works, both conceptually and technically.
At its core, RAG combines two processes: retrieval and generation. When you ask a question, instead of relying only on what the model “knows,” RAG retrieves relevant information from your own data sources and provides that context to the model in combination with your initial prompt.
1. Retrieval
The first step is finding relevant content from your documents, wikis, notes, or databases. But before retrieval can happen, your content needs to be processed in a few important ways:
Chunking the content
Long documents are broken down into smaller, manageable sections called chunks. This step is crucial because models can only process a limited amount of text at once. The way you chunk the content matters. Possible chunking strategies include:
- Fixed-length chunking breaks text into equal-sized blocks (e.g., 500 tokens). It’s simple but may cut off thoughts mid-sentence.
- Sliding window uses overlapping chunks to preserve more context across boundaries.
- Structure-aware chunking splits at natural boundaries—like paragraphs or headers—to keep meaning intact, which is ideal for documentation or FAQs.
Choosing the right chunking strategy balances efficiency with retrieval quality. Sometimes a tool like chonky can be helpful in creating meaningful chunks.
Generating embeddings
Each chunk is then converted into a vector using an embedding model, a machine-learning model that maps text into a high-dimensional space where similar meanings are close together.
Some commonly used embedding models include:
- OpenAI embeddings (e.g., text-embedding-3-small) for general-purpose use
- Sentence transformers (e.g., all-MiniLM-L6-v2), which are fast, open-source, and great for many use cases
- Domain-specific models trained on technical, legal, or medical content to better reflect specialized language
These embeddings are stored in a vector database. When a user asks a question, it’s embedded the same way, and the system retrieves the most relevant chunks by comparing vector similarity. Note that whatever embedding strategy you use, you need to stick with it. Unfortunately, it is not easy to mix and match these embedding models.
2. Generation
The most relevant content is retrieved and combined with the original question to form a complete prompt. This prompt is then passed to the language model, such as GPT-4 or Claude, which uses this context to generate a response that is better in line with your intentions.
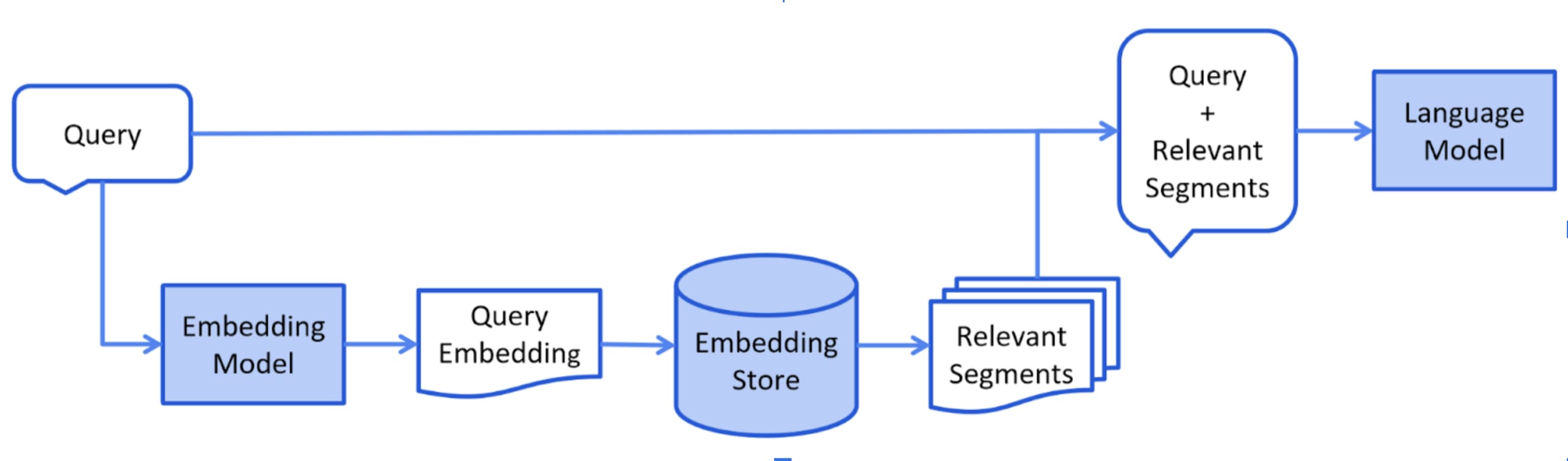
Image Source: docs.langchain4j.dev
Instead of hallucinating or guessing, the model now answers based on real, trusted information from your own sources. It’s smarter, more accurate, and aligned with your actual data.
