

High Performance Rendering in JavaFX
- January 18, 2021
- 6 min read
In this article, we comparatively evaluate four different approaches to render particles in JavaFX in terms of runtime performance.
The approaches are Canvas, PixelBuffer AWT, PixelBuffer CPU and PixelBuffer GPU.
The evaluation suggests the following order of approaches from fastest to slowest:
- PixelBuffer GPU (fastest).
- PixelBuffer CPU.
- PixelBuffer AWT.
- Canvas (slowest).
All of the source code developed for this article can be found on GitHub. An example demo with 1 000 000 particles looks like this:
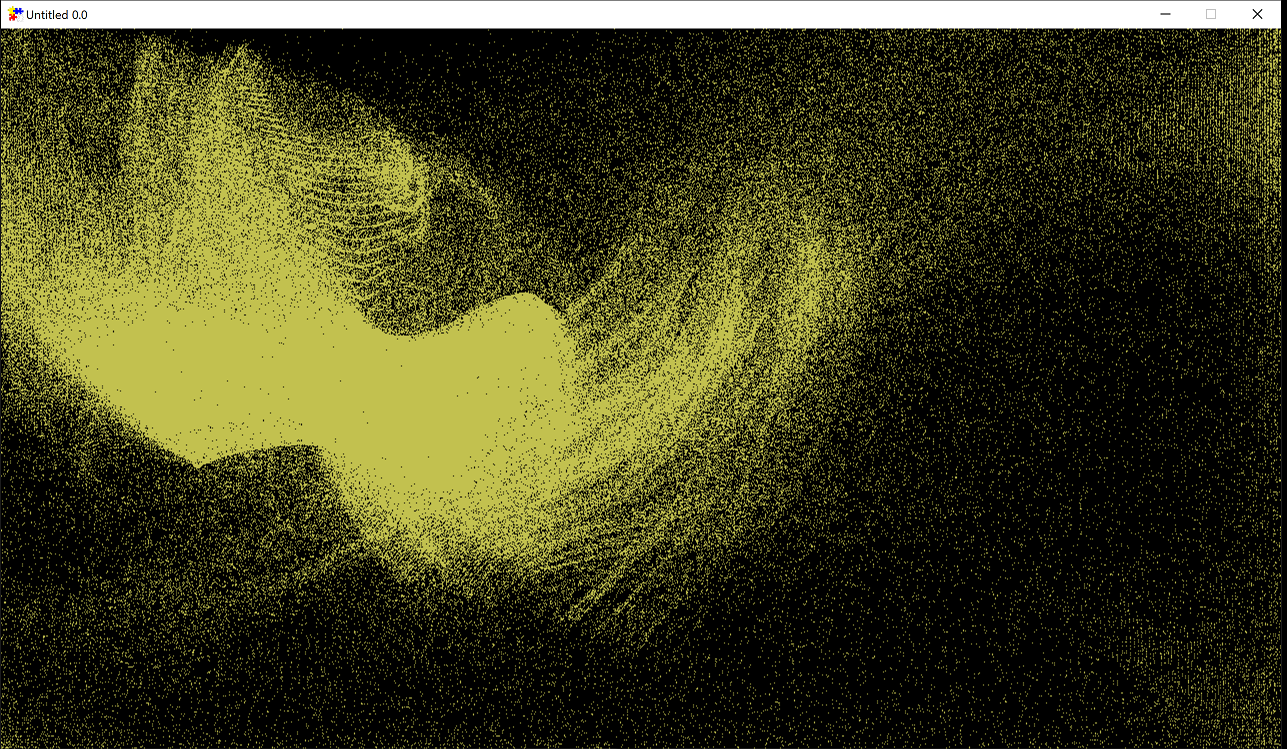
Introduction
There is a number of use cases that involve rendering a huge number of individual pixels as quickly as possible, including point cloud visualizations, particle effects and simulations. As mentioned above, in JavaFX, developers have several approaches (techniques) of rendering pixels to the screen.
In this section, we provide a brief overview of these techniques. In the next section, we specify how the evaluation was set up. Thereafter, the evaluation results are provided with a brief discussion on the limitations of these findings. Finally, we discuss how the evaluation can be improved in future iterations.
