

Java 23 Has Arrived, And It Brings a Truckload of Changes
- September 17, 2024
- 28 min read
- JEP 455: Primitive Types in Patterns, instanceof, and switch (Preview)
- JEP 476: Module Import Declarations (Preview)
- JEP 477: Implicitly Declared Classes and Instance Main Methods (Third Preview)
- JEP 482: Flexible Constructor Bodies (Second Preview)
- What Happened to String Templates?
- JEP 466: Class-File API (Second Preview)
- JEP 469: Vector API (Eighth Incubator)
- JEP 473: Stream Gatherers (Second Preview)
- JEP 471: Deprecate the Memory-Access Methods in sun.misc.Unsafe for Removal
Java 23 has arrived! It's been six months since Java 22 was released, so it's time for a fresh truckload of JEPs.
In this article, we take you on a tour of everything that is part of this release, giving you a brief introduction to each of them.
Where applicable the differences with Java 22 are highlighted and a few typical use cases are provided, so that you'll be more than ready to start using these features after reading this.
From Project Amber
Java 23 contains 4 features that originated from Project Amber:
- Primitive Types in Patterns, instanceof, and switch (Preview)
- Module Import Declarations (Preview)
- Implicitly Declared Classes and Instance Main Methods (Third Preview)
- Flexible Constructor Bodies (Second Preview)
The goal of Project Amber is to explore and incubate smaller, productivity-oriented Java language features.
JEP 455: Primitive Types in Patterns, instanceof, and switch (Preview)
Pattern matching has become more prominent in Java since Java 16, but its support for primitives was always limited to nested record patterns. This JEP proposes to support primitive types in all pattern contexts, and to extend instanceof and switch to work with all primitive types.
Pattern Matching for Switch
Pattern matching for switch currently doesn't support type patterns that specify a primitive type. This JEP proposes to add support for primitive type patterns in switch, allowing the following code example:
switch (reverb.roomSize()) {
case 1 -> "Toilet";
case 2 -> "Bedroom";
case 30 -> "Classroom";
default -> "Unsupported value: " + reverb.roomSize();
}
...to be written as follows:
switch (reverb.roomSize()) {
case 1 -> "Toilet";
case 2 -> "Bedroom";
case 30 -> "Classroom";
case int i -> "Unsupported int value: " + i;
}
This also allows guards to inspect the matched value, like so:
switch (reverb.roomSize()) {
case 1 -> "Toilet";
case 2 -> "Bedroom";
case 30 -> "Classroom";
case int i when i > 100 && i < 1000 -> "Cinema";
case int i when i > 5000 -> "Stadium";
case int i -> "Unsupported int value: " + i;
}
Record Patterns
Record patterns currently have limited support for primitive types.
Recall that a record pattern decomposes a record into its individual components, but when one of them is a primitive type, the record pattern must be precise about its type. To illustrate this point, consider the following code example:
record Tuner(double pitchInHz) implements Effect {}
var tuner = new Tuner(440); // int argument is widened to double
// Attempt 1: record pattern match on int argument
if (tuner instanceof Tuner(int p)) {} // doesn't compile!
// Attempt 2: record pattern match on double argument
if (tuner instanceof Tuner(double p)) {
int pitch = p; // doesn't compile! needs a cast to int
}
// Attempt 3: record pattern match on double argument, cast to int
if (tuner instanceof Tuner(double p)) {
int pitch = (int) p;
}
To put it differently, the Java compiler widens the provided int to a double, but it doesn't narrow it back to an int. This limitation exists because narrowing could lead to data loss: the value of the double at runtime might exceed the range of an int or have more precision than an int can accommodate. However, one significant advantage of pattern matching is its ability to automatically reject invalid values by not matching them at all. If the double component of a Tuner is either too large or too precise to safely convert back to an int, then instanceof Tuner(int p) would simply return false, allowing the program to manage the large double component in a different code branch.
This is analogous to how pattern matching currently behaves for reference type patterns. For example:
record SingleEffect(Effect effect) {}
var singleEffect = new SingleEffect(...);
if (singleEffect instanceof SingleEffect(Delay d)) {
// ...
} else if (singleEffect instanceof SingleEffect(Reverb r)) {
// ...
} else {
// ...
}
instanceof can be used here to try to match a SingleEffect with a Delay or a Reverb component; it automatically narrows if the pattern matches.
To summarize, this JEP proposes to make primitive type patterns work as smoothly as reference type patterns, allowing Tuner(int p) even if the corresponding record component is a numeric primitive type other than int.
Pattern Matching for instanceof
Pattern matching for instanceof currently doesn't support primitive type patterns, but this capability would perfectly align with the purpose of instanceof: to test whether a value can be converted safely to a given type. To convert primitives safely, Java developers currently have to deal with lossy casts and range checks to prevent loss of information:
int roomSize = reverb.roomSize();
if (roomSize >= -128 && roomSize < 127) {
byte r = (byte) roomSize;
// now it's safe to use r
}
This JEP proposes the possibility to replace these constructs with simple instanceof checks that operate on primitives. Let's rewrite the code example to make use of this feature:
int roomSize = reverb.roomSize();
if (roomSize instanceof byte r) {
// now it's safe to use r
}
The pattern roomSize instanceof byte r will match only if roomSize fits into a byte, eliminating the need for casts and range checks.
Primitive Types in instanceof
The instanceof keyword used to take a reference type only, and since Java 16 it can also take a type pattern.
But it would make sense to have instanceof take a primitive type also.
In that case instanceof would check if the conversion is safe but would not actually perform it:
if (roomSize instanceof byte) { // check if value of roomSize fits in a byte
... (byte) roomSize ... // yes, it fits! but cast is required
}
This JEP proposes to support this construct, which makes it easier to change the instanceof check to take a type pattern and vice versa.
Primitive Types in switch
The switch statement/expression currently supports byte, short, char, and int values.
This JEP proposes to also add support for the other primitive types: boolean, float, double and long.
A switch on a boolean value can be a good alternative for the ternary operator (?:), because its branches can also hold statements instead of just expressions.
