


It’s Java 20 Release Day! Here’s What’s New
- March 21, 2023
- 15 min read
This will be a good day, because it's Java 20 release day!
It's been six months since Java 19 was released, and so it's time for another fresh wave of Java features.
In this article, we will take you on a tour through all JEPs that come with this release and give you a brief introduction of each one of them.
Where applicable the differences with Java 19 are highlighted and a few typical use cases are provided, so that you'll be more than ready to use these features after you've finished reading!
Note: See the whole list of everything included in Java 20 here on Foojay.io and you can vote on those that you find most useful or interesting and also check out the Java 20 Foojay Podcast!
From Project Amber
Java 20 contains two features that originated from Project Amber:
- Pattern Matching for switch;
- Record Patterns.
The goal of Project Amber is to explore and incubate smaller, productivity-oriented Java language features.
JEP 433: Pattern Matching for switch (Fourth Preview)
The feature 'Pattern Matching for switch' that was first introduced in Java 17 has reached its fourth preview stage, now that Java 20 has been released. The feature has always gathered a lot of feedback in the past, and on top of that it needs alignment with the related Record Patterns preview feature. In the end there are plenty of reasons to keep it in preview just a little longer.
Since Java 16 we are able to avoid casting after instanceof checks by using 'Pattern Matching for instanceof'. Let's see how that works in a code example.
Code examples that illustrate this JEP were taken from my conference talk "Pattern Matching: Small Enhancement or Major Feature?".
static String apply(Effect effect) {
String formatted = "";
if (effect instanceof Delay de) {
formatted = String.format("Delay active of %d ms.", de.timeInMs());
} else if (effect instanceof Reverb re) {
formatted = String.format("Reverb active of type %s and roomSize %d.", re.name(), re.roomSize());
} else if (effect instanceof Overdrive ov) {
formatted = String.format("Overdrive active with gain %d.", ov.gain());
} else if (effect instanceof Tremolo tr) {
formatted = String.format("Tremolo active with depth %d and rate %d.", tr.depth(), tr.rate());
} else if (effect instanceof Tuner tu) {
formatted = String.format("Tuner active with pitch %d. Muting all signal!", tu.pitchInHz());
} else {
formatted = String.format("Unknown effect active: %s.", effect);
}
return formatted;
}
This code is still riddled with ceremony, though. On top of that it leaves room for subtle bugs — what if you added an else-if branch that didn't assign anything to formatted? So in the spirit of this JEP (and its predecessors), let's see what pattern matching in a switch statement (or even better: in a switch expression) would look like:
static String apply(Effect effect) {
return switch(effect) {
case Delay de -> String.format("Delay active of %d ms.", de.timeInMs());
case Reverb re -> String.format("Reverb active of type %s and roomSize %d.", re.name(), re.roomSize());
case Overdrive ov -> String.format("Overdrive active with gain %d.", ov.gain());
case Tremolo tr -> String.format("Tremolo active with depth %d and rate %d.", tr.depth(), tr.rate());
case Tuner tu -> String.format("Tuner active with pitch %d. Muting all signal!", tu.pitchInHz());
case null, default -> String.format("Unknown or empty effect active: %s.", effect);
};
}
Pattern matching for switch made our code far more elegant here. We're even able to address possible nulls by defining a specific case for them or combining it with the default case (which is what we've done here).
Checking an additional condition on top of the pattern match is easily done with a guard (the part after the when keyword in the code below):
static String apply(Effect effect, Guitar guitar) {
return switch(effect) {
case Delay de -> String.format("Delay active of %d ms.", de.timeInMs());
case Reverb re -> String.format("Reverb active of type %s and roomSize %d.", re.name(), re.roomSize());
case Overdrive ov -> String.format("Overdrive active with gain %d.", ov.gain());
case Tremolo tr -> String.format("Tremolo active with depth %d and rate %d.", tr.depth(), tr.rate());
case Tuner tu when !guitar.isInTune() -> String.format("Tuner active with pitch %d. Muting all signal!", tu.pitchInHz());
case Tuner tu -> "Guitar is already in tune.";
case null, default -> String.format("Unknown or empty effect active: %s.", effect);
};
}
Here, the guard makes sure that intricate boolean logic can still be expressed in a concise way. Having to nest if statements to test this logic within a case branch would not only be more verbose, but also potentially introduce subtle bugs that we set out to avoid in the first place.