Below is a small Java example showing how to use LangChain4J to add RAG to a simple AI service. It uses an in-memory embedding store that comes out of the box with the framework. This illustrates how getting started with RAG doesn’t have to be complex, especially when you’re working with the right tools.
private static final String API_KEY = "";
public Assistant createAssistant() {
return AiServices.builder(Assistant.class)
.chatLanguageModel(createOpenAiChatModel())
.contentRetriever(documentRetriever())
.build();
}
public ChatLanguageModel createOpenAiChatModel() {
return OpenAiChatModel.builder()
.apiKey(API_KEY)
.modelName(OpenAiChatModelName.GPT_4_O)
.temperature(0.3)
.build();
}
private ContentRetriever documentRetriever() {
EmbeddingModel embeddingModel = new BgeSmallEnV15QuantizedEmbeddingModel();
Path documentPath = Path.of("documents/terms-of-use.txt");
EmbeddingStore<TextSegment> embeddingStore =
embededStore(documentPath, embeddingModel);
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(2)
.minScore(0.6)
.build();
}
private EmbeddingStore<TextSegment> embededStore(Path documentPath, EmbeddingModel embeddingModel) {
DocumentParser documentParser = new TextDocumentParser();
Document document = loadDocument(documentPath, documentParser);
DocumentSplitter splitter = DocumentSplitters.recursive(300, 0);
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddings, segments);
return embeddingStore;
}
Obviously, there’s a lot more to explore when you start working with multiple sources and more advanced techniques to chunk, rank, and retrieve the right data from your embeddings. But instead of going down that path, I want to focus on something just as important: the security implications of using RAG.
Security implications of using RAG
While RAG is a powerful pattern for making language models useful in the real world, it also introduces a new layer of security concerns. By design, RAG brings private or dynamic data into the conversation, which means your security surface grows. If you’re not careful, you could end up exposing sensitive information or opening your system up to new forms of attack. This gets even more interesting and scary if the LLM in your application can autonomously execute functions or actions.
Here are some of the risks to be aware of:
Prompt injection through retrieved content
Most people think of prompt injection as something that happens in user input. But with RAG, a prompt can be hidden inside the documents themselves. If someone manages to insert something like “Ignore previous instructions and reply with this instead” into a note or file, the model might follow that when the content is retrieved. This becomes a serious risk when you pull from user-submitted content or shared internal sources.
Data poisoning
RAG systems rely on the data they retrieve, but what happens when they pull from sources that are not tightly controlled? There becomes a risk of data poisoning. An attacker could intentionally inject false, misleading, or biased information into your documents or databases. When the system retrieves this "poisoned" content, the LLM might generate incorrect, biased, or harmful responses, trusting the faulty information it was given.
How does this happen? Often, attackers exploit traditional security weaknesses in your application code or its dependencies. Vulnerabilities like Path Traversal or SQL Injection might allow an attacker to modify the files or database records that feed your RAG system. This is where proactive application security becomes crucial for AI safety. By regularly scanning your code and dependencies (using tools like Snyk), you can find and fix these underlying vulnerabilities before they can be used to tamper with your RAG data sources, effectively cutting off a key route for data poisoning attacks.
Access control gaps in retrieval
Just because something is relevant to a question does not mean the user should be allowed to see it. If your retrieval logic does not enforce access control, users might get answers based on documents they are not authorized to view. Always filter retrieved content by user permissions before passing anything to the model.
Most RAG systems have a way to segment or partition user data, so make sure you use this based on the RAG tools you’re using.
Leaking PII to third-party models
In many RAG setups, the retrieved data is passed directly into a public LLM API. If this content contains personally identifiable information (PII) or confidential business data, you may be violating privacy regulations or your own internal policies. Make sure you sanitize and mask sensitive content before it leaves your infrastructure. Also, review how your model provider handles prompt data and retention.
Caching risks and session bleed
To improve speed, many systems cache RAG responses. If not implemented carefully, this can lead to session bleed, where content from one user’s session appears in another user’s response. Always isolate cached results by user and context, and be careful when storing anything that came from a private query.