String guitaristResponse = switch (guitar.isInTune()) {
case true -> "Ready to play a song.";
case false -> {
log.warn("Guitar is out of tune!");
yield "Let's take five!";
}
}
What's Different From Java 22?
Java 22 didn't support primitive types in patterns, instanceof and switch yet. Note that this JEP is in the preview stage, so you'll need to add the --enable-preview flag to the command-line to take the feature for a spin.
More Information
For more information on this feature, see JEP 455.
JEP 476: Module Import Declarations (Preview)
Many essential classes in the Java Class Library require imports to be usable.
In the following code, for example...
import java.util.Map; // or import java.util.*;
import java.util.function.Function; // or import java.util.function.*;
import java.util.stream.Collectors; // or import java.util.stream.*;
import java.util.stream.Stream; //
String[] instruments = new String[] { "violin", "piano", "marimba" };
Map<String, String> m =
Stream.of(instruments)
.collect(Collectors.toMap(s -> s.toUpperCase().substring(0, 1), Function.identity()));
...the imports take up just as much space as the code itself.
Whether that's a bad thing or not depends on your import type preference.
In large, mature projects single-type imports are preferred by many.
However, in early-stage situations (when trying out a new feature, or when you're in JShell) a more convenient approach could come in handy.
Module Import Declarations
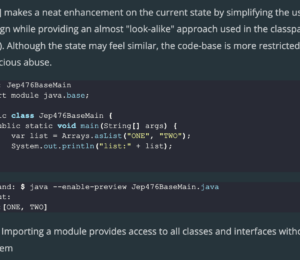
This JEP introduces module import declarations, and they have the form import module M;.
A module import declaration imports all of the public top-level classes and interfaces in the packages exported by the module M to the current module. Any indirect exports by the module M will also be made available by a module import declaration.
For example, if you write import module java.sql, it means your class will be able to read classes and interfaces from the packages java.sql and javax.sql (because they are exported by the module java.sql). On top of that, because java.sql pulls in three other modules transitively, any exported packages from those modules will also be available.
Ambiguous Imports
When you import a module, it brings in several packages, which means you might end up importing classes that have the same simple name from different packages. This creates ambiguity, leading to a compile-time error.
In this source file, the simple name Date is ambiguous:
import module java.base; // exports java.util, which has a public Date class import module java.sql; // exports java.sql, which has a public Date class ... Date d = ... // Error - Ambiguous name! ...
Resolving ambiguities is straightforward: use a single-type-import declaration. For example, to resolve the ambiguous Date of the previous example:
import module java.base; // exports java.util, which has a public Date class import module java.sql; // exports java.sql, which has a public Date class import java.sql.Date; // resolve the ambiguity of the simple name Date ... Date d = ... // Ok! Date is resolved to java.sql.Date ...
What's Different From Java 22?
Up until Java 22, to import all public top-level classes and interfaces from a module, a wildcard-type import was required for each package in the module. In Java 23 the same behaviour can be achieved using a single module import declaration. Note that this JEP is in the preview stage, so you'll need to add the --enable-preview flag to the command-line to take the feature for a spin.
More Information
For more information on this feature, see JEP 476.
JEP 477: Implicitly Declared Classes and Instance Main Methods (Third Preview)
Java's take on the classic Hello, World! program is notoriously verbose:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
On top of that, it forces newcomers to grasp a few concepts that they certainly don't need on their first day of Java programming:
- The
publicaccess modifier and its role in encapsulating units of code, together with its counterpartsprivate,protectedand default; - The
String[] argsparameter, that allows the operating system's shell to pass arguments to the program; - The
staticmodifier and how it's part of Java's class-and-object model; - How to import basic utility classes, to prevent the need for the mysterious
System.out.printlnincantation.
The motivation for this JEP is to help programmers that are new to Java by introducing concepts in the right order, starting with the more fundamental ones. This is done by hiding any unnecessary details until they are useful in larger programs.
Proposed Changes
To achieve this, the JEP proposes the following changes:
- change the launch protocol to allow instance main methods, which are not
staticand don't need apublicmodifier, nor aString[]parameter;
class HelloWorld {
void main() { // this is an instance main method
System.out.println("Hello, World!");
}
}
- allow a compilation unit to implicitly declare a class:
void main() { // this is an instance main method in an implicitly declared class
System.out.println("Hello, World!");
}
- in implicitly declared classes, automatically import useful methods for textual input and output, thereby avoiding the mysterious
System.out.println:
void main() {
println("Hello, World!"); // this method is automatically imported
}
A Flexible Launch Protocol
Java 23 enhances the launch protocol to offer more flexibility in declaring a program's entry point. The main method of a launched class can now have public, protected or default access. Other enhancements of the launch protocol include:
- If the launched class contains a main method with a
String[]parameter, then choose that method. - Otherwise, if the class contains a main method with no parameters, then choose that method.
- In either case, if the chosen method is
static, then simply invoke it. - Otherwise, the chosen method is an instance method and the launched class must have a zero-parameter, non-private constructor. Invoke that constructor and then invoke the
mainmethod of the resulting object. If there is no such constructor, then report an error and terminate. - If there is no suitable
mainmethod, then report an error and terminate.
Implicitly Declared Classes
With the introduction of implicitly declared classes, the Java compiler will consider a method that is not enclosed in a class declaration, as well as any unenclosed fields and any classes declared in the file, to be members of an implicitly declared top-level class.
Such a class always belongs to the unnamed package, is final, and can't implement interfaces or extend classes except Object. You can't reference it by name or use method references for its static methods, but you can use this and make method references to its instance methods. Implicitly declared classes can't be instantiated or referenced by name in code. They're mainly used as program entry points and must have a main method, enforced by the Java compiler.
Interacting with the Console
Many beginner programs need to interact with the console, for example:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
class Main {
public static void main(String... args) {
System.out.println("Please enter your name:");
String name = "";
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
name = reader.readLine();
} catch (IOException ioe) {
ioe.printStackTrace();
}
System.out.println("Hello, " + name);
}
}
The code may seem familiar to experienced developers, but beginners often find it confusing due to new concepts like import, try, catch, BufferedReader, InputStreamReader and IOException. While there are other approaches, none are significantly better for those just starting out.