What's Different From Java 19?
A few changes were made to this feature compared to Java 19:
- When a pattern match fails abruptly, a
MatchExceptionis now thrown. - Inference of type arguments for record patterns is now supported in switch expressions and statements. This means that you can now use
varin the patterns you want to match.
More Information
For more information on this feature, see JEP 433.
JEP 432: Record Patterns (Second Preview)
Pattern matching is a feature in Java that is being rolled out gradually over multiple Java versions. Being able to deconstruct an object using patterns was always one of the ultimate goals of the feature arc. With the introduction of record patterns, deconstructing records is now possible, along with nesting record and type patterns to enable a powerful, declarative, and composable form of data navigation and processing.
Records are transparent carriers for data. Code that receives an instance of a record will typically extract the data, known as the components. This was also the case in our 'Pattern Matching for switch' code example, if we assume that all implementations of the Effect interface were in fact records there. In that piece of code it is clear that the pattern variables only serve to access the record fields. Using record patterns we can avoid having to create pattern variables altogether:
static String apply(Effect effect) {
return switch(effect) {
case Delay(int timeInMs) -> String.format("Delay active of %d ms.", timeInMs);
case Reverb(String name, int roomSize) -> String.format("Reverb active of type %s and roomSize %d.", name, roomSize);
case Overdrive(int gain) -> String.format("Overdrive active with gain %d.", gain);
case Tremolo(int depth, int rate) -> String.format("Tremolo active with depth %d and rate %d.", depth, rate);
case Tuner(int pitchInHz) -> String.format("Tuner active with pitch %d. Muting all signal!", pitchInHz);
case null, default -> String.format("Unknown or empty effect active: %s.", effect);
};
}
Delay(int timeInMs) is a record pattern here, deconstructing the Delay instance into its components. And this mechanism can become even more powerful when we apply it to a more complicated object graph by using nested record patterns:
record Tuner(int pitchInHz, Note note) implements Effect {}
record Note(String note) {}
class TunerApplier {
static String apply(Effect effect, Guitar guitar) {
return switch(effect) {
case Tuner(int pitch, Note(String note)) -> String.format("Tuner active with pitch %d on note %s", pitch, note);
};
}
}
Inference of type arguments
Nested record patterns also benefit from inference of type arguments. For example:
class TunerApplier {
static String apply(Effect effect, Guitar guitar) {
return switch(effect) {
case Tuner(var pitch, Note(var note)) -> String.format("Tuner active with pitch %d on note %s", pitch, note);
};
}
}
Here the type arguments for the nested pattern Tuner(var pitch, Note(var note)) are inferred. This only works with nested patterns for now; type patterns do not yet support implicit inference of type arguments. So the type pattern Tuner tu is always treated as a raw type pattern.
Enhanced for statements
Record patterns are now also allowed in enhanced for statements, making it easy to loop over a collection of record values and swiftly extract the components of each record:
record Delay(int timeInMs) implements Effect {}
class DelayPrinter {
static void printDelays(List<Delay> delays) {
for (Delay(var timeInMs) : delays) {
System.out.println("Delay found with timeInMs=" + timeInMs);
}
}
}
What's Different From Java 19?
The following changes were made to this feature compared to Java 19:
- Add support for inference of type arguments of generic record patterns;
- Add support for record patterns to appear in the header of an enhanced for statement.
More Information
For more information on this feature, see JEP 432.
From Project Loom
Java 20 contains three features that originated from Project Loom:
- Virtual Threads;
- Scoped Values;
- Structured Concurrency.
Project Loom strives to simplify maintaining concurrent applications in Java by introducing virtual threads and an API for structured concurrency, among other things.
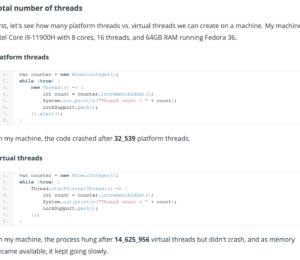
JEP 436: Virtual Threads (Second Preview)
Threads have been a part of Java since the very beginning, and since the start of Project Loom we've gradually started calling them 'platform threads' instead. A platform thread runs Java code on an underlying OS thread and captures the OS thread for the code's entire lifetime. The number of platform threads is therefore limited to the number of available OS threads.
