


Creating a GraphQL API for Neo4j with Quarkus and SmallRye GraphQL
- August 08, 2022
- 9 min read
In my first article on Foojay, I would like to present one of many possible approaches to create a GraphQL API. I work at Neo4j, so it should not be a big suprise that I will use the Graph database with the same name as a backend for the application.
In this post I will cover a couple of things and I’ll start with a simple use case. Conceptually we will look at the "Schema-First" vs "Object-First" discussions and why - at least in my opinion - GraphQL can be seen much more like an object mapping concept than a query language itself. You will learn that while Neo4j is a Graph database, it does not have a built-in GraphQL layer. It does however a great query language called "Cypher".
Technically we will pick Quarkus, it’s official Neo4j-Extension and the Cypher-DSL. We will translate the incoming GraphQL requests back from the model to Cypher. For defining the model, Quarkus provides SmallRye GraphQL.
What I don’t want to cover is a discussion about REST or GraphQL, exposing a database schema more or less directly or not. Every technology requires some diligence before being put to use. Some approaches fits your use case better than others, that’s just normal.
In general, my litmus test usually goes into the direction of whether I can follow along with a framework or architecture to achieve my purpose or do I need to work against it. In the latter case, it’s often better to pick something that works better, even if it is only in a personal perception of things.
The use case
A while back I started a README in this repository containing a bunch of CS/IT books I liked. It grew to kinda append only database (all.csv) in which I kep track of books I buy and read so that I don’t end up with duplicates. A book has a title, one or more authors, a state and a type.
I wanted to have a simple, searchable API and the result is online here.
"Schema-First" vs "Object-First"
Any GraphQL API requires a schema. If you look at the official web page you’ll see three steps:
- Describe your data
- Ask for what you want
- Get predictable results
"Schema-First" vs "Object-First" is the question that arises in the first step, a book as described in the use case can be represented either as shown in the following GraphQL listing:
type Book {
id: ID
state: State
title: String
authors: [Person]
}
or - when using an appropriate tool - as the following Java record:
public record Book(
Long id,
String title,
State state,
List<Person> authors
) {}
On the first look, there’s hardly a difference. I personally prefer the Java version as I am familiar in that ecosystem and can find my way around - even without the amazing IDE support we have these days.
Things get a bit more interesting when defining queries:
type Query {
books(authorFilter: String, titleFilter: String, unreadOnly: Boolean = false): [Book]
}
This has not per-se a direction pendant in the model world.
In GraphQL, the same types are used for querying as for the model. Hence, I think GraphQL is more a modelling language than a query language.
A graph-database and it’s issues with GraphQL
Neo4j is a graph database. It stores related objects as an actual graph, in which relationships between objects are first-class entities. They can have properties the same way as other entities but especially, they can be traversed very efficiently. "Graph database" and "GraphQL" have both a whole word in common, so why does a Graph database not come with GraphQL built in?
I personally don’t know about historical reasons, I can only guess. And I would guess based on the same reasoning as above: GraphQL requires a somewhat static model respectively it represents a static model. Neo4j however does not have a static model or a data dictionary so to speak. You can look up a distinct set of labels or relationship types, but each node - even with the same label - can have different properties. That makes it hard to derive a proper model from the database content to describe a static GraphQL interface.
The querying model however fits GraphQL nicely. A book, including it’s authors, can be described in Cypher like this:
MATCH (b:Book {title: 'Sleeping Beauties'})<-[w:WROTE]-(a)
RETURN b, w, a
or created like this:
MERGE (k1:Person {name: 'Stephen King'})
MERGE (k2:Person {name: 'Owen King'})
MERGE (b:Book {title: 'Sleeping Beauties'})
MERGE (k1) -[:WROTE] ->(b)
MERGE (k2) -[:WROTE] ->(b)
RETURN *
In case you are interested, Neo4j offers an official solution rooted in the JavaScript ecosystem, called ` @neo4j/graphql` and documented here, OGM included. There’s also neo4j-graphql-java, which does the translation from GraphQL models to Cypher on the JVM. Both these tools are "schema first" approaches, hence, I don’t want to use either. Those are great tools, but they wouldn’t fit my personal interest, so - as said in the beginning - I would rather use something else than working against a solution.