To make interacting with the console easier for beginners, implicit classes now automatically import all static methods from the newly added class java.io.IO:
public static void println(Object obj);public static void print(Object obj);public static String readln(String prompt);
Combined with the other features from this JEP, the code above can now be simplified to:
void main() {
String name = readln("Please enter your name:");
print("Hello, ");
println(name);
}
Automatic Import of the java.base Module
To make writing small programs even easier, all public top-level classes and interfaces from the java.base module are now automatically available in every implicit class, as if they were imported.
This means that popular APIs from packages like java.io, java.math, and java.util can be used right away, eliminating the need for explicit import statements that might confuse beginners.
This implicit behaviour can also be made explicit to make it work in any other class, by using a module import declaration like
import module java.base, which can be helpful when converting an implicit class to a top-level class.
What's Different From Java 22?
Java 23 contains the following changes compared to Java 22:
- Implicitly declared classes automatically import three static methods for simple textual I/O with the console. These methods are declared in the new top-level class
java.io.IO. - Implicitly declared classes automatically import, on demand, all of the public top-level classes and interfaces of the packages exported by the
java.basemodule.
Note that this JEP is in the preview stage, so you'll need to add the --enable-preview flag to the command-line to take the feature for a spin.
More Information
For more information on this feature, see JEP 477.
JEP 482: Flexible Constructor Bodies (Second Preview)
Suppose we have a superclass Orchestra and a subclass StringQuartet. The constructors of these classes must work together to ensure a valid instance. The StringQuartet constructor is responsible for any StringQuartet-specific fields, while the Orchestra constructor is responsible for fields declared in the Orchestra class. Since code in the StringQuartet constructor might refer to fields initialized by the Orchestra constructor, the latter must run first.
This example illustrates that constructors should run from top to bottom. This also means that a superclass constructor must finish initializing its fields before a subclass constructor starts, ensuring proper object state initialization and preventing access to uninitialized fields. Java enforces this by requiring explicit constructor calls (like super(...) or this(...)) to be the first statement in a constructor body, and constructor arguments cannot access the current object. While these rules ensure that constructors behave predictably, they may restrict the use of common programming patterns in constructor methods. The following code example illustrates this point:
class StringQuartet extends Orchestra {
public StringQuartet(List<Instrument> instruments) {
super(instruments); // Potentially unnecessary work!
if (instruments.size() != 4) {
throw new IllegalArgumentException("Not a quartet!");
}
}
}
It would be better to let the constructor fail fast, by validating its arguments before the super(...) constructor is called.
Pre-Java 22, we could only achieve this by introducing a static method that acts upon the value passed to the super constructor.
public class StringQuartet extends Orchestra {
public StringQuartet(List<Instrument> instruments) {
super(validate(instruments));
}
private static List<Instrument> validate(List<Instrument> instruments) {
if (instruments.size() != 4) {
throw new IllegalArgumentException("Not a quartet!");
}
}
}
But a far more readable way to write the same would be:
public class StringQuartet extends Orchestra {
public StringQuartet(List<Instrument> instruments) {
if (instruments.size() != 4) {
throw new IllegalArgumentException("Not a quartet!");
}
super(instruments);
}
}
This approach will be possible in Java 23, due to the introduction of early construction contexts.
Java used to treat the arguments to an explicit constructor invocation to be in a static context, as if they were in a static method. But this restriction is a bit stronger than necessary, which is why Java 23 introduces the aforementioned early construction contexts; a strictly weaker concept. It covers both the arguments to an explicit constructor invocation and any statements that occur before it. Code in an early construction context must not use the instance under construction, except to initialize fields that do not have their own initializers.
What's Different From Java 22?
- The feature was renamed: in Java 22 it was known as "Statements before super(...)";
- A constructor body is now allowed to initialize fields in the same class before explicitly invoking a constructor. This possibility prevents any superclass constructor from seeing the default value of a subclass field (like
0,falseornull).
Note that this JEP is in the preview stage, so you'll need to add the --enable-preview flag to the command-line to take the feature for a spin.
More Information
For more information on this feature, see JEP 482.
What Happened to String Templates?
Java 22 had a feature called string templates, which was in second preview back then.
However, the feature is not included in Java 23, which might be surprising, but at the same time it's a valid possibility.
We have always known that preview features are impermanent, and might even be removed instead of promoted to 'final' status.
So what happened? Well, in short: the effort did not meet the needs of the developers.
Like any preview feature, feedback was received from the developer community, and quite a few issues were raised.
Some remarks were about syntax, and others were about nested templates.
But the most relevant feedback was about the co-dependence of string templates and template processors.
To make the feature perform better than String.format(...), it was crucial that the template processor would appear close to the string template it had to process, which is why the special syntax PROCESSOR."template" was introduced.
Based on the feedback, on the Project Amber mailing list a discovery was made: the template and the code processing it didn't have to appear side by side to achieve the performance boost. This meant that the special syntax could also potentially be dropped.
This realization ultimately sent the feature back to the drawing board!
While the new direction was taking shape, the Java 23 deadline was fast approaching and the choice was made to drop the feature entirely, instead of repreviewing it unchanged while everyone knew the design would change drastically in the future.
What Happens Next?
So, what happens next? Well, a new JEP will probably appear in the future, but it might take a while, as much of the initial design has to be reconsidered.
But based on the above template processors probably won't have a prominent place.
And string templates will probably become a new kind of literal (similar to String literals), because there's no need for them to be tied to their template processor any more.
There's no way for us to know exactly when a new proposal will be ready, so we'll just have to wait and see.
And in the meantime, if you're interested, this excellent video by Nicolai Parlog has a few more interesting details to keep you occupied.
From Project Loom
Java 23 contains 2 features that originated from Project Loom:
- Structured Concurrency (Third Preview)
- Scoped Values (Third Preview)
Project Loom strives to simplify maintaining concurrent applications in Java by introducing virtual threads and an API for structured concurrency, among other things.
