


It’s 2AM Do you Know What Your Code is Doing?
- September 01, 2023
- 6 min read
- Observability isn’t Pillars
- Tracing and OpenTelemetry
- Background Developer Observability
- Enough Exposition
- How Does This Help at 2AM?
- Final Word
Once we press the merge button, that code is no longer our responsibility. If it performs sub-optimally or has a bug, it is now the problem of the DevOps team, the SRE, etc. Unfortunately, those teams work with a different toolset. If my code uses up too much RAM, they will increase RAM. When the code runs slower, they will increase CPU. In case the code crashes, they will increase concurrent instances.
If none of that helps they will call you up at 2AM. A lot of these problems are visible before they become a disastrous middle of the night call. Yes. DevOps should control production, but the information they gather from production is useful for all of us. This is at the core of developer observability which is a subject I’m quite passionate about. I’m so excited about it I dedicated a chapter to it in my debugging book.
Back when I wrote that chapter I dedicated most of it to active developer observability tools like Lightrun, Rookout, et al. These tools work like production debuggers, they are fantastic in that regard. When I have a bug and know where to look I can sometimes reach for one of these tools (I used to work at Lightrun so I always use it).
But there are other ways. Tools like Lightrun are active in their observability, we add a snapshot similarly to a breakpoint and get the type of data we expect. I recently started playing with Digma which takes a radically different approach to developer observability. To understand that we might need to revisit some concepts of observability first.
Observability isn’t Pillars
I’ve been guilty of listing the pillars of observability just as much as the next guy. They’re even in my book (sorry). To be fair, I also discussed what observability really means…
Observability means we can ask questions about our system and get answers or at least have a clearly defined path to get those answers. Sounds simple when running locally, but when you have a sophisticated production environment and someone asks you: is anyone even using that block of code?
How do you know?
You might have lucked out and had a log in that code and it might still be lucky that the log is in the right level and piped properly so you can check. The problem is that if you added too many logs or too much observability data, you might have created a disease worse than the cure: over-logging or over-observing.
Both can bring down your performance and significantly impact the bank account, so ideally we don’t want too many logs (I discuss over-logging here) and we don’t want too much observability.
Existing developer observability tools work actively. To answer the question if someone is using the code I can place a counter on the line and wait for results. I can give it a week's timeout and find out in a week. Not a terrible situation but not ideal either, I don’t have that much patience.
Tracing and OpenTelemetry
It’s a sad state of affairs that most developers don’t use tracing in their day-to-day job. For those of you who don’t know it, it is like a call stack for the cloud. It lets us see the stack across servers and through processes. No, not method calls. More at the entry point level, but this often contains details like the database queries that were made and similarly deep insights.
There’s a lot of history with OpenTelemetry which I don’t want to get into, if you’re an observability geek you already know it and if not then it’s boring. What matters is that OpenTelemetry is taking over the world of tracing. It’s a runtime agent which means you just add it to the server and you get tracing information almost seamlessly. It’s magic.
It also doesn’t have a standard server which makes it very confusing. That means multiple vendors can use a single agent and display the information it collects to various demographics:
- A vendor focused on performance can show the timing of various parts in the system.
- A vendor focused on troubleshooting can detect potential bugs and issues.
- A vendor focused on security can detect potential risky access.
Background Developer Observability
I’m going to coin a term here since there isn’t one: Background Developer Observability. What if the data you need was already here and a system already collected it for you in the background?
That’s what Digma is doing. In Digma's terms, it's called Continuous Feedback. Essentially, they’re collecting OpenTelemetry data, analyzing it and displaying it as information that’s useful for developers. If Lightrun is like a debugger, then Digma is like SonarQube based on actual runtime and production information.
The cool thing is that you probably already use OpenTelemetry without even knowing it. DevOps probably installed that agent already, and the data is already there!
Going back to my question, is anyone using this API?
If you use Digma you can see that right away. OpenTelelbery already collected the information in the background and the DevOps team already paid the price of collection. We can benefit from that too.
Enough Exposition
I know, I go on… Let’s get to the meat and potatoes of why this rocks. Notice that this is a demo, when running locally the benefits are limited. The true value of these tools is in understanding production, still they can provide a lot of insight even when running locally and even when running tests.
Digma has a simple and well-integrated setup wizard for IntelliJ/IDEA. You need to have Docker Desktop running for setup to succeed. Note that you don’t need to run your application using Docker, this is simply for the Digma server process where they collect the execution details.
Once it is installed, we can run our application, in my case I just ran the JPA unit test from my latest book and it produced standard traces which are already pretty cool, we can see them listed below:
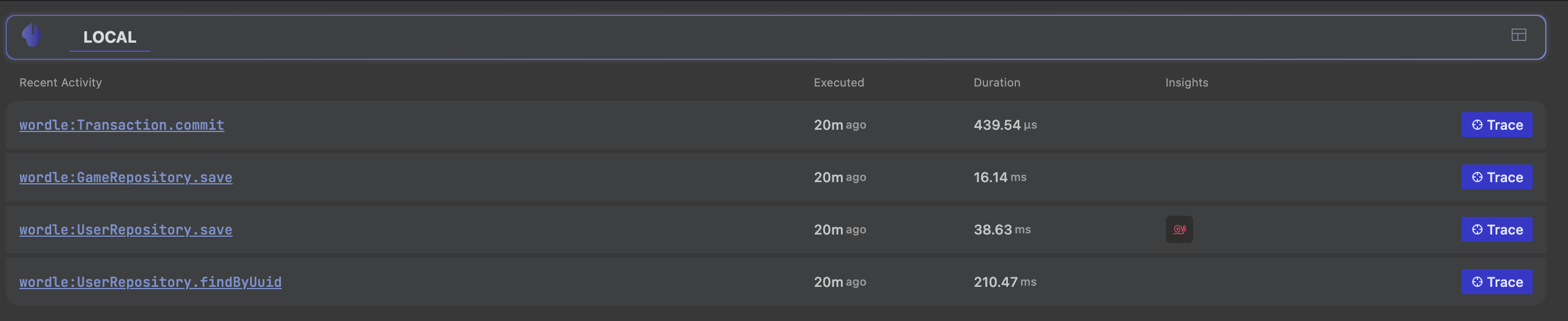
When we click a trace for one of these, we get the standard trace view, this is nothing new, but it’s really nice to see this information directly in the IDE and readily accessible. I can imagine the immense value this will have for figuring out CI execution issues:

But the real value and where Digma becomes a “Developer Observability” tool instead of an Observability tool, is with the tool window here:

There is a strong connection to the code directly from the observability data and deeper analysis which doesn’t show in my particular overly simplistic hello world. This Toolwindow highlights problematic traces, errors and helps understand real-world issues.
How Does This Help at 2AM?
Disasters happen because we aren’t looking. I’d like to say I open my observability dashboard regularly but I don’t. Then when there’s a failure I take a while to get my bearings within it. The locality of the applicable data is important, it helps us notice issues when they happen. Detect regressions before they turn to failures and understand the impact of the code we just merged.
Prevention starts with awareness and as developers, we handed our situational awareness to the DevOps team.
When the failure actually happens, the locality and accessibility of the data makes a big difference. Since we use tools that integrate in the IDE daily this reduces the meantime to a fix. No, a background developer observability tool might not include the information we need to fix a problem. But if it does, then the information is already there and we need nothing else. That is fantastic.
Final Word
With all the discussion about observability and open telemetry, you would think everyone is using them. Unfortunately, the reality is far from that. Yes, there’s some saturation and familiarity in the DevOps crowd. This is not the case for developers.
This is a form of environmental blindness. How can our teams who are so driven by data and facts proceed with secondhand and often outdated data from OPS?
Should I spend time further optimizing this method or will I waste the effort, since few people use it?
We can benchmark things locally just fine, but real-world usage and impact are things that we all need to improve.
- September 01, 2023
- 6 min read
Author, DevRel, Blogger, Open Source Hacker, Java Rockstar, Conference Speaker, Instructor and Entrepreneur.













Comments (0)
No comments yet. Be the first.