Canvas
The Canvas API has been available since the early versions of JavaFX and is the most commonly used API. It is both intuitive and simple to use as it provides command-style methods to manipulate the associated GraphicsContext, simulating immediate rendering mode. One considerable limitation of Canvas is that only one thread can use its graphics context at a time. Given this limitation, we expect Canvas to be slowest in our evaluation. Sample code:
var canvas = new Canvas(width, height); var g = canvas.getGraphicsContext2D(); g.setFill(color); g.fillRect(x, y, 1, 1);
PixelBuffer CPU
The PixelBuffer API has been introduced in JavaFX 13 and allows drawing into a WritableImage without copying the pixel data. Unlike the Canvas API, this buffer does not provide any means of rasterization. In other words, the developer is responsible for converting shapes into pixels, which is a significant limitation of this approach. In the following sample code, there are two major differences, when compared to the Canvas API. First, colors are represented as a single ARGB int and second, we need to manually update the buffer once rendering is done. Sample code:
// set up pixel buffer IntBuffer buffer = IntBuffer.allocate(width * height); int[] pixels = buffer.array(); PixelBuffer<IntBuffer> pixelBuffer = new PixelBuffer<>(width, height, buffer, PixelFormat.getIntArgbPreInstance()); WritableImage image = new WritableImage(pixelBuffer); // draw a single _red_ pixel int alpha = 255; int red = 255; int green = 0; int blue = 0; int colorARGB = alpha << 24 | red << 16 | green << 8 | blue; pixels[(x % width) + (y * width)] = colorARGB; // tell the buffer that the entire area needs redrawing pixelBuffer.updateBuffer(b -> null);
PixelBuffer AWT
As can be seen from above, in PixelBuffer, there is no high-level API to draw arbitrary shapes. Clearly, this is not ideal since the developer would need to reimplement many of the rasterization methods. To avoid this, we can make use of AWT BufferedImage and its Graphics2D API, since both BufferedImage and PixelBuffer can share the same pixel data. An example implementation has been provided by Michael Paus. The same implementation is used in our evaluation with negligble changes, which were required to incorporate the code into our framework. Sample code:
var image = new AWTImage(width, height); var g = image.getGraphicsContext(); g.setColor(color); g.fillRect(x, y, 1, 1); // tell the buffer that the entire area needs redrawing image.getPixelBuffer().updateBuffer(b -> null);
PixelBuffer GPU
Having seen preliminary tests with the three techniques above, Dirk Lemmermann and Tom Schindl have hinted that moving the drawing algorithm to GPU would improve performance. It is known that running particles on the GPU can significantly outperform the CPU approach, particularly in games. It is not suprising given modern graphics cards, such as NVIDIA RTX 2080, have 2944 CUDA cores, capable of GPGPU. However, by using only public API in JavaFX we do not have a straightforward way of accessing the GPU video memory. As a result, our approach can be described as follows:
- GPU: initialize particles.
- GPU: run a single frame.
- CPU from GPU: get particle data.
- CPU to GPU: send particle data for rendering.
- GPU: render frame.
We can see that if we had direct access to GPU video memory, for example via DriftFX, we would not need steps 3 and 4. However, the tests in our evaluation do not meet the Java 8 requirement of DriftFX, hence it was not included in the evaluation.
However, for completeness, we also consider the GPU-accelerated version of PixelBuffer in our evaluation. This version uses the aparapi framework to dynamically convert and run Java bytecode on the GPU using OpenCL. Whilst the drawing code, using the ARGB color format to set pixels, remained the same, the architecture required significant changes to allow running on the GPU. We note that to correctly run this approach, the graphics card needs to support OpenCL and have the appropriate drivers installed. Sample code:
public class ParticleKernel extends Kernel {
int[] pixels = ...;
@Override
public void run() {
// draw pixels on GPU
pixels[(x % width) + (y * width)] = colorARGB;
}
}
var gpuKernel = new ParticleKernel();
// run drawing code on GPU
gpuKernel.execute(NUM_PARTICLES);
// get pixel information from GPU so we can update PixelBuffer
int[] pixels = gpuKernel.get(gpuKernel.pixels);
Evaluation
The model used for the evaluation is a particle system with 1M (1_000_000) particles. Conceptually, each particle is defined as follows:
class Particle {
Vec2 position = new Vec2();
Vec2 velocity = new Vec2();
Vec2 acceleration = new Vec2();
void update() {
position += velocity;
velocity += acceleration;
acceleration = (mousePosition - position) * XXXX;
}
}
The acceleration computation takes into account the mouse position in order to incorporate user interaction, as is common in many real-world applications. This model represents an embarrassingly parallel problem and can, therefore, be computed in parallel. In our evaluation, all approaches, except for Canvas (for which the reason was outlined earlier), can be run in parallel. In total, each approach computed 1100 frames of this model, during which using System.nanoTime() we recorded the time the approaches took to compute each frame. The first 100 frames were discarded to account for the JIT compiler on the JVM. Hence, the time measurements were recorded only for the last 1000 frames. In addition, we included a 10M (10_000_000) particle test on GPU, given that there was likely to be a sufficient performance margin.