Modern applications, however, might need many more threads than that; when dealing with tens of thousands of requests at the same time, for example. This is where virtual threads come in. A virtual thread is an instance of java.lang.Thread that runs Java code on an underlying OS thread, but does not capture the OS thread for the code's entire lifetime. This means that many virtual threads can run their Java code on the same OS thread, effectively sharing it. The number of virtual threads can thus be much larger than the number of available OS threads.
Aside from being plentiful, virtual threads are also cheap to create and dispose of. This means that a web framework, for example, can dedicate a new virtual thread to the task of handling a request and still be able to process thousands or even millions of requests at once.
Typical Use Cases
Using virtual threads does not require learning new concepts, though it may require unlearning habits developed to cope with today's high cost of threads. Virtual threads will not only help application developers; they will also help framework designers provide easy-to-use APIs that are compatible with the platform's design without compromising on scalability.
Creating Virtual Threads
Just like a platform thread, a virtual thread is an instance of java.lang.Thread. So you can use a virtual thread in exactly the same way as a platform thread.
Creating a virtual thread is a bit different, but just as easy as creating a platform thread:
var platformThread = new Thread(() -> {
// do some work in a platform thread
});
platformThread.start();
var virtualThread = Thread.startVirtualThread(() -> {
// do some work in a virtual thread
});
virtualThread.start();
When your code uses the ExecutorService interface already, switching to virtual threads will take even less effort:
var platformThreadsExecutor = Executors.newCachedThreadPool();
platformThreadsExecutor.submit(() -> {
// do some work in a platform thread
});
platformThreadsExecutor.close();
try (var virtualThreadsExecutor = Executors.newVirtualThreadPerTaskExecutor()) {
virtualThreadsExecutor.submit(() -> {
// do some work in a virtual thread
});
} // close() is called implicitly
Note that the ExecutorService interface was adjusted in Java 19 to extend AutoCloseable, so it can now be used in a try-with-resources construct.
What's Different From Java 19?
The feature is in the 'second preview' stage, to allow for more feedback. On top of that, a few API changes were made permanent and as a result are not proposed for preview any longer. This is because they involve functionality that is useful in general and is not specific to virtual threads, including:
- new methods in
Threadclass:join(Duration);sleep(Duration);threadId().
- new methods in
Future(to examine task state and result) - the change to make
ExecutorServiceextendAutoCloseable, so that it can be used in a try-with-resources block.
On top of that, the degradations to ThreadGroup were also made permanent.
More Information
For more information on this feature, see JEP 436.
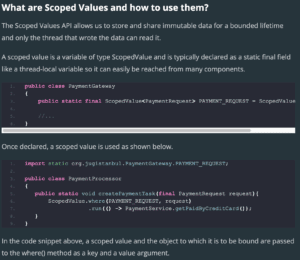
JEP 429: Scoped Values (Incubator)
Scoped values enable the sharing of immutable data within and across threads.
They are preferred to thread-local variables, especially when using large numbers of virtual threads.
ThreadLocal
Since Java 1.2 we can make use of ThreadLocal variables, which confine a certain value to the thread that created it. In some cases that can be a simple way to achieve thread-safety.
But thread-local variables also come with a few caveats. Every thread-local variable is mutable, which makes it hard to discern which component updates shared state and in what order. There's also the risk of memory leaks, because unless you call remove() on the ThreadLocal the data is retained until it is garbage collected (which is only after the thread has terminated). And finally, thread-local variables of a parent thread can be inherited by child threads, which results in the child thread having to allocate storage for every thread-local variable previously written in the parent thread.
These drawbacks become more apparent now that virtual threads have been introduced, because millions of them could be active at the same time - each with their own thread-local variables - which would result in a significant memory footprint.
Scoped Values
Like a thread-local variable, a scoped value has multiple incarnations, one per thread. Unlike a thread-local variable, a scoped value is written once and is then immutable, and is available only for a bounded period during execution of the thread.