JEP 480: Structured Concurrency (Third Preview)
Java's take on concurrency has always been unstructured, meaning that tasks run independently of each other. There's no hierarchy, scope, or other structure involved, which means errors or cancellation intent is hard to communicate.
To illustrate this, let's look at a code example that takes place in a restaurant:
The code examples that illustrate Structured Concurrency were taken from my conference talk "Java's Concurrency Journey Continues! Exploring Structured Concurrency and Scoped Values".
public class MultiWaiterRestaurant implements Restaurant {
@Override
public MultiCourseMeal announceMenu() throws ExecutionException, InterruptedException {
Waiter grover = new Waiter("Grover");
Waiter zoe = new Waiter("Zoe");
Waiter rosita = new Waiter("Rosita");
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
Future<Course> starter = executor.submit(() -> grover.announceCourse(CourseType.STARTER));
Future<Course> main = executor.submit(() -> zoe.announceCourse(CourseType.MAIN));
Future<Course> dessert = executor.submit(() -> rosita.announceCourse(CourseType.DESSERT));
return new MultiCourseMeal(starter.get(), main.get(), dessert.get());
}
}
}
Note that the announceCourse(..) method in the Waiter class sometimes fails with an OutOfStockException, because one of the ingredients for the course might not be in stock. This can lead to some problems:
- If
zoe.announceCourse(CourseType.MAIN)takes a long time to execute butgrover.announceCourse(CourseType.STARTER)fails in the meantime, theannounceMenu(..)method will unnecessarily wait for the main course announcement by blocking onmain.get(), instead of cancelling it (which would be the sensible thing to do). - If an exception happens in
zoe.announceCourse(CourseType.MAIN),main.get()will throw it, butgrover.announceCourse(CourseType.STARTER)will continue to run in its own thread, resulting in thread leakage. - If the thread executing
announceMenu(..)is interrupted, the interruption will not propagate to the subtasks: all threads that run anannounceCourse(..)invocation will leak, continuing to run even afterannounceMenu()has failed.
Ultimately the problem here is that our program is logically structured with task-subtask relationships, but these relationships exist only in the mind of the developer. We might all prefer structured code that reads like a sequential story, but this example simply doesn't meet that criterion.
In contrast, the execution of single-threaded code always enforces a hierarchy of tasks and subtasks, as shown by the single-threaded version of our restaurant example:
public class SingleWaiterRestaurant implements Restaurant {
@Override
public MultiCourseMeal announceMenu() throws OutOfStockException {
Waiter elmo = new Waiter("Elmo");
Course starter = elmo.announceCourse(CourseType.STARTER);
Course main = elmo.announceCourse(CourseType.MAIN);
Course dessert = elmo.announceCourse(CourseType.DESSERT);
return new MultiCourseMeal(starter, main, dessert);
}
}
Here, we don't have any of the problems we had before.
Our waiter Elmo will announce the courses in exactly the right order, and if one subtask fails the remaining one(s) won't even be started.
And because all work runs in the same thread, there is no risk of thread leakage.
It became apparent from these examples that concurrent programming would be a lot easier and more intuitive if enforcing the hierarchy of tasks and subtasks was possible, just like with single-threaded code.
Introducing Structured Concurrency
In a structured concurrency approach, threads have a clear hierarchy, their own scope, and clear entry and exit points. Structured concurrency arranges threads hierarchically, akin to function calls, forming a tree with parent-child relationships. Execution scopes persist until all child threads complete, matching code structure.
Shutdown on Failure
Let's now take a look at a structured, concurrent version of our example:
public class StructuredConcurrencyRestaurant implements Restaurant {
@Override
public MultiCourseMeal announceMenu() throws ExecutionException, InterruptedException {
Waiter grover = new Waiter("Grover");
Waiter zoe = new Waiter("Zoe");
Waiter rosita = new Waiter("Rosita");
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Supplier<Course> starter = scope.fork(() -> grover.announceCourse(CourseType.STARTER));
Supplier<Course> main = scope.fork(() -> zoe.announceCourse(CourseType.MAIN));
Supplier<Course> dessert = scope.fork(() -> rosita.announceCourse(CourseType.DESSERT));
scope.join(); // 1
scope.throwIfFailed(); // 2
return new MultiCourseMeal(starter.get(), main.get(), dessert.get()); // 3
}
}
}
The scope's purpose is to keep the threads together.
At 1, we wait (join) until all threads are done with their work.
If one of the threads is interrupted, an InterruptedException is thrown here.
At 2, an ExecutionException is thrown if an exception occurs in one of the threads.
Once we reach 3, we can be sure everything has gone well, and we can retrieve and process the results.
Actually, the main difference with the code we had before is the fact that we create threads (fork) within a new scope.
Now we can be certain that the lifetimes of the three threads are confined to this scope, which coincides with the body of the try-with-resources statement.
Furthermore, we've gained short-circuiting behaviour.
When one of the announceCourse(..) subtasks fails, the others are cancelled if they didn't complete yet.
This behaviour is managed by the ShutdownOnFailure policy.
We've also gained cancellation propagation.
When the thread that runs announceMenu() is interrupted before or during the call to scope.join(), all subtasks are cancelled automatically when the thread exits the scope.
Shutdown on Success
A shutdown-on-failure policy cancels tasks if one of them fails, while a shutdown-on-success policy cancels tasks if one succeeds. The latter is useful to prevent unnecessary work once a successful result is obtained.
Let's see what a shutdown-on-success implementation would look like:
public record DrinkOrder(Guest guest, Drink drink) {}
public class StructuredConcurrencyBar implements Bar {
@Override
public DrinkOrder determineDrinkOrder(Guest guest) throws InterruptedException, ExecutionException {
Waiter zoe = new Waiter("Zoe");
Waiter elmo = new Waiter("Elmo");
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<DrinkOrder>()) {
scope.fork(() -> zoe.getDrinkOrder(guest, BEER, WINE, JUICE));
scope.fork(() -> elmo.getDrinkOrder(guest, COFFEE, TEA, COCKTAIL, DISTILLED));
return scope.join().result(); // 1
}
}
}
In this example the waiter is responsible for getting a valid DrinkOrder object based on guest preference and the drinks supply at the bar.