Quarkus
I chose Quarkus for a couple of reasons for this project:
- The presence of an Object-First based approach for GraphQL
- I am the maintainer of the Neo4j extension, and I want to test it from my perspective
- Development speed and turn-around times plus general positive developer experience
- Deployed as GraalVM native binary it’s an excellent fit to run on Heroku
You would want to go to code.quarkus.io or use the Maven archetypes or the IDE integration to get started. Select SmallRye GraphQL extension and the Neo4j client (under "Other"):
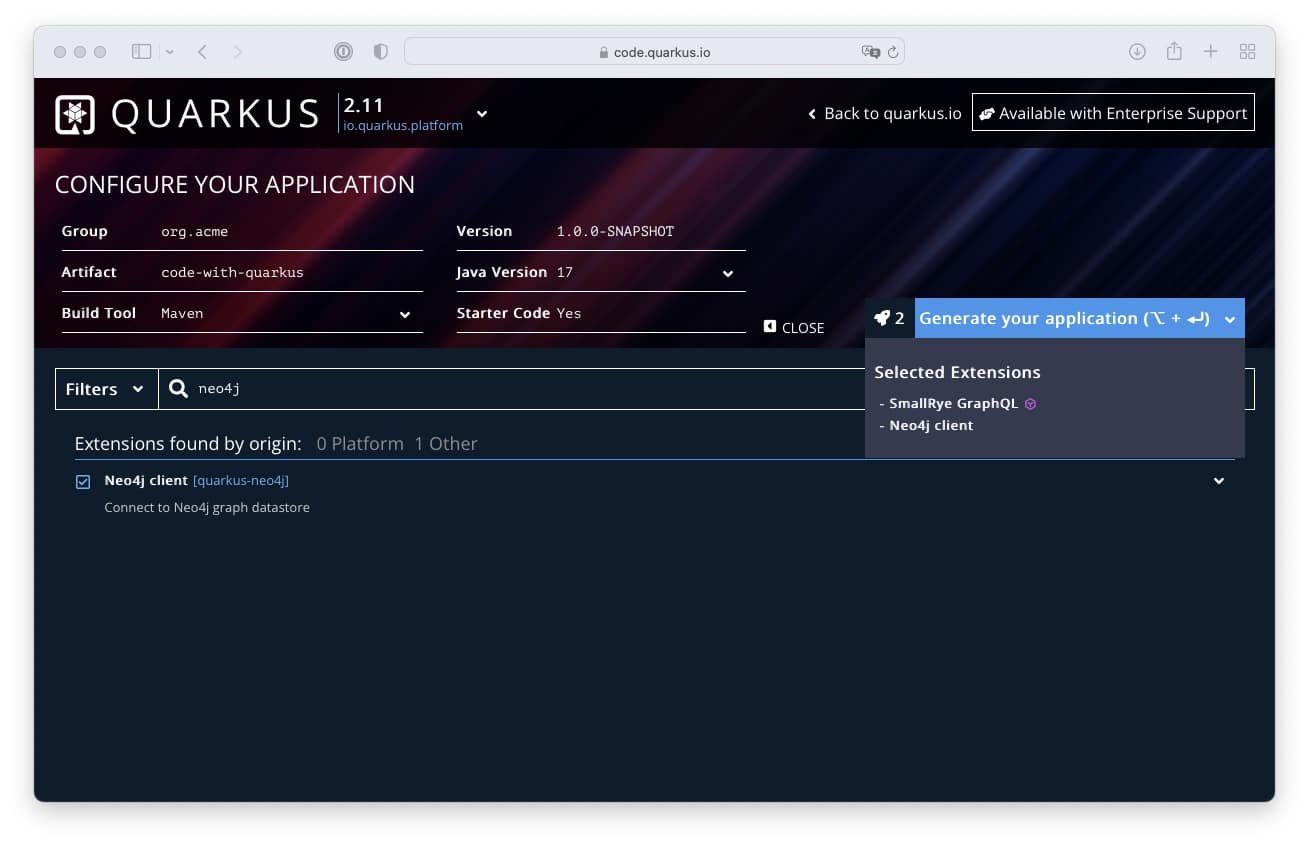
Eventually, your dependencies should look like this, test-dependencies omitted. You’ll find in there the dependencies to Cypher-DSL and another project, Neo4j-Migrations: Think Flyway, but for Neo4j.