The JEP illustrates the use of scoped values with the pseudo code example below:
final static ScopedValue<...> V = ScopedValue.newInstance();
// In some method
ScopedValue.where(V, <value>)
.run(() -> { ... V.get() ... call methods ... });
// In a method called directly or indirectly from the lambda expression
... V.get() ...
We see that ScopedValue.where(...) is called, presenting a scoped value and the object to which it is to be bound. The call to run(...) binds the scoped value, providing an incarnation that is specific to the current thread, and then executes the lambda expression passed as argument. During the lifetime of the run(...) call, the lambda expression, or any method called directly or indirectly from that expression, can read the scoped value via the value’s get() method. After the run(...) method finishes, the binding is destroyed.
Typical Use Cases
Scoped values will be useful in all places where currently thread-local variables are used for the purpose of one-way transmission of unchanging data.
What's Different From Java 19?
Java 19 didn't contain anything related to scoped values yet, so Java 20 is the first time we get to experiment with them. Note that the JEP is in the incubator stage, so you'll need to add --enable-preview --add-modules jdk.incubator.concurrent to the command-line to be able to take the feature for a spin.
More Information
For more information on this feature, see JEP 429.
JEP 437: Structured Concurrency (Second Incubator)
Java's current implementation of concurrency is unstructured, which can make error handling and cancellation with multiple tasks a challenge. When multiple tasks are started up asynchronously, we currently aren't able to cancel the remaining tasks once the first task returns an error.
Let's illustrate this point with a code example from the JEP:
Response handle() throws ExecutionException, InterruptedException {
Future<String> user = executor.submit(() -> findUser());
Future<Integer> order = executor.submit(() -> fetchOrder());
String theUser = user.get(); // Join findUser
int theOrder = order.get(); // Join fetchOrder
return new Response(theUser, theOrder);
}
When the user.get() call results in an error, there is no way for us to cancel the second task when we want to prevent getting a result that won't be used anyway.
Though when we would rewrite this code to use just a single thread, the situation would become a lot simpler:
Response handle() throws IOException {
String theUser = findUser();
int theOrder = fetchOrder();
return new Response(theUser, theOrder);
}
See? Here we would be able to prevent the second call once the first one has failed.
In general, multithreaded programming in Java would be easier, more reliable, and more observable if the parent-child relationships between tasks and their subtasks were expressed syntactically — just as for single-threaded code. The syntactic structure would delineate the lifetimes of subtasks and enable a runtime representation of the inter-thread hierarchy, enabling error propagation and cancellation as well as meaningful observation of the concurrent program.
Enter structured concurrency. We've now rewritten the code example to make use of the new StructuredTaskScope API:
Response handle() throws ExecutionException, InterruptedException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Future<String> user = scope.fork(() -> findUser());
Future<Integer> order = scope.fork(() -> fetchOrder());
scope.join(); // Join both forks
scope.throwIfFailed(); // ... and propagate errors
// Here, both forks have succeeded, so compose their results
return new Response(user.resultNow(), order.resultNow());
}
}
In structured concurrency, subtasks work on behalf of a task. The task awaits the subtasks' results and monitors them for failures. The StructuredTaskScope class allows developers to structure a task as a family of concurrent subtasks, and to coordinate them as a unit. Subtasks are executed in their own threads by forking them individually and then joining them as a unit and, possibly, cancelling them as a unit. The subtasks' successful results or exceptions are aggregated and handled by the parent task.
In contrast to the original example, understanding the lifetimes of the threads involved here is easy. Under all conditions their lifetimes are confined to a lexical scope, namely the body of the try-with-resources statement. Furthermore, the use of StructuredTaskScope ensures a number of valuable properties:
- Error handling with short-circuiting. If one of the subtasks fail, the other is cancelled if it has not yet completed. This is managed by the cancellation policy implemented by
ShutdownOnFailure; other policies likeShutdownOnSuccessare also available. - Cancellation propagation. If the thread running
handle()is interrupted before or during the call tojoin(), both forks are cancelled automatically when the thread exits the scope. - Clarity — The above code has a clear structure: Set up the subtasks, wait for them to either complete or be cancelled, and then decide whether to succeed (and process the results of the child tasks, which are already finished) or fail (and the subtasks are already finished, so there is nothing more to clean up).