In the method Waiter.getDrinkOrder(Guest guest, DrinkCategory... categories), the waiter starts to list all available drinks in the drink categories that were passed to the method.
Once a guest hears something they like, they respond and the waiter creates a drink order. When this happens, the getDrinkOrder(..) method returns a DrinkOrder object and the scope will shut down.
This means that any unfinished subtasks (such as the one in which Elmo is still listing different kinds of tea) will be cancelled.
The result() method at 1 will either return a valid DrinkOrder object, or throw an ExecutionException if one of the subtasks has failed.
Custom Shutdown Policies
Two shutdown policies are provided out-of-the-box, but it's also possible to create your own by extending the class StructuredTaskScope and its protected handleComplete(..) method.
That will allow you to have full control over when the scope will shut down and what results will be collected.
What's Different From Java 22?
Compared to the preview version of this feature in Java 22, nothing was changed or added. JEP 480 simply exists to gather more feedback from users. Note that this JEP is in the preview stage, so you'll need to add the --enable-preview flag to the command-line to take the feature for a spin.
More Information
For more information on this feature, see JEP 480.
JEP 481: Scoped Values (Third Preview)
Scoped values enable the sharing of immutable data within and across threads.
They are preferred to thread-local variables, especially when using large numbers of virtual threads.
The code examples that illustrate Scoped Values were taken from my conference talk "Java's Concurrency Journey Continues! Exploring Structured Concurrency and Scoped Values".
ThreadLocal
Since Java 1.2 we can make use of ThreadLocal variables, which confine a certain value to the thread that created it. Back then this was a simple way to achieve thread-safety, in some cases.
But thread-local variables also come with a few caveats. Every thread-local variable is mutable, making it hard to discern where shared state is updated and in what order. There's also the risk of memory leaks, because unless you call remove() on the ThreadLocal the data is retained until it is garbage collected (which is only after the thread terminates). And finally, thread-local variables of a parent thread can be inherited by child threads, meaning that the child thread has to allocate storage for every thread-local variable previously written in the parent thread.
These drawbacks become more apparent now that virtual threads have been introduced, because millions of them could be active at the same time - each with their own thread-local variables - resulting in a significant memory footprint.
Scoped Values
Like a thread-local variable, a scoped value has multiple incarnations, one per thread. Unlike a thread-local variable, a scoped value is written once and is then immutable. It's available only for a bounded period during execution of the thread.
To demonstrate this feature, we've added a scoped value to the StructuredConcurrencyBar class that you're already familiar with:
public class StructuredConcurrencyBar implements Bar {
private static final ScopedValue<Integer> drinkOrderId = ScopedValue.newInstance();
@Override
public DrinkOrder determineDrinkOrder(Guest guest) throws Exception {
Waiter zoe = new Waiter("Zoe");
Waiter elmo = new Waiter("Elmo");
return ScopedValue.where(drinkOrderId, 1)
.call(() -> {
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<DrinkOrder>()) {
scope.fork(() -> zoe.getDrinkOrder(guest, BEER, WINE, JUICE));
scope.fork(() -> elmo.getDrinkOrder(guest, COFFEE, TEA, COCKTAIL, DISTILLED));
return scope.join().result();
}
});
}
}
We see that ScopedValue.where(...) is called, presenting a scoped value and the object to which it is to be bound. The invocation of call(...) binds the scoped value, providing an incarnation that is specific to the current thread, and then executes the lambda expression passed as argument. During the lifetime of call(...), the lambda expression - and any method called (in)directly from it - can read the scoped value via the value’s get() method. After the call(...) method finishes, the binding is destroyed.
Typical Use Cases
Scoped values will be useful in all places where currently thread-local variables are used for the purpose of one-way transmission of unchanging data.
What's Different From Java 22?
The method ScopedValue.callWhere(key, value, operation) (which is a shorter way to write ScopedValue.where(key, value).call(operation);) can now throw a checked exception of a generic type. This means that you're now able to catch that exception like this:
try {
var result = ScopedValue.callWhere(X, "hello", () -> bar());
} catch (Exception e) {
handleFailure(e);
}
// ...
Note that this JEP is in the preview stage, so you'll need to add the --enable-preview flag to the command-line to take the feature for a spin.
More Information
For more information on this feature, see JEP 481.
HotSpot
Java 23 introduces a single change to HotSpot:
- ZGC: Generational Mode by Default
The HotSpot JVM is the runtime engine that is developed by Oracle. It translates Java bytecode into machine code for the host operating system's processor architecture.
JEP 474: ZGC: Generational Mode by Default
The Z Garbage Collector (ZGC) is a scalable, low-latency garbage collector. It has been available for production use since Java 15 and has been designed to keep pause times consistent and short, even for very large heaps. It uses techniques like region-based memory management and compaction to achieve this.
Java 21 introduced an extension to ZGC that maintains separate generations for young and old objects, allowing ZGC to collect young objects (which tend to die young) more frequently. This will result in a significant performance gain for applications running with generational ZGC, without sacrificing any of the valuable properties that the Z garbage collector is already known for.
In Java 21, a command-line option was required to enable generational mode. Java 23 makes generational mode the default mode for ZGC, whereas non-generational mode has been deprecated. It will probably be removed in a future Java version.
What's Different From Java 22?
To run your workload with Generational ZGC in Java 22, the following configuration was needed:
$ java -XX:+UseZGC -XX:+ZGenerational ...
In Java 23, this command-line option is no longer needed, it will use generational mode by default:
$ java -XX:+UseZGC ...
When you do still include it, a warning will be issued that the ZGenerational option is deprecated.
To revert back to non-generational ZGC, you would need to run:
$ java -XX:+UseZGC -XX:-ZGenerational ...
And you would get two warnings:
The ZGenerational option is deprecated.Non-generational mode is deprecated.
More Information
For more information on this feature, see JEP 474.