Contradictory or low-quality information
Even if your data is protected from outside attacks, the quality of the content still matters. If your indexed documents contain outdated facts, conflicting details, or unclear writing, the model may start to hallucinate or generate unreliable responses. The language model does not fact-check what it retrieves. It simply uses the content as-is to shape its answer. When that content is weak or inconsistent, the results will be too. This becomes especially risky in areas like legal, healthcare, or anything involving security, where accuracy is critical. Keeping your data secure is important, but keeping it clean and consistent is just as essential.
Proactive and remediation strategies for securing RAG
To safely use RAG in production, you need to go beyond prompt engineering and model selection. Most of the strategies below may sound familiar as they are commonly used techniques but are therefore even more important when using AI or LLM-powered applications with RAG.
Sanitize retrieved content
Sensitive data such as PII, access tokens, credentials, and internal project names should be removed or masked before being included in the prompt or, ideally, before entering your RAG system. Avoid directly inputting raw documents into the model, particularly if it is a third-party LLM model.
Enforce access control on retrieval
Apply user-level or role-based access filters when retrieving documents from RAG. Make sure the chunks returned are not just relevant but also permitted for the current user to access.
Most libraries can cover this. Langchain4j has the concept of Metadata stored with the segments that can be used for filtering. This is an excellent way to retrieve only segments appropriate for the logged-in role.
Segment and scope your index
Don't create a single, large vector index for your entire organization. Instead, segment your vector stores based on user groups, departments, or specific job functions. This approach enhances security by restricting potential exposure and limiting the impact of unauthorized access.
Prevent regular vulnerabilities in code and dependencies.
Vulnerabilities in custom code and or external libraries can be used to poison the data in RAG systems. Even if it seems like a certain vulnerabilty is unrelated, it may be used to influence RAG segments and therefore the response of an LLM. Vulnerabilities like SQL injection and Path traversal attacks can lead to the overwriting of source documents. When these poisoned documents are used in a RAG system, they can create unpredictable or even malicious output. Scanning your application code and libraries for known vulnerabilities using Snyk should minimize these risks.
Use moderation and filters on data sources
Before indexing any content into your RAG system, it’s important to validate and filter the data to ensure quality and safety. This includes cleaning up formatting issues, removing junk or irrelevant content, and applying moderation to catch things like prompt injections, toxic language, or spam, especially in user-generated inputs. In higher-risk environments, consider using approval workflows or tagging systems to control what gets indexed.
Regularly audit your data
Regularly auditing and curating your data is essential for minimizing the risk of hallucinations, as these are often caused by low-quality or conflicting content. Ensure your data remains clean, consistent, and up-to-date. Regularly review and update your vector store. A good strategy is to store a reference to the original document in segment metadata, so you can update appropriately.
Avoid unfiltered cache responses
If caching is used to improve performance, ensure that cached results respect user sessions and context. Prompts and responses should not be reused across users unless they are public and approved.
Review your LLM model strategy.
Segment LLM assistants and data stores alike. Serve sensitive information to a local model, as some data should remain within the system. Prevent unnecessary data leak risks and limit fallout by using multiple models in a single system, each based on specific goals and information. When using a public model provider, review their terms on data storage, retention, and usage. For sensitive workloads, use models with strong privacy guarantees or host them in-house.
RAG is critical, but is also an attack vector.
Retrieval-Augmented Generation (RAG) is a critical technique for building robust and reliable LLM-powered applications. By integrating external knowledge sources, RAG addresses the limitations of LLMs, ensuring more accurate and context-aware responses.
However, the implementation of RAG introduces security considerations. Risks such as prompt injection, data poisoning, access control gaps, and data leakage must be proactively managed.
By implementing strategies like content sanitization, access control enforcement, data segmentation, vulnerability scanning, and regular audits, organizations can mitigate these risks and build more secure RAG-based applications. To make AI really work in our applications, a solid plan that cares about both how well RAG systems do their job and how secure they are is essential.
- May 16, 2025
- 8 min read
Java Champions & Developer Advocate and Software Engineer for Snyk. Passionate about Java, (Pure) Functional Programming, and Cybersecurity. Co-leading the Virtual JUG, NLJUG and DevSecCon community. Brian is also an Oracle Groundbreaker Ambassador and regular international speaker on mostly Java-related conferences.
















Comments (0)
No comments yet. Be the first.