By the way: it is by no means coincidental that structured concurrency is coming to Java at the same time as virtual threads. Modern Java programs will likely use an abundance of threads, and they need to be correctly and robustly coordinated. Structured concurrency can provide exactly that, while also enabling observability tools to display threads as they are understood by the developer.
What's Different From Java 19?
The situation is roughly the same as how it was in Java 19 (see JEP 428).
The only change is an update to StructuredTaskScope to make it support the inheritance of scoped values by threads created in a task scope. This streamlines the sharing of immutable data across threads. Again, note that the JEP is in the incubator stage, so you'll need to add --enable-preview --add-modules jdk.incubator.concurrent to the command-line to be able to take the feature for a spin.
More Information
For more information on this feature, see JEP 437.
From Project Panama
Java 20 contains two features that originated from Project Panama:
- Foreign Function & Memory API;
- Vector API.
Project Panama aims to improve the connection between the JVM and foreign (non-Java) libraries.
JEP 434: Foreign Function & Memory API (Second Preview)
Java programs have always had the option of interacting with code and data outside of the Java runtime.
We could use the Java Native Interface (JNI) to invoking foreign functions (outside of the JVM but on the same machine).
And accessing foreign memory (outside of the JVM, so off-heap) was possible using either the ByteBuffer API or the sun.misc.Unsafe API.
However, these three mechanisms all come with their own drawbacks, which is why a more modern API is now proposed to support foreign functions and foreign memory in a better way.
Performance-critical libraries like Tensorflow, Lucene or Netty typically rely on using foreign memory, because they need more control over the memory they use to prevent the cost and unpredictability that comes with garbage collection.
Code Example
In order to demonstrate the new API, JEP 434 lists a code example that obtains a method handle for a C library function radixsort and then uses it to sort four strings that start out as Java array elements:
// 1. Find foreign function on the C library path
Linker linker = Linker.nativeLinker();
SymbolLookup stdlib = linker.defaultLookup();
MethodHandle radixsort = linker.downcallHandle(stdlib.find("radixsort"), ...);
// 2. Allocate on-heap memory to store four strings
String[] javaStrings = { "mouse", "cat", "dog", "car" };
// 3. Use try-with-resources to manage the lifetime of off-heap memory
try (Arena offHeap = Arena.openConfined()) {
// 4. Allocate a region of off-heap memory to store four pointers
MemorySegment pointers = offHeap.allocateArray(ValueLayout.ADDRESS, javaStrings.length);
// 5. Copy the strings from on-heap to off-heap
for (int i = 0; i < javaStrings.length; i++) {
MemorySegment cString = offHeap.allocateUtf8String(javaStrings[i]);
pointers.setAtIndex(ValueLayout.ADDRESS, i, cString);
}
// 6. Sort the off-heap data by calling the foreign function
radixsort.invoke(pointers, javaStrings.length, MemorySegment.NULL, '\0');
// 7. Copy the (reordered) strings from off-heap to on-heap
for (int i = 0; i < javaStrings.length; i++) {
MemorySegment cString = pointers.getAtIndex(ValueLayout.ADDRESS, i);
javaStrings[i] = cString.getUtf8String(0);
}
} // 8. All off-heap memory is deallocated here
assert Arrays.equals(javaStrings, new String[] {"car", "cat", "dog", "mouse"}); // true
Let's look at some of the types this code uses in more detail to get a rough idea of their function and purpose within the Foreign Function & Memory API:
Linker: Provides access to foreign functions from Java code, and access to Java code from foreign functions. It allows Java code to link against foreign functions, via downcall method handles. It also allows foreign functions to call Java method handles, via the generation of upcall stubs. See the JavaDoc of this type for more information.
SymbolLookup: Retrieves the address of a symbol in one or more libraries. See the JavaDoc of this type for more information.
Arena: Controls the lifecycle of memory segments. An arena has a scope, called the arena scope. When the arena is closed, the arena scope is no longer alive. As a result, all the segments associated with the arena scope are invalidated, their backing memory regions are deallocated (where applicable) and can no longer be accessed after the arena is closed. See the JavaDoc of this type for more information.