Core Libraries
Java 23 also brings you 4 additions that are part of the core libraries:
- Class-File API (Second Preview)
- Vector API (Eighth Incubator)
- Stream Gatherers (Second Preview)
- Deprecate the Memory-Access Methods in sun.misc.Unsafe for Removal
JEP 466: Class-File API (Second Preview)
Java's ecosystem relies heavily on the ability to parse, generate and transform class files. Frameworks use on-the-fly bytecode transformation to transparently add functionality, for example. These frameworks typically bundle class-file libraries like ASM or Javassist to handle class file processing. However, they suffer from the fact that the six-month release cadence of the JDK causes the class-file format to evolve more quickly than before, meaning they might encounter class files that are newer than the class-file library that they bundle.
To solve this problem, JEP 466 proposes a standard class-file API that can produce class files that will always be up-to-date with the running JDK. This API will evolve together with the class-file format, enabling frameworks to rely solely on this API, rather than on the willingness of third-party developers to update and test their class-file libraries.
Elements, Builders and Transforms
The Class-File API, located in the java.lang.classfile package, consists of three main components:
Elements
: Immutable descriptions of parts of a class file, such as instructions, attributes, fields, methods, or the entire file.
Builders
: Corresponding builders for compound elements, offering specific building methods (e.g., ClassBuilder::withMethod) and serving as consumers of element types.
Transforms
: Functions that take an element and a builder, determining if and how the element is transformed into other elements. This allows for flexible modification of class file elements.
Example and Comparison To ASM
Suppose we wish to generate the following method in a class file:
void fooBar(boolean z, int x) {
if (z)
foo(x);
else
bar(x);
}
With ASM we could generate the method like so:
ClassWriter classWriter = ...; MethodVisitor mv = classWriter.visitMethod(0, "fooBar", "(ZI)V", null, null); mv.visitCode(); mv.visitVarInsn(ILOAD, 1); Label label1 = new Label(); mv.visitJumpInsn(IFEQ, label1); mv.visitVarInsn(ALOAD, 0); mv.visitVarInsn(ILOAD, 2); mv.visitMethodInsn(INVOKEVIRTUAL, "Foo", "foo", "(I)V", false); Label label2 = new Label(); mv.visitJumpInsn(GOTO, label2); mv.visitLabel(label1); mv.visitVarInsn(ALOAD, 0); mv.visitVarInsn(ILOAD, 2); mv.visitMethodInsn(INVOKEVIRTUAL, "Foo", "bar", "(I)V", false); mv.visitLabel(label2); mv.visitInsn(RETURN); mv.visitEnd();
Unlike in ASM, where clients directly create a ClassWriter and then request a MethodVisitor, the Class-File API adopts a different approach. Here, instead of clients initiating a builder through a constructor or factory, they supply a lambda function that takes a builder as its parameter:
ClassBuilder classBuilder = ...;
classBuilder.withMethod("fooBar", MethodTypeDesc.of(CD_void, CD_boolean, CD_int), flags,
methodBuilder -> methodBuilder.withCode(codeBuilder -> {
Label label1 = codeBuilder.newLabel();
Label label2 = codeBuilder.newLabel();
codeBuilder.iload(1)
.ifeq(label1)
.aload(0)
.iload(2)
.invokevirtual(ClassDesc.of("Foo"), "foo", MethodTypeDesc.of(CD_void, CD_int))
.goto_(label2)
.labelBinding(label1)
.aload(0)
.iload(2)
.invokevirtual(ClassDesc.of("Foo"), "bar", MethodTypeDesc.of(CD_void, CD_int))
.labelBinding(label2);
.return_();
});
What's Different From Java 22?
Some refinements were made based on experience and feedback from the first preview stage; these are the most important ones:
- The
CodeBuilderclass has been streamlined. This class has three kinds of factory methods for bytecode instructions: low-level factories, mid-level factories, and high-level builders for basic blocks. Based on feedback, mid-level methods that duplicated low-level methods or were infrequently used were removed, and the remaining mid-level methods were renamed to improve usability. - The
AttributeMapperinstances inAttributeshave been made accessible via static methods instead of static fields, to allow lazy initialization and reduce startup cost. Signature.TypeArghas been remodeled to be an algebraic data type, to ease access to the bound type when theTypeArg's kind is bounded.- Type-aware
ClassReader::readEntryOrNullandConstantPool::entryByIndexmethods have been added, which throwConstantPoolExceptioninstead ofClassCastExceptionif the entry at the index is not of the desired type. This allows class-file processors to indicate that a constant pool entry-type mismatch is a class-file format problem instead of the processor's problem.
Note that the Class-File API is in the preview stage, so you'll need to add the --enable-preview flag to the command-line to take the feature for a spin.
More Information
For more information on this feature, including the minor refinements and more details on transforming class files, see JEP 466.
JEP 469: Vector API (Eighth Incubator)
The Vector API makes it possible to express vector computations that reliably compile at runtime to optimal vector instructions.
This means that these computations will significantly outperform equivalent scalar computations on the supported CPU architectures (x64 and AArch64).
Vector Computations? Help Me Out Here!
A vector computation is a mathematical operation on one or more one-dimensional matrices of an arbitrary length. Think of a vector as an array with a dynamic length. Furthermore, the elements in the vector can be accessed in constant time via indices, just like with an array.
In the past, Java programmers could only program such computations at the assembly-code level. But now that modern CPUs support advanced SIMD features (Single Instruction, Multiple Data), it becomes more important to take advantage of the performance gains that SIMD instructions and multiple lanes operating in parallel can bring. The Vector API brings that possibility closer to the Java programmer.
Code Example
Here is a code example (taken from the JEP) that compares a simple scalar computation over elements of arrays with its equivalent using the Vector API:
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va)
.add(vb.mul(vb))
.neg();
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
From the perspective of the Java developer, this is just another way of expressing scalar computations. It might come across as being more verbose, but on the other hand it can bring spectacular performance gains.
Typical Use Cases
The Vector API provides a way to write complex vector algorithms in Java that perform extremely well, such as vectorized hashCode implementations or specialized array comparisons. Numerous domains can benefit from this, including machine learning, linear algebra, encryption, text processing, finance, and code within the JDK itself.
What's Different From Java 22?
Compared to the seventh incubator version of this feature in Java 22, nothing was changed or added.