<dependencies>
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j-cypher-dsl</artifactId>
<version>2022.6.1</version>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jackson</artifactId>
</dependency>
<dependency>
<groupId>io.quarkiverse.neo4j</groupId>
<artifactId>quarkus-neo4j</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-quarkus</artifactId>
<version>1.9.0</version>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-smallrye-graphql</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-arc</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-container-image-docker</artifactId>
</dependency>
</dependencies>
I have some static configuration in the project, looking like this:
# Always enables the UI for GraphQL
quarkus.smallrye-graphql.ui.always-include=true
# Allows filtering on query complexity later on
quarkus.smallrye-graphql.events.enabled=true
# Tunes Neo4j connection pool for startup performance
quarkus.neo4j.pool.max-connection-lifetime=8m
quarkus.neo4j.pool.max-connection-pool-size=10
# Either use port from the environment or 8080 if unset
quarkus.http.port=${PORT:8080}
# Populate database during dev and test
%dev.org.neo4j.migrations.locations-to-scan=classpath:neo4j/migrations,classpath:neo4j/example-data
%test.org.neo4j.migrations.locations-to-scan=classpath:neo4j/migrations,classpath:neo4j/example-data
Before we highlight some things in the project, let’s have a look what is included with those dependencies and the bit of configuration. With Git, JDK 17 and a working Docker environment on your machine, you can execute the following commands:
# Should print something like java version "17.0.2" 2022-01-18 LTS java -version # Clone the project git clone [email protected]:michael-simons/neo4j-aura-quarkus-graphql.git cd neo4j-aura-quarkus-graphql # Start Quarkus in development mode ./mvnw compile quarkus:dev
In case you never developed with Quarkus before, Maven will download a chunk of the internet for you and after a while, starting up a Neo4j instance in a Docker container, setup the connection, populate the database for you and greet you like this:
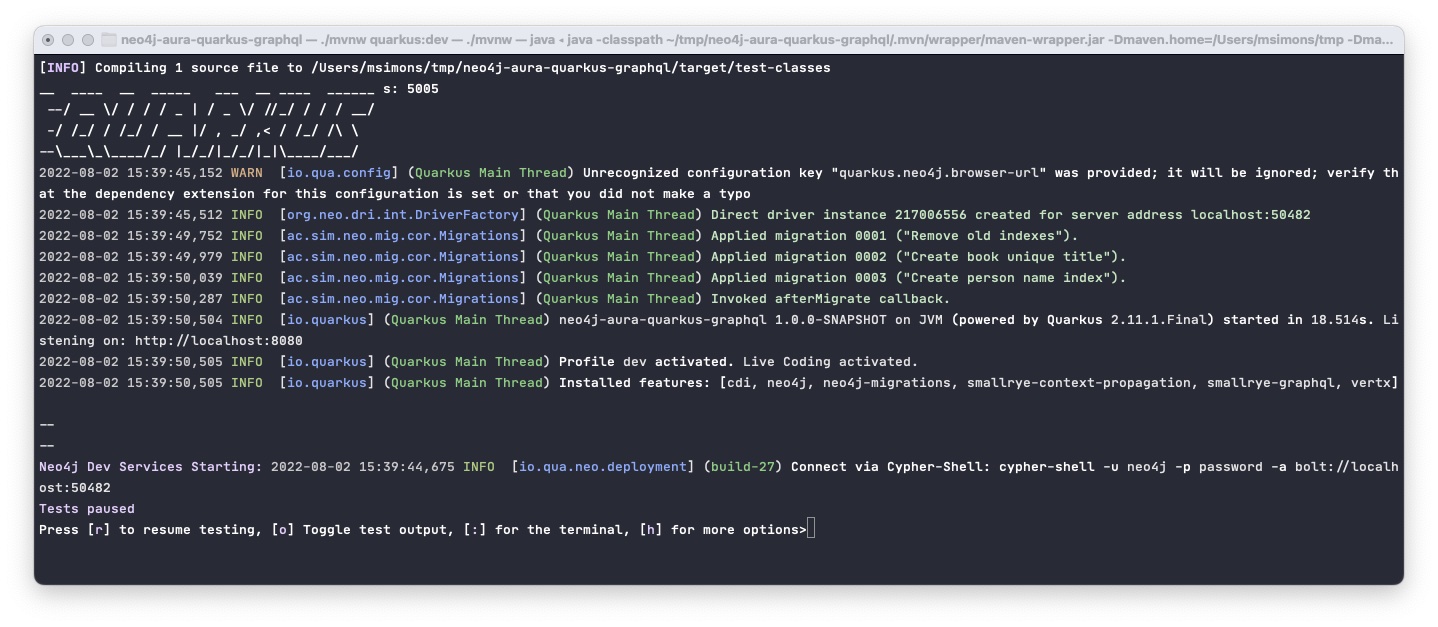
The compile phase in the above command is necessary to trigger the front-end Maven plugin that is configured. It will provide a Vue.js based UI for the application. In the shell above you can now hit [w] to open up a browser targeting at the root url: localhost:8080 looking like this:
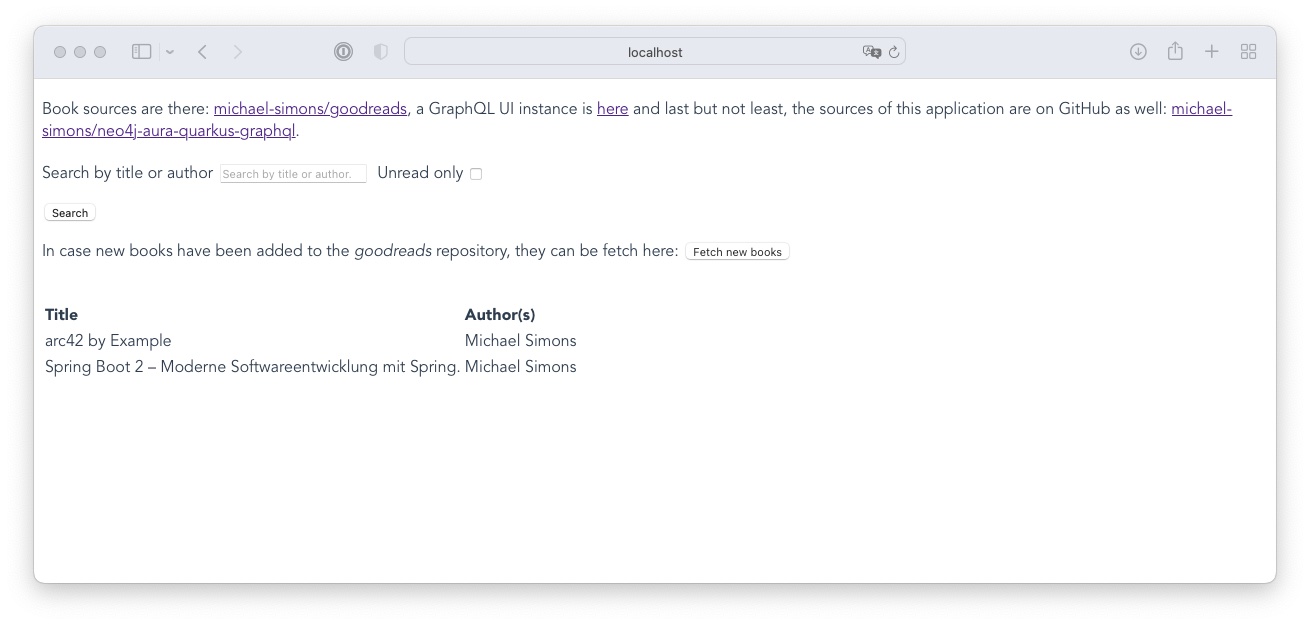
Hitting [d] however is much more interesting. It will open up the Quarkus developer UI at localhost:8080/q/dev/:
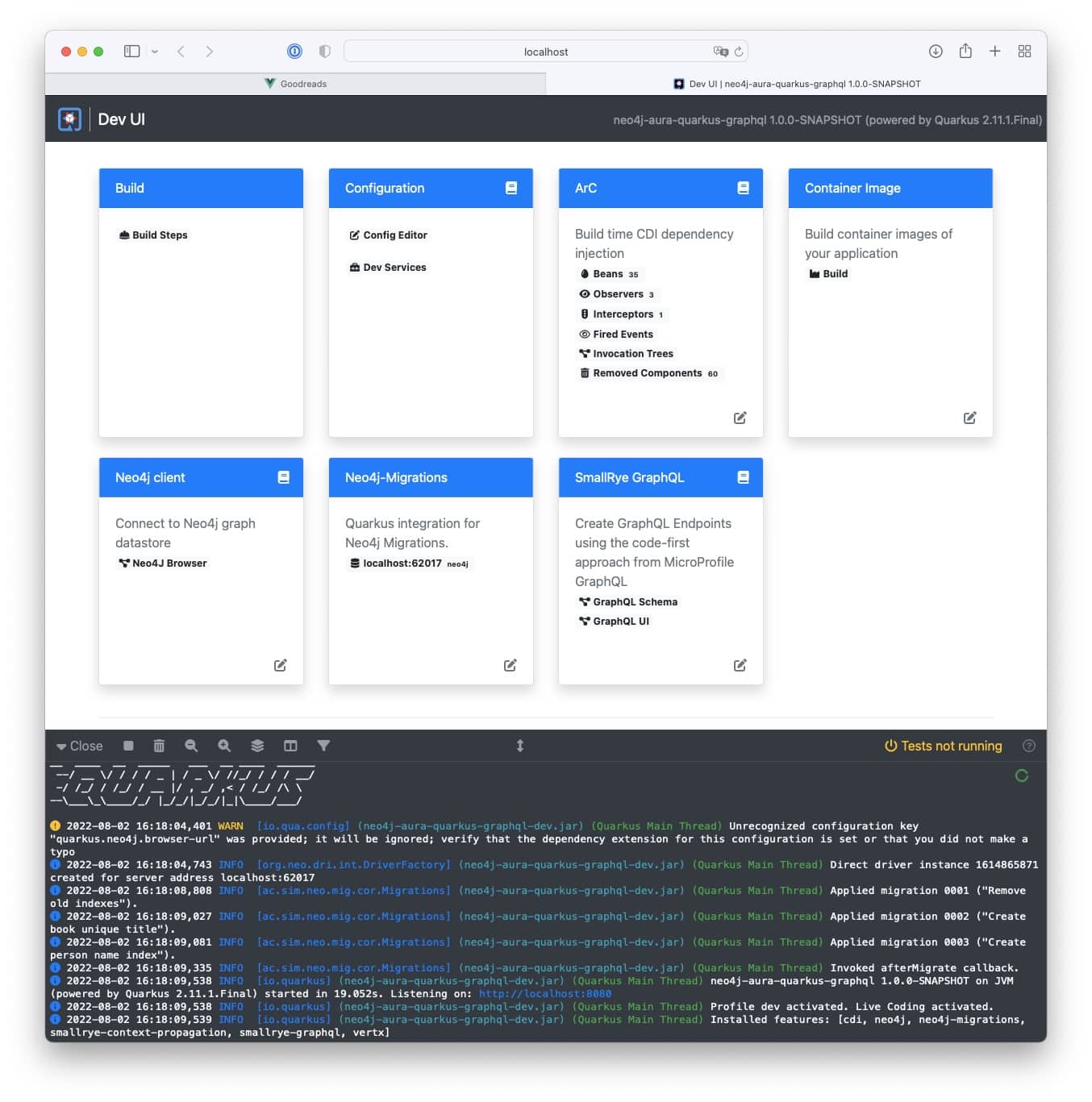
From there you can for example have a look at which migrations have been applied:
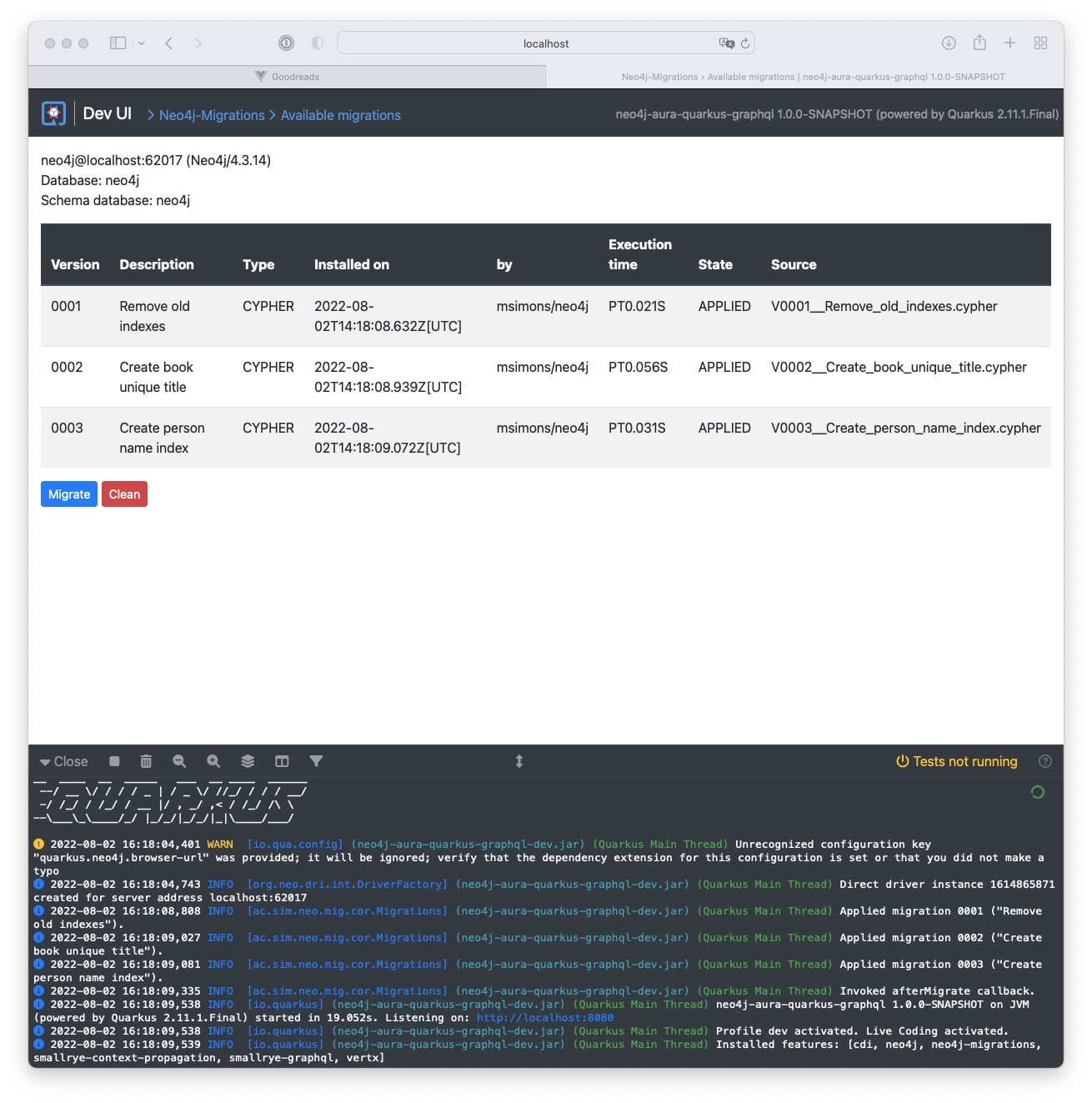
or call the GraphQL UI:
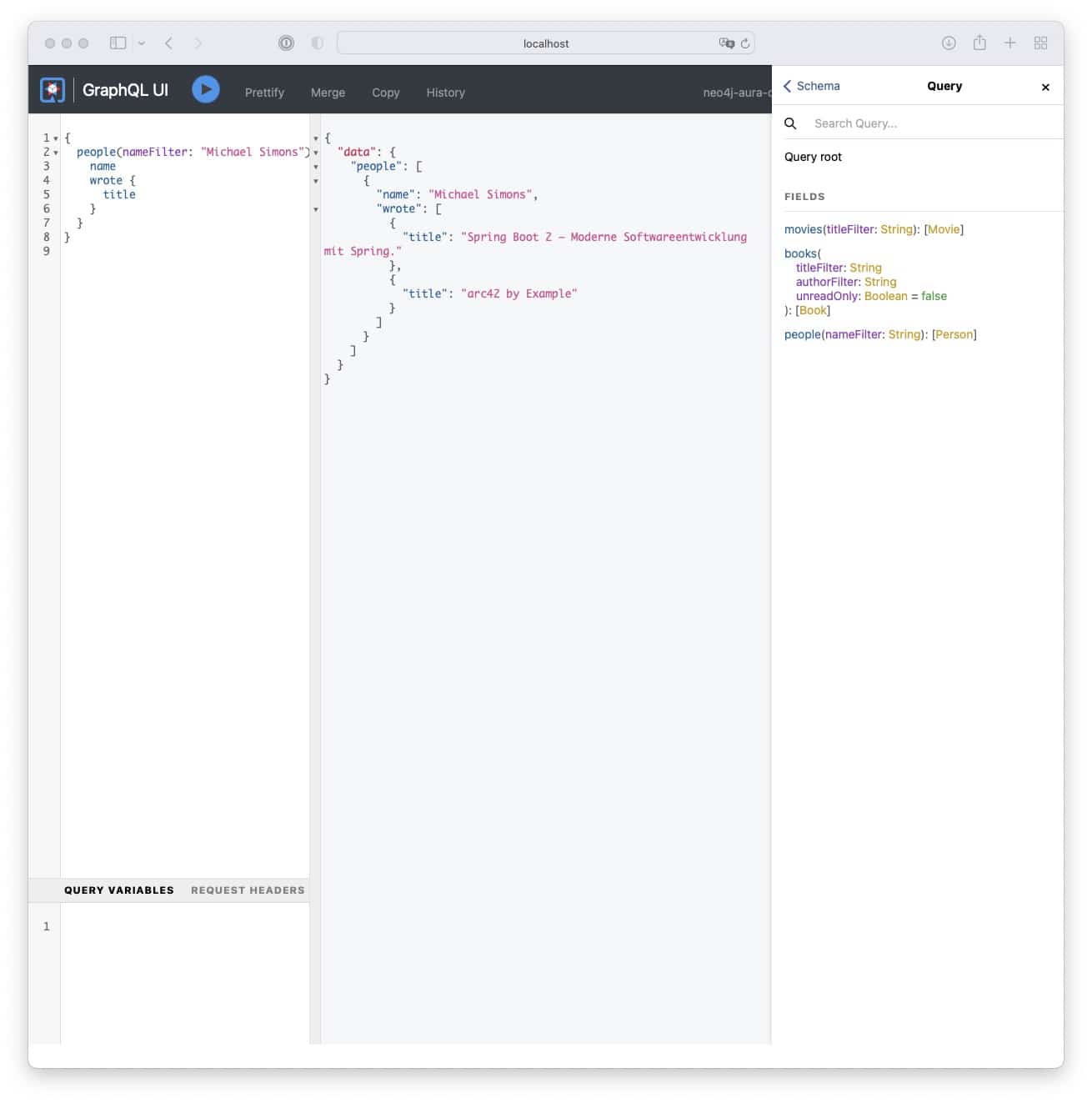
Which is exactly what we want. For the rest of this post I’m gonna walk through the most important pieces of implementation. I am not going touch the actual frontend, I leave that task up to someone with more Vue knowledge than I have. Regarding frontend-maven-plugin: Many things that Jonas Hecht describes in his post at Codecentric applies to a Quarkus backend too.