MemorySegment: Provides access to a contiguous region of memory. There are two kinds of memory segments: heap segments (inside the Java memory heap) and native segments (outside of the Java memory heap). See the JavaDoc of this type for more information.
ValueLayout: Models values of basic data types, such as integral values, floating-point values and address values. On top of that, it defines useful value layout constants for Java primitive types and addresses. See the JavaDoc of this type for more information.
What's Different From Java 19?
In Java 19, this feature was in its first preview status (in the form of JEP 424), so the language feature was complete and developer feedback was gathered. Based on this feedback the following changes happened to Java 20:
- The
MemorySegmentandMemoryAddressabstractions were unified (memory addresses are now modeled by zero-length memory segments); - The sealed
MemoryLayouthierarchy was enhanced to facilitate usage with pattern matching for switch; MemorySessionhas been split intoArenaandSegmentScopeto facilitate sharing segments across maintenance boundaries.
More Information
For more information on this feature, see JEP 434.
JEP 438: Vector API (Fifth Incubator)
The Vector API will make it possible to express vector computations that reliably compile at runtime to optimal vector instructions.
This means that these computations will significantly outperform equivalent scalar computations on the supported CPU architectures (x64 and AArch64).
Vector Computations? Help Me Out Here!
A vector computation is a mathematical operation on one or more one-dimensional matrices of an arbitrary length. Think of a vector as an array with a dynamic length. Furthermore, the elements in the vector can be accessed in constant time via indices, just like with an array.
In the past, Java programmers could only program such computations at the assembly-code level. But now that modern CPUs support advanced SIMD features (Single Instruction, Multiple Data), it becomes more important to take advantage of the performance gains that SIMD instructions and multiple lanes operating in parallel can bring. The Vector API brings that possibility closer to the Java programmer.
Code Example
Here is a code example (taken from the JEP) that compares a simple scalar computation over elements of arrays with its equivalent using the Vector API:
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va)
.add(vb.mul(vb))
.neg();
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
From the perspective of the Java developer, this is just another way of expressing scalar computations. It might come across as being slightly more verbose, but on the other hand it can bring spectacular performance gains.
Typical Use Cases
The Vector API provides a way to write complex vector algorithms in Java that perform extremely well, such as vectorized hashCode implementations or specialized array comparisons. Numerous domains can benefit from this, including machine learning, linear algebra, encryption, text processing, finance, and code within the JDK itself.
What's Different From Java 19?
Aside from a small set of bug fixes and performance enhancements, the alignment of this feature with Project Valhalla is the biggest difference with Java 19. And it's one that makes a lot of sense, as both the Vector API and Project Valhalla focus on performance improvements.
Recall that Project Valhalla's aim is to augment the Java object model with value objects and user-defined primitives, combining the abstractions of object-oriented programming with the performance characteristics of simple primitives.
Once the features of Project Valhalla are available, the Vector API will be adapted to make use of value objects and by that time it will be promoted to a preview feature.
More Information
For more information on this feature, see JEP 438.
Final thoughts
So, these are exciting times for Java programmers!
The language is evolving at a fast pace, and new features are being published alongside each other in a coordinated way.
On top of that, they tend to be more focused on making the best use of modern hardware, which gives Java a very good chance of remaining relevant in this day and age.
So what are you still waiting for?
Take Java 20 for a spin!
- March 21, 2023
- 15 min read
Hanno Embregts is a Java Developer with a passion for learning, teaching and making music. In his day-to-day job as a Teacher / Technology Advocate at Info Support, Hanno prefers work that is fast-paced and versatile. This is why he juggles Java development, software architecture, public speaking, leading Info Support’s Speaker Community and teaching courses at Info Support’s Knowledge Centre. Hanno is a Java Champion, an Oracle ACE Pro and one of the leaders of the NLJUG (the Dutch Java User Group). Outside of work Hanno likes making music with his friends. He plays the flute, the guitar and he likes to sing. Software conferences are Hanno’s favourite thing in the world, because they allow him to do the three things he loves most at the same time: learning new things, teaching others about stuff he discovered and yes: even making music from time to time!












Comments (0)
No comments yet. Be the first.