The Vector API will keep incubating until necessary features of Project Valhalla become available as preview features.
When that happens, the Vector API will be adapted to use them, and it will be promoted from incubation to preview.
More Information
For more information on this feature, see JEP 469.
JEP 473: Stream Gatherers (Second Preview)
The Stream API has been around since Java 8 and it has definitely made its way into the heart of the typical Java developer. It enables a programming style that is both efficient and expressive. Recall that a stream pipeline consists of three parts: a source of elements, any number of intermediate operations, and a terminal operation. For example:
List<Guitar> guitars = List.of(
new Guitar("Cordoba F7 Paco Flamenco", GuitarStyle.CLASSICAL),
new Guitar("Taylor GS Mini-e Koa", GuitarStyle.WESTERN),
new Guitar("Gibson Les Paul Standard '50s Heritage Cherry Sunburst", GuitarStyle.ELECTRIC),
new Guitar("Fender Stratocaster", GuitarStyle.ELECTRIC));
long numberOfNonClassicalGuitars = guitars.stream() // source of elements
.filter(g -> GuitarStyle.CLASSICAL != g.guitarStyle()) // intermediate operation
.collect(Collectors.counting()); // terminal operation
The Stream API offers a relatively diverse but predetermined range of intermediate and terminal operations, including mapping, filtering, reduction, sorting, and more. Over the years, many new intermediate operations have been suggested for the Stream API. For example, it could be useful to introduce a distinctBy intermediate operation. A distinct operation does exist, trakcing the elements it has already seen by using object equality. But what if we want distinct elements based on something else than object equality?
var singleGuitarPerStyle = guitars.stream()
.distinctBy(Guitar::guitarStyle) // hypothetical
.toList();
Over the years, many new intermediate operations have been suggested for the Stream API.
Most of the suggestions that were made would make sense when considered in isolation, but adding all of them would make the (already large) Stream API more difficult to learn because its operations would be less discoverable. A better alternative would be to introduce the ability to define custom intermediate operations, analogous to how the Stream::collect terminal operation currently is extensible, enabling the output of a pipeline to be summarized in a variety of ways.
So that is why this JEP proposes an API for custom intermediate operations that allows developers to transform finite and infinite streams in their own preferred ways.
Gatherers
Stream::gather(Gatherer) is a new intermediate stream operation that processes stream elements by applying a user-defined gatherer. One could say it is the dual of Stream::collect(Collector), but for intermediate operations. Gatherers transform elements in different ways: one-to-one, one-to-many, many-to-one, or many-to-many. They can track previously seen elements, enable short-circuiting for infinite streams, and support parallel execution. For example, they may start by transforming one input element into one output element but switch to transforming one input element into two output elements based on a certain condition.
A gatherer implements the java.util.stream.Gatherer interface and is defined by four functions that work together:
initializer (optional)
Provides an object that maintains private state while processing stream elements.
integrator
Integrates a new element from the input stream.
combiner (optional)
Evaluates the gatherer in parallel when the input stream is marked as such.
finisher (optional)
Is invoked when there are no more input elements to consume.
When Stream::gather is called, it roughly performs the following steps:
- Create a
Downstreamobject which, when given an element of the gatherer’s output type, passes it to the next stage in the pipeline. - Obtain the gatherer’s private state object by invoking the
get()method of its initializer. - Obtain the gatherer’s integrator by invoking its
integrator()method. - While there are more input elements, invoke the integrator's
integrate(...)method, passing it the state object, the next element, and the downstream object. Terminate if that method returns false. - Obtain the gatherer’s finisher and invoke it with the state and downstream objects.
These steps are generic enough to allow every currently existing intermediate stream operation to be expressed in a custom gatherer. For example, the Stream::map operation turns each T element into a U element, so it is simply a stateless one-to-one gatherer. Likewise, the Stream::filter operation is a stateless one-to-many gatherer. This makes every stream pipeline conceptually equivalent to:
stream
.gather(...)
.gather(...)
.gather(...)
.collect(...);
Built-in gatherers
As part of this JEP a few built-in gatherers are introduced:
fold
: A stateful many-to-one gatherer which constructs an aggregate incrementally and emits that aggregate when no more input elements exist.
mapConcurrent
: A stateful one-to-one gatherer which invokes a supplied function for each input element concurrently, up to a supplied limit.
scan
: A stateful one-to-one gatherer which applies a supplied function to the current state and the current element to produce the next element, which it passes downstream.
windowFixed
: A stateful many-to-many gatherer which groups input elements into lists of a supplied size, emitting the windows downstream when they are full.
windowSliding
: A stateful many-to-many gatherer which groups input elements into lists of a supplied size. After the first window, each subsequent window is created from a copy of its predecessor by dropping the first element and appending the next element from the input stream.
Example of a Custom Gatherer
Let's look at a custom gatherer that implements the distinctBy operation we referred to earlier.
This example is based on Karl Heinz Marbaise's excellent blog post on stream gatherers - do check it out if you wish to know more!
static <T, A> Gatherer<T, ?, T> distinctBy(Function<? super T, ? extends A> classifier) {
Supplier<Map<A, List<T>>> initializer = HashMap::new;
Gatherer.Integrator<Map<A, List<T>>, T, T> integrator = (state, element, _) -> {
state.computeIfAbsent(classifier.apply(element), _ -> new ArrayList<>()).add(element);
return true; // true, because more elements need to be consumed
};
BiConsumer<Map<A, List<T>>, Gatherer.Downstream<? super T>> finisher = (state, downstream) -> {
state.forEach((_, value) -> downstream.push(value.getLast()));
};
return Gatherer.ofSequential(initializer, integrator, finisher);
}
...and this is how you could use it:
guitars.stream()
.gather(distinctBy(Guitar::guitarStyle))
.forEach(System.out::println);
...which would yield the following output:
Guitar[name=Taylor GS Mini-e Koa, guitarStyle=WESTERN] Guitar[name=Fender Stratocaster, guitarStyle=ELECTRIC] Guitar[name=Cordoba F7 Paco Flamenco, guitarStyle=CLASSICAL]
No New Intermediate Operations
In conclusion the JEP also states that no new intermediate operations will be added to the Stream class to represent the newly-added built-in gatherers. This is because the language designers want the Stream API to remain concise and easy to learn. The JEP does suggest that adding new intermediate operations in a later round of preview could be an option, once they have proven that they are broadly useful.