Implementation
The whole API my application offers is in a class called BooksAndMovies. From a domain perspective, I always wanted to add more content of Neo4j’s movie graph but haven’t done yet. That class is declared as application scoped GraphQLApi:
import graphql.schema.DataFetchingEnvironment;
import io.smallrye.graphql.api.Context;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import org.eclipse.microprofile.graphql.DefaultValue;
import org.eclipse.microprofile.graphql.GraphQLApi;
import org.eclipse.microprofile.graphql.Name;
import org.eclipse.microprofile.graphql.Query;
import org.neo4j.tips.quarkus.books.Book;
import org.neo4j.tips.quarkus.books.BookService;
import org.neo4j.tips.quarkus.people.Person;
@GraphQLApi
@ApplicationScoped
public class BooksAndMovies {
private final Context context;
private final BookService bookService;
@Inject
public BooksAndMovies(Context context, BookService bookService) {
this.context = context;
this.bookService = bookService;
}
@Query("books")
public CompletableFuture<List<Book>> getBooks(
@Name("titleFilter") String titleFilter,
@Name("authorFilter") String authorFilter,
@Name("unreadOnly") @DefaultValue("false") boolean unreadOnly
) {
var env = context.unwrap(DataFetchingEnvironment.class);
return bookService.findBooks(
titleFilter,
Person.withName(authorFilter),
unreadOnly, env.getSelectionSet()
);
}
}
Every method on that class annotated with @Query will be a query in the GraphQL schema. There is a similar annotation for mutations. As you see the method returns a CompletableFuture<>, making it asynchronous. This is important under several aspects: On the API side of things it won’t block a thread and it allows for an easy combination of methods, domain objects and fields.
But first, back to the getBooks method: It takes in a couple of filters and uses the GraphQL context to unwrap a so-called data fetching environment from which we retrieve what fields are of a book are actually request. This way, we don’t over fetch.