The evaluation was performed on a 6-core Intel i9-8950HK, running at a fixed 2.6GHz (without Turbo) and 32 GB of RAM, with a NVIDIA GTX 1080 graphics card. The OS and environment details are as follows:
OS name: "windows 10", version: "1909"
$ java -version
openjdk 14.0.2 2020-07-14
OpenJDK Runtime Environment (build 14.0.2+12-46)
OpenJDK 64-Bit Server VM (build 14.0.2+12-46, mixed mode, sharing)
JavaFX version: 15No active foreground applications, except for the IntelliJ IDE, were running at the time of the evaluation.
Results
The evaluation results are available from the table below, which shows the amount of time that each approach took to compute a single frame. The values are given to 2d.p. in milliseconds. Each column provides the following information:
- Min - the minimum amount of time spent to compute 1 frame.
- Avg - the average amount of time spent to compute 1 frame.
- 95% - the amount of time spent to compute 1 frame in 95% of the cases.
- 99% - the amount of time spent to compute 1 frame in 99% of the cases.
- Max - the maximum amount of time spent to compute 1 frame.
| Approach | Min | Avg | 95% | 99% | Max |
|---|---|---|---|---|---|
| Canvas | 57.10 | 67.70 | 76.50 | 89.99 | 114.89 |
| PixelBuffer CPU | 8.33 | 11.29 | 16.91 | 16.76 | 24.65 |
| PixelBuffer AWT | 40.08 | 44.84 | 49.25 | 50.68 | 63.47 |
| PixelBuffer GPU | 1.63 | 2.04 | 2.33 | 3.54 | 3.79 |
| PixelBuffer GPU (10M) | 6.41 | 8.89 | 10.77 | 11.03 | 11.15 |
From the results, we can readily see that the PixelBuffer GPU approach significantly outperforms Canvas and PixelBuffer AWT. On average, it also computes a single frame up to 5.5 times faster than its CPU counterpart. Even with 10M particles, the PixelBuffer GPU approach is fastest, compared to the other three techniques. Unsurprisingly, the Canvas approach is slowest. However, we should note that the PixelBuffer CPU approach is faster at the expense of manual pixel drawing -- as mentioned earlier, there is no high-level API.
We should be mindful that the results of the evaluation are limited to the implementation of approaches and the use case context. For example, as Laurent Bourgès correctly pointed out, the evaluation does not provide a direct comparison of Java functions (for example, fillRect() and setPixels()), but instead provides a test in a practical setting, where parallel computing is an option. Therefore, these results do not generalize to use cases where rasterization methods are used, such as drawOval() or drawPolygon(). Laurent also indicated that there might be unnecessary write operations to PixelBuffer when particles overlap. The effect of an unnecessary write operation (against checking if the write is needed) was not evaluated.
Another potential limitation is the particle system model implementation, which could have affected the runtime performance of these techniques. Whilst the same model was used for each technique, it is not clear whether the model architecture could have favored one approach over the other.
Conclusion
In this article, we evaluated four different approaches to render individual pixels to the screen in JavaFX. By appealing to their runtime performance, the evaluation revealed that the PixelBuffer approach in conjunction with running on GPU is fastest among the evaluated techniques.
It would be interesting to see if custom rasterization methods, such as drawing a rectangle or a circle, can be implemented to run on the GPU, thus overcoming the API limitation of PixelBuffer. In turn, this new approach would allow JavaFX applications to fully harness GPU cores.
A further evaluation of such an approach against existing state-of-the-art would be needed to provide a relative ranking of techniques in terms of performance.
Acknowledgements
Many thanks to the members of the JavaFX community on Twitter who have pointed me towards relevant sources of information. If you spot an error in implementation or have suggestions on how to improve performance, please contact me on Twitter.
- January 18, 2021
- 6 min read
Principal Lecturer, Computing Department Lead at the University of Brighton. Author of #FXGL game engine. #Java #JavaFX #Kotlin open sourcerer. PhD in Computer Science.










Comments (2)
Lou
5 years agoThis was helpful - hope to see lots of JavaFX related stuff here!
我问我我我
2 years agoThis article is very helpful! Thank you for your work. Is there any component or method in javafx or fxgl that can easily use gpu for UI and game screen rendering? It would be hell for me to draw each pixel manually.