What's Different From Java 22?
Compared to the preview version of this feature in Java 22, nothing was changed or added. JEP 473 simply exists to gather more feedback from users. Note that this JEP is in the preview stage, so you'll need to add the --enable-preview flag to the command-line to take the feature for a spin.
More Information
For more information on this feature, see JEP 473.
JEP 471: Deprecate the Memory-Access Methods in sun.misc.Unsafe for Removal
The sun.misc.Unsafe class contains 87 methods to perform low-level operations, such as accessing off-heap memory.
The class is aptly named: using its methods without performing the necessary safety checks can lead to undefined behaviour and to the JVM crashing.
They were meant exclusively for use within the JDK, but back in 2002 when the class was introduced the module system wasn't around yet and so there was no way to prevent the class from being used outside the JDK.
And so the memory-access methods in sun.misc.Unsafe became a valuable tool for library developers seeking greater power and performance than what standard APIs could provide.
Two standard APIs have emerged in recent years that are far better alternatives to these problematic methods:
java.lang.invoke.VarHandle, to manipulate on-heap memory safely and efficiently;java.lang.foreign.MemorySegment, to access off-heap memory safely and efficiently.
Now that these APIs are available, the time has come to deprecate and eventually remove the memory-access methods in sun.misc.Unsafe.
What's Different From Java 22?
All uses of memory-access methods in sun.misc.Unsafe will generate compile-time deprecation warnings in JDK 23. In a future release of Java, warnings at run time will be issued, and at an even later stage exceptions will be thrown. Finally, the methods will be removed entirely. According to the JEP text the process won't be completed until the release of JDK 26, giving developers ample time to adjust to the new situation.
More Information
For more information on this feature, see JEP 471. It has more details on the targeted methods, their alternatives from VarHandle and MemorySegment and how to configure the deprecation warnings with the new command-line option --sun-misc-unsafe-memory-access (to promote the warnings to UnsupportedOperationExceptions already, for example). It also provides a few migration examples.
Tools
Java 23 contains a single feature that is part of the JavaDoc tool:
- Markdown Documentation Comments
JEP 467: Markdown Documentation Comments
The JavaDoc documentation standard has been part of Java since its inception in 1995.
Back then, HTML was the obvious choice when JavaDoc needed a way to support basic markup.
Nowadays HTML is far less likely to be manually produced by humans, but rather generated from some other markup language that is more suitable for humans.
Coupled with the fact that inline JavaDoc tags (like {@link} and {@code}) are not that familiar to developers, it makes perfect sense that Java's documentation tool will start supporting Markdown!
Markdown documentation comments use the /// prefix instead of the familiar /** one. This is due to two reasons:
- Block comments that begin with
/*cannot contain the*/character sequence. This makes it currently very difficult to include code examples that contain embedded/* ... */comments. In//comments there's no such restriction. - A traditional documentation comment (starting with
/**) doesn't require the leading whitespace and the asterisk character on each line. In these cases, Markdown constructs that uses asterisks (like emphasis or list items) would clash with the traditional documentation comment syntax.
Example of the Differences
To illustrate how documentation comments can change now that Markdown is supported, here's an example diff screenshot from the JEP:

Syntax
Markdown documentation comments are written in the CommonMark variant of Markdown. Simple tables are supported, using the syntax of GitHub Flavored Markdown. For example:
/// | Make | Model | /// |----------|------------| /// | Fender | Telecaster | /// | Gibson | Les Paul | /// | Epiphone | Casino |
You can create a link to an element declared elsewhere in your API, by simply enclosing a reference to the element in square brackets.
For example, to link to java.util.List, you can write [java.util.List], or just [List].
The link is equivalent to using the standard JavaDoc {@link ...} tag.
You can link to any kind of program element:
/// - a module [com.hannotify.guitarstore/] /// - a package [com.hannotify.guitarstore.products] /// - a class [Guitar] /// - a field [Guitar#name] /// - a method [Guitar#isInTune()]
To create a link with alternative text, you can use the form [text][element]. For example:
/// Please feel free to use our [utility guitar tuning method][Guitar#isInTune()]!
What's Different From Java 22?
In Java 22, it wasn't yet possible to include Markdown in documentation comments. This possibility has been added in Java 23.
More Information
For more information on this feature, see JEP 467.
Final thoughts
This release of Java didn't have as many new features as previous versions, but there's still more than enough going on in our favourite language. Project Amber is still going strong, making Java more expressive and elegant. String templates might be missing from this release, but its omission shows that the preview process is working as intended. We can look forward to getting a redesigned version in the future. Also, Java is becoming friendlier towards newcomers now that beginner programs can be shorter than before. And that's not all that's new: many other updates were included in this release, including thousands of performance, stability and security updates. So what are you waiting for? Time to take this brand-new Java version for a test drive!
- September 17, 2024
- 28 min read
Hanno Embregts is a Java Developer with a passion for learning, teaching and making music. In his day-to-day job as a Teacher / Technology Advocate at Info Support, Hanno prefers work that is fast-paced and versatile. This is why he juggles Java development, software architecture, public speaking, leading Info Support’s Speaker Community and teaching courses at Info Support’s Knowledge Centre. Hanno is a Java Champion, an Oracle ACE Pro and one of the leaders of the NLJUG (the Dutch Java User Group). Outside of work Hanno likes making music with his friends. He plays the flute, the guitar and he likes to sing. Software conferences are Hanno’s favourite thing in the world, because they allow him to do the three things he loves most at the same time: learning new things, teaching others about stuff he discovered and yes: even making music from time to time!










Comments (2)
Chris Newland
2 years agoAwesome and comprehensive write-up Hanno! Thanks!
Java Weekly, Issue 560 | Baeldung
2 years ago[…] >> Java 23 Has Arrived, And It Brings a Truckload of Changes[foojay.io] […]