The service method BookService#findBooks now uses the Neo4j database connectivity and the Cypher-DSL. The Cypher-DSL is used to build an optimized query that will be eventually executed against the connection:
public CompletableFuture<List<Book>> findBooks(
String titleFilter,
Person authorFilter,
boolean unreadOnly,
DataFetchingFieldSelectionSet selectionSet
) {
var book = node("Book").named("b");
var possibleAuthor = node("Person").named("p");
var author = node("Person").named("a");
var conditions = createDefaultBookCondition(book, unreadOnly);
var additionalConditions = createAdditionalConditions(book,
possibleAuthor, titleFilter, authorFilter);
PatternElement patternToMatch = book;
if (additionalConditions != Conditions.noCondition()) {
patternToMatch = possibleAuthor.relationshipTo(book, "WROTE");
additionalConditions = additionalConditions
.and(author.isEqualTo(possibleAuthor));
}
var match = match(patternToMatch);
var returnedExpressions = new ArrayList<Expression>();
returnedExpressions.add(Functions.id(book).as("id"));
if (selectionSet.contains("authors") || authorFilter != null) {
match = match.match(book.relationshipFrom(author, "WROTE"));
returnedExpressions.add(collect(author).as("authors"));
}
Predicate<String> isRequiredField = (String n) -> "authors".equals(n) || "id".equals(n);
selectionSet.getImmediateFields().stream().map(SelectedField::getName)
.distinct()
.filter(isRequiredField.negate())
.map(n -> book.property(n).as(n))
.forEach(returnedExpressions::add);
var statement = makeExecutable(
match.where(conditions).and(additionalConditions)
.returning(returnedExpressions.toArray(Expression[]::new))
.build()
);
return executeReadStatement(statement, Book::of);
}
There are two scenarios in which we must traverse the WROTE relationship: In case of filtering on the authors name and when the author is in the selection set. A builder like the Cypher-DSL makes this possible in a type safe fashion. Fun fact: If you don’t insist on doing this manually like me here, the neo4j-graphql-java implementation uses the Cypher-DSL under the hood for the exact same purpose.
The generated query will look very similar to what I have shown earlier in matching a book.
Eventually, the asynchronous session of the Neo4j-Java driver is used to execute the query. You’ll find all the helper methods in the project on GitHub.
Having a look at the definition of a Person, you’ll find this:
public record Person(
String name,
Integer born,
List<Movie> actedIn,
List<Book> wrote
) {}
The GraphQL schema however has this:
type Person {
actedIn: [Movie]
born: Int
name: ID
"A short biographie of the person, maybe empty if there is none to be found."
shortBio: String
wrote: [Book]
}
Where does that shortBio come from? It is another asynchronous method on the BooksAndMovies class:
@Description("A short biographie of the person, maybe empty if there is none to be found.")
public CompletionStage<String> shortBio(@Source Person person) {
return peopleService.getShortBio(person);
}
It takes in a source argument - the person - and asynchronously gets their biography and adds it to the result. It won’t work with the example data yet, since I don’t have a Wikipedia entry and that’s where the PeopleService is looking at right now. I am not recommending doing such things without proper circuit breaker in production, but it is rather simple to build a federated GraphQL API based on the given stack.
Deployment
We have seen how to run the project in developer mode in which the dev services will use the amazing Testcontainers to spin up a database for you. In production however, I want to have something different and opted for Neo4j AuraDB. You can sign up there for an always free account.
The application itself is hosted on Heroku deployed by following the official guide: https://quarkus.io/guides/deploying-to-heroku. However, I don’t deploy the default container but a container with a native image, build with GraalVM:
./mvnw clean package\ -Pnative\ -Dquarkus.native.container-build=true\ -Dquarkus.native.builder-image=quay.io/quarkus/ubi-quarkus-native-image:22.2-java17\ -Dquarkus.docker.dockerfile-native-path=./src/main/docker/Dockerfile.native-distroless\ -Dquarkus.container-image.build=true\ -Dquarkus.container-image.group=registry.heroku.com/neo4j-aura-quarkus-graphql\ -Dquarkus.container-image.name=web\ -Dquarkus.container-image.tag=latest
By using a container build, I can delegate the compute intensive task to another machine and also don’t need to have all the Graal tooling installed.
Feel free to fork my repository from https://github.com/michael-simons/neo4j-aura-quarkus-graphql and play around with the code. I’ll happily answer your question on Github or Twitter and until then, happy hacking.
- August 08, 2022
- 9 min read
👨👩👦👦👨🏻💻🚴🏻 – Father, Husband, Programmer, Cyclist. Author of @springbootbuch, founder of @euregjug. Java champion working on @springdata and a bunch of other things at @neo4j.










Comments (1)
This Week in Neo4j: GraphQL, Low Code, Cybersecurity, Graph Refactoring, and More
4 years ago[…] API: Native GraphQL API With Neo4j AuraDB on Heroku […]